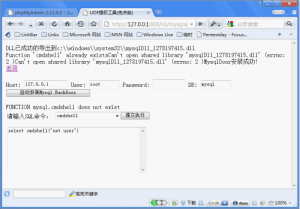
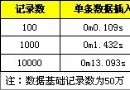
一、mysql的sql_mode模式:
(1)、該模式指的是sql模式可控制服務器操作的方式,並且sql模式存在於全局與會話級別。如果想知道全局級或會話級SQL模式的當前值,可以使用的語句為:
mysql> SELECT @@GLOBAL.sql_mode,mysql> SELECT @@SESSION.sql_mode。
(2)、如果想知道SQL模式的當前值,可以使用:SELECT @@sql_mode。
二、有的mysql使用的默認的存儲引擎為InnoDB,有的 默認的存儲引擎為MyISAM。這種兩種是最常用的。這兩種引擎有六大區別:
存儲類型: MyISAM InnoDB 構成上的區別: 1.每個MyISAM在磁盤上存儲成三個文件。第一個文件的名字以表的名字開始,擴展名指出文件類型。
提供行鎖(locking on row level),提供與 Oracle 類型一致的不加鎖讀取(non-locking read in SELECTs),另外,InnoDB表的行鎖也不是絕對的,如果在執行一個SQL語句時MySQL不能確定要掃描的范圍,InnoDB表同樣會鎖全表,例如update table set num=1 where name like “%aaa%”
三、為什麼有大量數據操作的時候要用到InnoDB數據庫?
所謂事務處理,就是原子性操作。
打個比方,支持事務處理的Innodb表,建設一個中,發帖是給積分的。你發了一個帖子執行一個insert語句,來插入帖子內容,插入後就要執行一個update語句來增加你的積分。假設一種特殊情況突然發生,insert成功了,update操作卻沒有被執行。也就是說你發了帖子卻沒有增加相應的積分。這就會造成用戶不滿。如果使用了事務處理,insert和update都放入到事務中去執行,這個時候,只有當insert和update兩條語句都執行生成的時候才會將數據更新、寫入到中,如果其中任何一條語句失敗,那麼就會回滾為初始狀態,不執行寫入。這樣就保證了insert和update肯定是一同執行的。
mysiam表不支持事務處理,同時mysiam表不支持外鍵。外鍵不用說了吧?不知道的話,去網上查吧。
同時,在執行數據庫寫入的操作(insert,update,delete)的時候,mysiam表會鎖表,而innodb表會鎖行。通俗點說,就是你執行了一個update語句,那麼mysiam表會將整個表都鎖住,其他的insert和delete、update都會被拒之門外,等到這個update語句執行完成後才會被依次執行。
而鎖行,就是說,你執行update語句是,只會將這一條記錄進行鎖定,只有針對這條記錄的其他寫入、更新操作會被阻塞並等待這條update語句執行完畢後再執行,針對其他記錄的寫入操作不會有影響。
因此,當你的數據庫有大量的寫入、更新操作而查詢比較少或者數據完整性要求比較高的時候就選擇innodb表。當你的數據庫主要以查詢為主,相比較而言更新和寫入比較少,並且業務方面數據完整性要求不那麼嚴格,就選擇mysiam表。因為mysiam表的查詢操作效率和速度都比innodb要快
四、千萬級數據量的數據大表該如何優化?
1).數據的容量:1-3年內會大概多少條數據,每條數據大概多少字節;
2).數據項:是否有大字段,那些字段的值是否經常被更新;
3).數據查詢SQL條件:哪些數據項的列名稱經常出現在WHERE、GROUP BY、ORDER BY子句中等;
4).數據更新類SQL條件:有多少列經常出現UPDATE或DELETE 的WHERE子句中;
5).SQL量的統計比,如:SELECT:UPDATE+DELETE:INSERT=多少?
6).預計大表及相關聯的SQL,每天總的執行量在何數量級?
7).表中的數據:更新為主的業務 還是 查詢為主的業務
8).打算采用什麼數據庫物理服務器,以及數據庫服務器架構?
9).並發如何?
10).存儲引擎選擇InnoDB還是MyISAM?
大致明白以上10個問題,至於如何設計此類的大表,應該什麼都清楚了!
