一般來說,簡單的水平切分主要是將某個訪問極其平凡的表再按照某個字段的某種規則來分散到多個表之中,每個表中包含一部分數據。
簡單來說,我們可以將數據的水平切分理解為是按照數據行的切分,就是將表中的某些
行切分到一個數據庫,而另外的某些行又切分到其他的數據庫中。當然,為了能夠比較容易
的判定各行數據被切分到哪個數據庫中了,切分總是都需要按照某種特定的規則來進行的。
如根據某個數字類型字段基於特定數目取模,某個時間類型字段的范圍,或者是某個字符類
型字段的hash 值。如果整個系統中大部分核心表都可以通過某個字段來進行關聯,那這個
字段自然是一個進行水平分區的上上之選了,當然,非常特殊無法使用就只能另選其他了。
水平拆分的優點:
◆表關聯基本能夠在數據庫端全部完成;
◆不會存在某些超大型數據量和高負載的表遇到瓶頸的問題;
◆應用程序端整體架構改動相對較少;
◆事務處理相對簡單;
◆只要切分規則能夠定義好,基本上較難遇到擴展性限制;
水平切分的缺點:
◆切分規則相對更為復雜,很難抽象出一個能夠滿足整個數據庫的切分規則;
◆後期數據的維護難度有所增加,人為手工定位數據更困難;
◆應用系統各模塊耦合度較高,可能會對後面數據的遷移拆分造成一定的困難。
<版權所有,文章允許轉載,但必須以鏈接方式注明源地址,否則追究法律責任!>
原博客地址: http://blog.csdn.net/mchdba/article/details/46278687
原作者:黃杉 (mchdba)
一般來說,像現在互聯網非常火爆的互聯網公司,特別是電商和游戲業務,基本上大部分數據都能夠通
過會員用戶信息關聯上,可能很多核心表都非常適合通過會員ID 來進行數據的水平切分。
而像論壇社區討論系統,就更容易切分了,非常容易按照論壇編號來進行數據的水平切分。
切分之後基本上不會出現各個庫之間的交互。
所以,對於我們的示例數據庫來說,大部分的表都可以根據用戶ID 來進行水平的切分。
不同用戶相關的數據進行切分之後存放在不同的數據庫中。如將所有用戶ID 通過5取模
然後分別存放於兩個不同的數據庫中。每個和用戶ID 關聯上的表都可以這樣切分。這樣,
基本上每個用戶相關的數據,都在同一個數據庫中,即使是需要關聯,也可以非常簡單的關
聯上。
比如全國劃分為10大片區,江浙滬算一哥,齊魯算一個,兩廣算一個,兩湖算一個,中原算一個,西南算一個,內蒙一個,東北一個,西北一個,華北一個,東南一個。
在業務量比較大的華北、東南、江浙滬、兩廣片區的服務器可以分配較多的服務器資源,比如cpu、io、網絡等等可以用比較好的高端配置。
在業務量正常的西北、齊魯、兩湖、東北的服務器可以分配中高端的服務器資源。
在業務量比較少的,西南、內蒙、中原的服務器可以稍微一般服務器即可。
當然這些資源劃分不能對外明示,我們在做內部規劃的時候考慮好就可以了,免得被人诟病說有所偏頗不重視之類的。
PS:這種劃分不是定性的,根據業務可以隨時將業務好的片區的資源升級。
如下圖所示:


在實施數據切分方案之前,有些可能存在的問題我們還是需要做一些分析的。一般來說,
我們可能遇到的問題主要會有以下幾點:
◆引入分布式事務的問題;
◆跨節點Join 的問題;
◆跨節點合並排序分頁問題;
一旦數據進行切分被分別存放在多個MySQL Server 中之後,不管我們的切分規則設計
的多麼的完美(實際上並不存在完美的切分規則),都可能造成之前的某些事務所涉及到的
數據已經不在同一個MySQL Server 中了。
在這樣的場景下,如果我們的應用程序仍然按照老的解決方案,那麼勢必需要引入分布
式事務來解決。而在MySQL 各個版本中,只有從MySQL 5.0 開始以後的各個版本才開始對
分布式事務提供支持,而且目前僅有Innodb 提供分布式事務支持。不僅如此,即使我們剛
好使用了支持分布式事務的MySQL 版本,同時也是使用的Innodb 存儲引擎,分布式事務
本身對於系統資源的消耗就是很大的,性能本身也並不是太高。而且引入分布式事務本身在
異常處理方面就會帶來較多比較難控制的因素。
怎麼辦?其實我們可以可以通過一個變通的方法來解決這種問題,首先需要考慮的一件
