PostgreSQL與MySQL比較
特性
MySQL
PostgreSQL
實例
通過執行 MySQL 命令(mysqld)啟動實例。一個實例可以管理一個或多個數據庫。一台服務器可以運行多個 mysqld 實例。一個實例管理器可以監視 mysqld 的各個實例。
通過執行 Postmaster 進程(pg_ctl)啟動實例。一個實例可以管理一個或多個數據庫,這些數據庫組成一個集群。集群是磁盤上的一個區域,這個區域在安裝時初始化並由一個目錄組成,所有數據都存儲在這個目錄中。使用 initdb 創建第一個數據庫。一台機器上可以啟動多個實例。
數據庫
數據庫是命名的對象集合,是與實例中的其他數據庫分離的實體。一個 MySQL 實例中的所有數據庫共享同一個系統編目。
數據庫是命名的對象集合,每個數據庫是與其他數據庫分離的實體。每個數據庫有自己的系統編目,但是所有數據庫共享 pg_databases。
數據緩沖區
通過
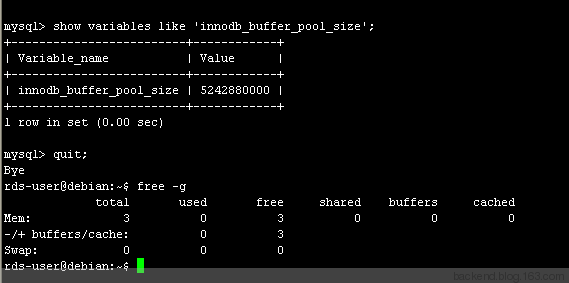
innodb_buffer_pool_size 配置參數設置數據緩沖區。這個參數是內存緩沖區的字節數,InnoDB 使用這個緩沖區來緩存表的數據和索引。在專用的數據庫服務器上,這個參數最高可以設置為機器物理內存量的 80%。
Shared_buffers 緩存。在默認情況下分配 64 個緩沖區。默認的塊大小是 8K。可以通過設置 postgresql.conf 文件中的 shared_buffers 參數來更新緩沖區緩存。
數據庫連接
客戶機使用 CONNECT 或 USE 語句連接數據庫,這時要指定數據庫名,還可以指定用戶 id 和密碼。使用角色管理數據庫中的用戶和用戶組。
客戶機使用 connect 語句連接數據庫,這時要指定數據庫名,還可以指定用戶 id 和密碼。使用角色管理數據庫中的用戶和用戶組。
身份驗證
MySQL 在數據庫級管理身份驗證。 基本只支持密碼認證。
PostgreSQL 支持豐富的認證方法:信任認證、口令認證、Kerberos 認證、基於 Ident 的認證、LDAP 認證、PAM 認證
加密
可以在表級指定密碼來對數據進行加密。還可以使用 AES_ENCRYPT 和 AES_DECRYPT 函數對列數據進行加密和解密。可以通過 SSL 連接實現網絡加密。
可以使用 pgcrypto 庫中的函數對列進行加密/解密。可以通過 SSL 連接實現網絡加密。
審計
可以對 querylog 執行 grep。
可以在表上使用 PL/pgSQL 觸發器來進行審計。
查詢解釋
使用 EXPLAIN 命令查看查詢的解釋計劃。
使用 EXPLAIN 命令查看查詢的解釋計劃。
備份、恢復和日志
InnoDB 使用寫前(write-ahead)日志記錄。支持在線和離線完全備份以及崩潰和事務恢復。需要第三方軟件才能支持熱備份。
在數據目錄的一個子目錄中維護寫前日志。支持在線和離線完全備份以及崩潰、時間點和事務恢復。 可以支持熱備份。
JDBC 驅動程序
可以從
參考資料 下載 JDBC 驅動程序。
可以從
參考資料 下載 JDBC 驅動程序。
表類型
取決於存儲引擎。例如,NDB 存儲引擎支持分區表,內存引擎支持內存表。
支持臨時表、常規表以及范圍和列表類型的分區表。不支持哈希分區表。 由於PostgreSQL的表分區是通過表繼承和規則系統完成了,所以可以實現更復雜的分區方式。
索引類型
取決於存儲引擎。MyISAM:BTREE,InnoDB:BTREE。
支持 B-樹、哈希、R-樹和 Gist 索引。
約束
支持主鍵、外鍵、惟一和非空約束。對檢查約束進行解析,但是不強制實施。
支持主鍵、外鍵、惟一、非空和檢查約束。
存儲過程和用戶定義函數
支持 CREATE PROCEDURE 和 CREATE FUNCTION 語句。存儲過程可以用 SQL 和 C++ 編寫。用戶定義函數可以用 SQL、C 和 C++ 編寫。
