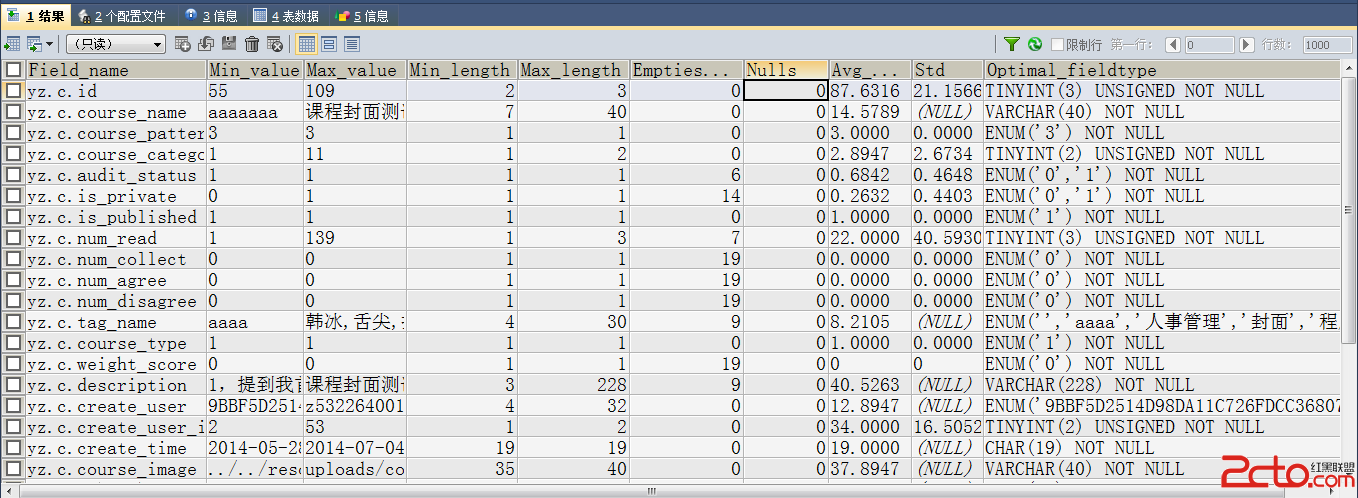
由於業務需要統計一批數據,用到關於mysql的時間操作函數和存儲過程,問題已經基本解決,把過程記錄下:
1. mysql的語句中不支持直接用循環,循環只能在存儲過程中使用;
2. 寫為文件時,注意一些隱藏的字符,造成語法錯誤。本例中注釋中包含一些不可見字符,沒有找到。
3. 存儲過程中盡量多使用分好,分割開語句。本例中 drop一句最初沒有寫,導致一直有錯。
4. 時間函數很強大,可以避免一些工作。http://www.cnblogs.com/ggjucheng/p/3352280.html
5. sql語句的優化很重要,本例中僅解決了問題,但數據量太大,存儲過程運行了很久。期待有人能幫忙優化while語句中的優化。
下面貼代碼了:
--*將表test.transport20140901表中的數據按照每五分鐘一個間隔,統計各個路口的車流數量r
--*@start_time 起始時間 是整點時間的五分鐘間隔 如 2014-09-01 00:20:00
--*@end_time 終止時間 是整點的五分鐘間隔且大於start_time 如 2014-09-01 01:00:00
--*統計范圍包含起始時間,但不包含終止時間
delimiter $
drop procedure transport_status;
create procedure transport_status(start_time datetime,end_time datetime)
begin
declare mid_start_time datetime;
declare mid_end_time datetime;
set mid_start_time=start_time;
set mid_end_time=date_add(start_time, interval 5 minute);
lab: while mid_start_time < end_time do
insert into
test.transport_status(stamp,stamp_time,address,car_count)
(select
FLOOR(UNIX_TIMESTAMP(time)/300) as stmp,
date_format(mid_end_time,'%Y-%m-%d %H:%i:%s') as tm,
address,
count(address) as cnt
from
test.transport20140901
where
time > date_add(mid_start_time, interval -1 second)
and time < mid_end_time
group by address);
set mid_start_time=date_add(mid_start_time, interval 5 minute);
set mid_end_time=date_add(mid_end_time, interval 5 minute);
end while lab;
end $
delimiter ;
call transport_status("2014-09-01 00:00:00","2014-09-2 00:00:00");