事情就是:是否數據庫是唯一一個能夠解決事務的地方呢?其實並不是這樣的,我們完全可
以結合數據庫以及應用程序兩者來共同解決。各個數據庫解決自己身上的事務,然後通過應
用程序來控制多個數據庫上面的事務。
也就是說,只要我們願意,完全可以將一個跨多個數據庫的分布式事務分拆成多個僅處
於單個數據庫上面的小事務,並通過應用程序來總控各個小事務。當然,這樣作的要求就是
我們的俄應用程序必須要有足夠的健壯性,當然也會給應用程序帶來一些技術難度。
上面介紹了可能引入分布式事務的問題,現在我們再看看需要跨節點Join 的問題。數
據切分之後,可能會造成有些老的Join 語句無法繼續使用,因為Join 使用的數據源可能
被切分到多個MySQL Server 中了。
怎麼辦?這個問題從MySQL 數據庫角度來看,如果非得在數據庫端來直接解決的話,
恐怕只能通過MySQL 一種特殊的存儲引擎Federated 來解決了。Federated 存儲引擎是
MySQL 解決類似於Oracle 的DB Link 之類問題的解決方案。和OracleDB Link 的主要
區別在於Federated 會保存一份遠端表結構的定義信息在本地。咋一看,Federated 確實
是解決跨節點Join 非常好的解決方案。但是我們還應該清楚一點,那就似乎如果遠端的表
結構發生了變更,本地的表定義信息是不會跟著發生相應變化的。如果在更新遠端表結構的
時候並沒有更新本地的Federated 表定義信息,就很可能造成Query 運行出錯,無法得到
正確的結果。
對待這類問題,我還是推薦通過應用程序來進行處理,先在驅動表所在的MySQL Server
中取出相應的驅動結果集,然後根據驅動結果集再到被驅動表所在的MySQL Server 中取出
相應的數據。可能很多讀者朋友會認為這樣做對性能會產生一定的影響,是的,確實是會對
性能有一定的負面影響,但是除了此法,基本上沒有太多其他更好的解決辦法了。而且,由
於數據庫通過較好的擴展之後,每台MySQL Server 的負載就可以得到較好的控制,單純針
對單條Query 來說,其響應時間可能比不切分之前要提高一些,所以性能方面所帶來的負
面影響也並不是太大。更何況,類似於這種需要跨節點Join 的需求也並不是太多,相對於
總體性能而言,可能也只是很小一部分而已。所以為了整體性能的考慮,偶爾犧牲那麼一點
點,其實是值得的,畢竟系統優化本身就是存在很多取捨和平衡的過程。
一旦進行了數據的水平切分之後,可能就並不僅僅只有跨節點Join 無法正常運行,有
些排序分頁的Query 語句的數據源可能也會被切分到多個節點,這樣造成的直接後果就是
這些排序分頁Query 無法繼續正常運行。其實這和跨節點Join 是一個道理,數據源存在
於多個節點上,要通過一個Query 來解決,就和跨節點Join 是一樣的操作。同樣
Federated 也可以部分解決,當然存在的風險也一樣。
還是同樣的問題,怎麼辦?我同樣仍然繼續建議通過應用程序來解決。
如何解決?解決的思路大體上和跨節點Join 的解決類似,但是有一點和跨節點Join
不太一樣,Join 很多時候都有一個驅動與被驅動的關系,所以Join 本身涉及到的多個表
之間的數據讀取一般都會存在一個順序關系。但是排序分頁就不太一樣了,排序分頁的數據
源基本上可以說是一個表(或者一個結果集),本身並不存在一個順序關系,所以在從多個
數據源取數據的過程是完全可以並行的。這樣,排序分頁數據的取數效率我們可以做的比跨
庫Join 更高,所以帶來的性能損失相對的要更小,在有些情況下可能比在原來未進行數據
切分的數據庫中效率更高了。當然,不論是跨節點Join 還是跨節點排序分頁,都會使我們
的應用服務器消耗更多的資源,尤其是內存資源,因為我們在讀取訪問以及合並結果集的這
個過程需要比原來處理更多的數據。
分析到這裡,可能很多朋友會發現,上面所有的這些問題,我給出的建議基本上都是通過應用程序來解決。大家可能心裡開始犯嘀咕了,是不是因為我是DBA,所以就很多事情都扔給應用架構師和開發人員了?