至於優化若是指創建好的表,不能變動表結構的話,那建議InnoDB引擎,多利用點內存,減輕磁盤IO負載,因為IO往往是數據庫服務器的瓶頸,另外對優化索引結構去解決性能問題的話,建議優先考慮修改類SQL語句,使他們更快些,不得已只靠索引組織結構的方式,當然此話前提是,索引已經創建的非常好,若是讀為主,可以考慮打query_cache,以及調整一些參數值:sort_buffer_size,read_buffer_size,read_rnd_buffer_size,join_buffer_size
五、MYSQL IN 和 EXISTS的優化規則:
當B表的數據集小於A表的數據集時,用in優於exists,當A表的數據集系小於B表的數據集時,用exists優於in。
優化原則:in小表驅動大表,即小的數據集驅動大的數據集。
示例select * from A where id in(select if from B)等價於for select * from A where B 和for select * from A where A.id = B.id。
當B表的數據集必須小於A表的數據集時,用in優於exists。
select * from A where exists (select 1 from B where B.id = A.id)
當A表的數據集系小於B表的數據集時,用in優於exists。
六、mysql order by 語句用法與優化詳解:
order by keyword 是用來給記錄中的數據根據關鍵字進行分類的。
SELECT _name(s) FROM table_name ORDER BY column_name。
1).ORDER BY的索引優化。
SELECT [column1],[column2],...FROM[TABLE] ORDER BY [sort];
2).WHERE+ORDER BY的索引優化。
SELECT [column1],[column2],...FROM[TABLE] WHERE [CcolumnX] = [value] ORDER BY [sort];
建立一個聯合索引(columnX,sort)來實現order by優化。如果columnX對應多個值,就無法用上面的索引來實現order by的優化。
3).WHERE+多個字段ORDER BY
SELECT * FROM [TABLE] WHERE uid = 1 ORDER BY x,y LIMIT 0,10;
建立索引(uid,x,y)實現order by的優化,比建立(x,y,uid)索引效果要要得多。
在有些情況下,mysql可以使用一個索引來滿足order by子句,而不需要額外的排序。where 條件和order by使用相同的索引,並且order by的順序和索引順序相同,並且order by的字段都是升序或者都是降序。
select * from t1 order by key_part1,keypart2,...;
select * from t1 where key_part1 = 1order by key_part1 DESC,key_part2 DESC;
select * from t1 where order by key_part1 DESC,key_part2 DESC;
但是一下情況不適用索引:
①SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
--order by的字段混合ASC和DESC
②SELECT * FROM t1 WHERE key2=constant ORDER BY key1;
--用於查詢行的關鍵字與ORDER BY中所使用的不相同
③SELECT * FROM t1 ORDER BY key1, key2;
--對不同的關鍵字使用ORDER BY
七、InnoDB基本優化配置:
InnoDB設置
1.innodb_buffer_pool_size —— 默認值為 128M. 這是最主要的優化選項,因為它指定 InnoDB 使用多少內存來加載數據和索引(data+indexes). 針對專用MySQL服務器,建議指定為物理內存的 50-80%這個范圍. 例如,擁有64GB物理內存的機器,緩存池應該設置為50GB左右.
如果將該值設置得更大可能會存在風險,比如沒有足夠的空閒內存留給操作系統和依賴文件系統緩存的某些MySQL子系統(subsystem),包括二進制日志(binary logs),InnoDB事務日志(transaction logs)等.
2.innodb_log_file_size —— 默認值為 48M. 有很高寫入吞吐量的系統需要增加該值以允許後台檢查點活動在更長的時間周期內平滑寫入,得以改進性能. 將此值設置為4G以下是很安全的. 過去的實踐表明,日志文件太大的缺點是增加了崩潰時所需的修復時間,但這在5.5和5.6中已得到重大改進.
3.innodb_flush_method —— 默認值為 fdatasync. 如果使用 硬件RAID磁盤控制器, 可能需要設置為 O_DIRECT. 這在讀取InnoDB緩沖池時可防止“雙緩沖(double buffering)”效應,否則會在文件系統緩存與InnoDB緩存間形成2個副本(copy).
如果不使用硬件RAID控制器,或者使用SAN存儲時, O_DIRECT 可能會導致性能下降.MySQL用戶手冊 和 Bug #54306 詳細地說明了這一點.
4.innodb_flush_neighbors —— 默認值為 1. 在SSD存儲上應設置為0(禁用) ,因為使用順序IO沒有任何性能收益. 在使用RAID的某些硬件上也應該禁用此設置,因為邏輯上連續的塊在物理磁盤上並不能保證也是連續的.
5.innodb_io_capacity and innodb_io_capacity_max —— 這些設置會影響InnoDB每秒在後台執行多少操作. 如果你深度了解硬件性能(如每秒可以執行多少次IO操作),則使用這些功能是很可取的,而不是讓它閒著.
有一個很好的類比示例: 假如某次航班一張票也沒有賣出去 —— 那麼讓稍後航班的一些人乘坐該次航班,有可能是很好的策略,以防後面遇到惡劣的天氣. 即有機會就將後台操作順便處理了,以減少同稍後可能的實時操作產生競爭.
有一個很簡單的計算: 如果每個磁盤每秒讀寫(IOPS)可以達到 200次, 則擁有10個磁盤的 RAID10 磁盤陣列IOPS理論上 =(10/2)* 200 = 1000. 我說它“很簡單”,是因為RAID控制器通常能夠提供額外的合並,並有效提高IOPS能力. 對於SSD磁盤,IOPS可以輕松達到好幾千.
將這兩個值設置得太大可能會存在某些風險,你肯定不希望後台操作妨礙了前台任務IO操作的性能. 過去的經驗表明,將這兩個值設置的太高,InnoDB持有的內部鎖會導致性能降低(按我了解到的信息,在MySQL5.6中這得到了很大的改進).
innodb_lru_scan_depth - 默認值為 1024. 這是mysql 5.6中引入的一個新選項. Mark Callaghan 提供了 一些配置建議. 簡單來說,如果增大了 innodb_io_capacity 值, 應該同時增加 innodb_lru_scan_depth.