沒有單獨的存儲過程,都是通過函數實現的。用戶定義函數可以用 PL/pgSQL(專用的過程語言)、PL/Tcl、PL/Perl、PL/Python 、SQL 和 C 編寫。
觸發器
支持行前觸發器、行後觸發器和語句觸發器,觸發器語句用過程語言復合語句編寫。
支持行前觸發器、行後觸發器和語句觸發器,觸發器過程用 C 編寫。
系統配置文件
my.conf
Postgresql.conf
數據庫配置
my.conf
Postgresql.conf
客戶機連接文件
my.conf
pg_hba.conf
XML 支持
有限的 XML 支持。
有限的 XML 支持。
數據訪問和管理服務器
OPTIMIZE TABLE —— 回收未使用的空間並消除數據文件的碎片
myisamchk -analyze —— 更新查詢優化器所使用的統計數據(MyISAM 存儲引擎)
mysql —— 命令行工具
MySQL Administrator —— 客戶機 GUI 工具
Vacuum —— 回收未使用的空間
Analyze —— 更新查詢優化器所使用的統計數據
psql —— 命令行工具
pgAdmin —— 客戶機 GUI 工具
並發控制
支持表級和行級鎖。InnoDB 存儲引擎支持 READ_COMMITTED、READ_UNCOMMITTED、REPEATABLE_READ 和 SERIALIZABLE。使用 SET TRANSACTION ISOLATION LEVEL 語句在事務級設置隔離級別。
支持表級和行級鎖。支持的 ANSI 隔離級別是 Read Committed(默認 —— 能看到查詢啟動時數據庫的快照)和 Serialization(與 Repeatable Read 相似 —— 只能看到在事務啟動之前提交的結果)。使用 SET TRANSACTION 語句在事務級設置隔離級別。使用 SET SESSION 在會話級進行設置。
MySQL相對於PostgreSQL的劣勢:
MySQL
PostgreSQL
最重要的引擎InnoDB很早就由Oracle公司控制。目前整個MySQL數據庫都由Oracle控制。
BSD協議,沒有被大公司壟斷。
對復雜查詢的處理較弱,查詢優化器不夠成熟
很強大的查詢優化器,支持很復雜的查詢處理。
只有一種表連接類型:嵌套循環連接(nested-loop),不支持排序-合並連接(sort-merge join)與散列連接(hash join)。
都支持
性能優化工具與度量信息不足
提供了一些性能視圖,可以方便的看到發生在一個表和索引上的select、delete、update、insert統計信息,也可以看到cache命中率。網上有一個開源的pgstatspack工具。
InnoDB的表和索引都是按相同的方式存儲。也就是說表都是索引組織表。這一般要求主鍵不能太長而且插入時的主鍵最好是按順序遞增,否則對性能有很大影響。
不存在這個問題。
大部分查詢只能使用表上的單一索引;在某些情況下,會存在使用多個索引的查詢,但是查詢優化器通常會低估其成本,它們常常比表掃描還要慢。
不存在這個問題
表增加列,基本上是重建表和索引,會花很長時間。
表增加列,只是在數據字典中增加表定義,不會重建表
存儲過程與觸發器的功能有限。可用來編寫存儲過程、觸發器、計劃事件以及存儲函數的語言功能較弱
除支持pl/pgsql寫存儲過程,還支持perl、python、Tcl類型的存儲過程:pl/perl,pl/python,pl/tcl。
也支持用C語言寫存儲過程。
不支持Sequence。
支持
不支持函數索引,只能在創建基於具體列的索引。
不支持物化視圖。
支持函數索引,同時還支持部分數據索引,通過規則系統可以實現物化視圖的功能。
執行計劃並不是全局共享的, 僅僅在連接內部是共享的。
執行計劃共享
MySQL支持的SQL語法(ANSI SQL標准)的很小一部分。不支持遞歸查詢、通用表表達式(Oracle的with 語句)或者窗口函數(分析函數)。
都 支持