其實完全不是這樣,首先應用程序由於其特殊性,可以非常容易做到很好的擴展性,但
是數據庫就不一樣,必須借助很多其他的方式才能做到擴展,而且在這個擴展過程中,很難
避免帶來有些原來在集中式數據庫中可以解決但被切分開成一個數據庫集群之後就成為一
個難題的情況。要想讓系統整體得到最大限度的擴展,我們只能讓應用程序做更多的事情,
來解決數據庫集群無法較好解決的問題。
通過數據切分技術將一個大的MySQL Server 切分成多個小的MySQL Server,既解決
了寫入性能瓶頸問題,同時也再一次提升了整個數據庫集群的擴展性。不論是通過垂直切分,
還是水平切分,都能夠讓系統遇到瓶頸的可能性更小。尤其是當我們使用垂直和水平相結合
的切分方法之後,理論上將不會再遇到擴展瓶頸了。
創建多實例參加:http://blog.csdn.net/mchdba/article/details/45798139
創建庫表
create database `hwdb` /*!40100 default characterset utf8 */;
create table uc_user(user_id bigint primarykey, uc_name varchar(200), created_time datetime) engine=innodb charset utf8;
創建用戶
grant insert,update,delete,select on hwdb.*to tim@'192.168.%' identified by 'timgood2013';
執行過程:
mysql> create table uc_user(user_idbigint primary key, uc_name varchar(200), created_time datetime) engine=innodbcharset utf8;
Query OK, 0 rows affected (0.53 sec)
mysql>
mysql> grant insert,update,delete,selecton hwdb.* to tim@'192.168.%' identified by 'timgood2013';
Query OK, 0 rows affected (0.03 sec)
mysql>
6.3 創建java代碼示例
package mysql;
import java.math.BigInteger;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Calendar;
public classMySQLTest {
public static void main(String[] args) {
MySQLTestmt=newMySQLTest();
//
BigIntegerbi = newBigInteger("2015053010401005");
Stringport=mt.getDBPort(bi.longValue());
Connection conn=mt.getConn(port);
mt.insert(conn,bi, "tim--"+bi.longValue());
}
// 獲取要訪問的db端口
public String getDBPort(long user_id){
Stringport="3307";
long v_cast=user_id%3;
if (v_cast==1 ){
port="3308";
}else if(v_cast==2){
port="3309";
}else {
port="3307";
}
return port;
}
// 獲取數據庫的連接,如果擴展的話,可以單獨做一個接口提供給程序員來調用它
public ConnectiongetConn(String port ) {
Connectionconn = null;
try {
Class.forName("com.mysql.jdbc.Driver");
}catch(ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Stringurl = "jdbc:mysql://192.168.52.130:"+port+"/hwdb";
try {
conn= DriverManager.getConnection(url, "tim", "timgood2013");
}catch(SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("the current db is :"+url);
return conn;
}
// 獲取日期字符串
public StringgetTimeByCalendar(){
Calendar cal = Calendar.getInstance();
int year = cal.get(Calendar.YEAR);//獲取年份
int month=cal.get(Calendar.MONTH);//獲取月份
int day=cal.get(Calendar.DATE);//獲取日
int hour=cal.get(Calendar.HOUR);//小時
int minute=cal.get(Calendar.MINUTE);//分
int second=cal.get(Calendar.SECOND);//秒
String strdate=year+"-"+month+"-"+day+" "+hour+":"+minute+":"+second;
return strdate;
}
// 開始錄入數據