復制(Replication)
假如服務器要支持主從復制,或按時間點恢復,在這種情況下,我們需要:
1.log-bin —— 啟用二進制日志. 默認情況下二進制日志不是事故安全的(not crash safe),但如同我 以前的文章所說, 我建議大多數用戶應該以穩定性為目標. 在這種情況下,你還需要啟用: sync_binlog=1, sync_relay_log=1, relay-log-info-repository=TABLE and master-info-repository=TABLE.
2.expire-logs-days —— 默認舊日志會一直保留. 我推薦設置為 1-10 天. 保存更長的時間並沒有太多用處,因為從備份中恢復會快得多.
3.server-id —— 在一個主從復制體系(replication topology )中的所有服務器都必須設置唯一的 server-id.
4.binlog_format=ROW —— 修改為基於行的復制. 我最近寫的另一篇 基於行的復制 ,裡面敘述了我真的很喜歡它的原因,因為它可以通過減少資源鎖定提高性能. 此外還需要啟用兩個附加設置: transaction-isolation=READ-COMMITTED and innodb_autoinc_lock_mode = 2.
其他配置(Misc)
1.timezone=GMT 將時區設置為格林尼治時間. 越來越多的系統管理員建議將所有服務器都設置為 格林尼治時間(GMT). 我個人非常喜歡這點,因為現在幾乎所有的業務都是全球化的. 設置為你本地的時區似乎是有點武斷的.
2.character-set-server=utf8mb4 and collation-server=utf8mb4_general_ci 如之前的 文章所講述的 ,utf8 編碼對新應用來說是更好的默認選項. 您還可以設置 skip-character-set-client-handshake 以忽略應用程序想要設置的其他字符集(character-set).
3.sql-mode —— MySQL默認對不規范的數據很寬容,並且會靜默地截斷數據. 在我 之前的一篇文章中, 我提到新應用程序最好設置為:
STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO, NO_AUTO_CREATE_USER,NO_AUTO_VALUE_ON_ZERO, NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE, NO_ZERO_IN_DATE,ONLY_FULL_GROUP_BY.
4.skip-name-resolve —— 禁用反向域名解析. DNS解析在某些系統上可能有點慢/不穩定,所以如果不需要基於主機名的授權,我建議避免這種解析.
5.max_connect_errors —— Todd Farmer 寫道 :“[這個功能]提供了沒有實際意義的暴力訪問攻擊保護”. 事實上當設置skip-name-resolve 時, max_connect_errors 甚至不起作用(見上一段所述).
防火牆是更合適的解決方案,通常我將3306端口屏蔽,不管是公網的還是內網的端口,只有特定的應用程序可以訪問和連接到MySQL.
我通常會設置 max_connect_errors=100000, 這樣我可以避免任何“雙重配置”,保證它不會礙事.
6.max-connections ——默認值是151. 我看到很多用戶將他設置得比較大,大多在 300 ~ 1000之間.
通常不可避免地這個值會被設置得更大,但讓我有點緊張的是, 16核的機器在IO阻塞的情況下也只有大約 2x~10x 的連接執行能力.
你可能希望,許多打開的連接都是空閒並休眠的. 但如果他們都處於活躍狀態的話,可能會創建大量新的線程(thread-thrash).
如果條件允許,可以為應用程序配置優化數據庫連接池(connection-pools)來解決這個問題,而不是打開並保持大量連接;
當然那些不使用連接池(non-pooled ), 迅速打開,執行任務後又盡可能快地關閉連接的應用也是可行的.
從5.5開始的另一種解決方案(在MySQL社區版和企業版之間有一些差異) 是使用 線程池插件.
總結(Conclusion)
假設MySQL服務器的配置為:
1.64GB物理內存
2.硬件RAID控制器(假設每秒IO可達 2000 IOPS)
3.需要主從復制(Replication)
4.新的應用(eg. 非遺留系統)
5.有防火牆保護
6.不需要基於域名(hostnames,主機名)的授權
7.全球化應用,並不想固定在某一時區.
8.想要程序可靠穩定(durable).
則配置可能如下所示:
# InnoDB settings innodb_buffer_pool_size=50G innodb_log_file_size=2G innodb_flush_method=O_DIRECT innodb_io_capacity=2000 innodb_io_capacity_max=6000 innodb_lru_scan_depth=2000 # Binary log/replication log-bin sync_binlog=1 sync_relay_log=1 relay-log-info-repository=TABLE master-info-repository=TABLE expire_logs_days=10 binlog_format=ROW transaction-isolation=READ-COMMITTED innodb_autoinc_lock_mode = 2 # Other timezone=GMT character-set-server=utf8 collation-server=utf8_general_ci sql-mode="STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO, NO_AUTO_CREATE_USER, NO_AUTO_VALUE_ON_ZERO, NO_ENGINE_SUBSTITUTION, NO_ZERO_DATE, NO_ZERO_IN_DATE, ONLY_FULL_GROUP_BY" skip-name_resolve max-connect-errors=100000 max-connections=500 # Unique to this machine server-id=123