不支持用戶自定義類型或域(domain)
支持。
對於時間、日期、間隔等時間類型沒有秒以下級別的存儲類型
可以精確到秒以下。
身份驗證功能是完全內置的,不支持操作系統認證、PAM認證,不支持LDAP以及其它類似的外部身份驗證功能。
支持OS認證、Kerberos 認證 、Ident 的認證、LDAP 認證、PAM 認證
不支持database link。有一種叫做Federated的存儲引擎可以作為一個中轉將查詢語句傳遞到遠程服務器的一個表上,不過,它功能很粗糙並且漏洞很多
有dblink,同時還有一個dbi-link的東西,可以連接到oracle和mysql上。
Mysql Cluster可能與你的想象有較大差異。開源的cluster軟件較少。
復制(Replication)功能是異步的,並且有很大的局限性.例如,它是單線程的(single-threaded),因此一個處理能力更強的Slave的恢復速度也很難跟上處理能力相對較慢的Master.
有豐富的開源cluster軟件支持。
explain看執行計劃的結果簡單。
explain返回豐富的信息。
類似於ALTER TABLE或CREATE TABLE一類的操作都是非事務性的.它們會提交未提交的事務,並且不能回滾也不能做災難恢復
DDL也是有事務的。
PostgreSQL主要優勢:
1. PostgreSQL完全免費,而且是BSD協議,如果你把PostgreSQL改一改,然後再拿去賣錢,也沒有人管你,這一點很重要,這表明了PostgreSQL數據庫不會被其它公司控制。oracle數據庫不用說了,是商業數據庫,不開放。而MySQL數據庫雖然是開源的,但現在隨著SUN被oracle公司收購,現在基本上被oracle公司控制,其實在SUN被收購之前,MySQL中最重要的InnoDB引擎也是被oracle公司控制的,而在MySQL中很多重要的數據都是放在InnoDB引擎中的,反正我們公司都是這樣的。所以如果MySQL的市場范圍與oracle數據庫的市場范圍沖突時,oracle公司必定會犧牲MySQL,這是毫無疑問的。
2. 與PostgreSQl配合的開源軟件很多,有很多分布式集群軟件,如pgpool、pgcluster、slony、plploxy等等,很容易做讀寫分離、負載均衡、數據水平拆分等方案,而這在MySQL下則比較困難。
3. PostgreSQL源代碼寫的很清晰,易讀性比MySQL強太多了,懷疑MySQL的源代碼被混淆過。所以很多公司都是基本PostgreSQL做二次開發的。
4. PostgreSQL在很多方面都比MySQL強,如復雜SQL的執行、存儲過程、觸發器、索引。同時PostgreSQL是多進程的,而MySQL是線程的,雖然並發不高時,MySQL處理速度快,但當並發高的時候,對於現在多核的單台機器上,MySQL的總體處理性能不如PostgreSQL,原因是MySQL的線程無法充分利用CPU的能力。
目前只想到這些,以後想到再添加,歡迎大家拍磚。
PostgreSQL與oracle或InnoDB的多版本實現的差別
PostgreSQL與oracle或InnoDB的多版本實現最大的區別在於最新版本和歷史版本是否分離存儲,PostgreSQL不分,而oracle和InnoDB分,而innodb也只是分離了數據,索引本身沒有分開。
PostgreSQL的主要優勢在於:
1. PostgreSQL沒有回滾段,而oracle與innodb有回滾段,oracle與Innodb都有回滾段。對於oracle與Innodb來說,回滾段是非常重要的,回滾段損壞,會導致數據丟失,甚至數據庫無法啟動的嚴重問題。另由於PostgreSQL沒有回滾段,舊數據都是記錄在原先的文件中,所以當數據庫異常crash後,恢復時,不會象oracle與Innodb數據庫那樣進行那麼復雜的恢復,因為oracle與Innodb恢復時同步需要redo和undo。所以PostgreSQL數據庫在出現異常crash後,數據庫起不來的幾率要比oracle和mysql小一些。