public int insert(Connectioncnn,BigInteger user_id,String name){
Stringsql="insert intohwdb.uc_user(user_id,uc_name,created_time)values(?,?,?)";
int i=0;
long uid =user_id.longValue();
Connectionconn=cnn;
try{
PreparedStatement preStmt=conn.prepareStatement(sql);
preStmt.setLong(1, uid);
preStmt.setString(2,name);
preStmt.setString(3,getTimeByCalendar());
i=preStmt.executeUpdate();
}
catch (SQLException e)
{
e.printStackTrace();
}
return i;//返回影響的行數,1為執行成功
}
}
6.4 測試代碼User_id按照注冊年月日時分秒+9999,這樣的思路是,一秒滿足9999個並發,也不會,至於如何統一規劃這全局的9999個,可以設置一個靜態的全局變量,而且這個全局變量會及時保存到某個DB中,這樣基本保證了不重復,比如user_id:2015053010401005、2015053010401006、2015053010401007,測試代碼如下:
MySQLTestmt=newMySQLTest();
//
BigIntegerbi = newBigInteger("2015053010401005");
Stringport=mt.getDBPort(bi.longValue());
Connection conn=mt.getConn(port);
mt.insert(conn,bi, "tim--"+bi.longValue());
1)通過%3來獲取DB連接;
余0 --> db1(3307端口)
余1 --> db2(3308端口)
余2 --> db3(3309端口)
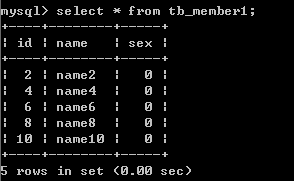
2)查看結果運行結束後,可以去3個實例相應的查看錄入的數據,如下所示:
Id為2015053010401005應該錄入到db1(3307端口)
[root@data02 ~]# mysql--socket=/usr/local/mysql3307/mysql.sock -e "select * fromhwdb.uc_user;";
+------------------+-----------------------+---------------------+
| user_id | uc_name | created_time |
+------------------+-----------------------+---------------------+
| 2015053010401005 | tim--2015053010401005 |2015-04-30 09:27:48 |
+------------------+-----------------------+---------------------+
[root@data02 ~]#
Id為2015053010401006應該錄入到db2(3308端口)
[root@data02 ~]# mysql--socket=/usr/local/mysql3308/mysql.sock -e "select * fromhwdb.uc_user;";
+------------------+-----------------------+---------------------+
| user_id | uc_name | created_time |
+------------------+-----------------------+---------------------+
| 2015053010401006 | tim--2015053010401006 |2015-04-30 09:27:57 |
+------------------+-----------------------+---------------------+
[root@data02 ~]#
Id為2015053010401007應該錄入到db3(3309端口)
[root@data02 ~]# mysql--socket=/usr/local/mysql3309/mysql.sock -e "select * fromhwdb.uc_user;";
+------------------+-----------------------+---------------------+
| user_id | uc_name | created_time |
+------------------+-----------------------+---------------------+
| 2015053010401007 | tim--2015053010401007| 2015-04-30 09:28:01 |
+------------------+-----------------------+---------------------+
[root@data02 ~]#
6.5總結基本和預想的一樣的,數據通過模id取余數的方法,水平拆分到不同的庫裡面,這裡只是簡單演示了下,實際生產的復雜程度遠比這個要高的多,所以大家遇到的問題會更多,但是水平拆分的理念都是類似的,這條路是光明的,大家可以放心走下去。