2. 由於舊的數據是直接記錄在數據文件中,而不是回滾段中,所以不會象oracle那樣經常報ora-01555錯誤。
3. 回滾可以很快完成,因為回滾並不刪除數據,而oracle與Innodb,回滾時很復雜,在事務回滾時必須清理該事務所進行的修改,插入的記錄要刪除,更新的記錄要更新回來(見row_undo函數),同時回滾的過程也會再次產生大量的redo日志。
4. WAL日志要比oracle和Innodb簡單,對於oracle不僅需要記錄數據文件的變化,還要記錄回滾段的變化。
PostgreSQL的多版本的主要劣勢在於:
1、最新版本和歷史版本不分離存儲,導致清理老舊版本需要作更多的掃描,代價比較大,但一般的數據庫都有高峰期,如果我們合理安排VACUUM,這也不是很大的問題,而且在PostgreSQL9.0中VACUUM進一步被加強了。
2、由於索引中完全沒有版本信息,不能實現Coverage index scan,即查詢只掃描索引,直接從索引中返回所需的屬性,還需要訪問表。而oracle與Innodb則可以;
進程模式與線程模式的對比
PostgreSQL和oracle是進程模式,MySQL是線程模式。
進程模式對多CPU利用率比較高。
進程模式共享數據需要用到共享內存,而線程模式數據本身就是在進程空間內都是共享的,不同線程訪問只需要控制好線程之間的同步。
線程模式對資源消耗比較少。
所以MySQL能支持遠比oracle多的更多的連接。
對於PostgreSQL的來說,如果不使用連接池軟件,也存在這個問題,但PostgreSQL中有優秀的連接池軟件軟件,如pgbouncer和pgpool,所以通過連接池也可以支持很多的連接。
堆表與索引組織表的的對比
Oracle支持堆表,也支持索引組織表
PostgreSQL只支持堆表,不支持索引組織表
Innodb只支持索引組織表
索引組織表的優勢:
表內的數據就是按索引的方式組織,數據是有序的,如果數據都是按主鍵來訪問,那麼訪問數據比較快。而堆表,按主鍵訪問數據時,是需要先按主鍵索引找到數據的物理位置。
索引組織表的劣勢:
索引組織表中上再加其它的索引時,其它的索引記錄的數據位置不再是物理位置,而是主鍵值,所以對於索引組織表來說,主鍵的值不能太大,否則占用的空間比較大。
對於索引組織表來說,如果每次在中間插入數據,可能會導致索引分裂,索引分裂會大大降低插入的性能。所以對於使用innodb來說,我們一般最好讓主鍵是一個無意義的序列,這樣插入每次都發生在最後,以避免這個問題。
由於索引組織表是按一個索引樹,一般它訪問數據塊必須按數據塊之間的關系進行訪問,而不是按物理塊的訪問數據的,所以當做全表掃描時要比堆表慢很多,這可能在OLTP中不明顯,但在數據倉庫的應用中可能是一個問題。
PostgreSQL9.0中的特色功能:
PostgreSQL中的Hot Standby功能
也就是standby在應用日志同步時,還可以提供只讀服務,這對做讀寫分離很有用。這個功能是oracle11g才有的功能。
PostgreSQL異步提交(Asynchronous Commit)的功能:
這個功能oracle中也是到oracle11g R2才有的功能。因為在很多應用場景中,當宕機時是允許丟失少量數據的,這個功能在這樣的場景中就特別合適。在PostgreSQL9.0中把synchronous_commit設置為false就打開了這個功能。需要注意的是,雖然設置為了異步提交,當主機宕機時,PostgreSQL只會丟失少量數據,異步提交並不會導致數據損壞而數據庫起不來的情況。MySQL中沒有聽說過有這個功能。
PostgreSQL中索引的特色功能:
PostgreSQL中可以有部分索引,也就是只能表中的部分數據做索引,create index 可以帶where 條件。同時PostgreSQL中的索引可以反向掃描,所以在PostgreSQL中可以不必建專門的降序索引了。