字符集&字符編碼方式
字符集(Character set)是多個字符的集合,字符集種類較多,每個字符集包含的字符個數不同,這裡的字符可以是英文字符,漢字字符,或者其他國家語言字符。
常見字符集包括:ASCII字符集、LATIN1字符集、GB2312字符集、GBK字符集、GB18030字符集、Unicode字符集等。字符編碼方式是用一個或多個字節表示字符集中的一個字符。每種字符集都有自己特有的編碼方式,因此同一個字符,在不同字符集的編碼方式下,會產生不同的二進制。ASCII是基於羅馬字母表的一套字符集,它采用1個字節的低7位表示字符,高位始終為0。LATIN1字符集相對於ASCII字符集做了擴展,仍然使用一個字節表示字符,但啟用了高位,擴展了字符集的表示范圍。GB2312、GBK、GB18030字符集是支持中文的字符集,字符集范圍GB2312<GBK< GB18030。GBK字符集的字符有一字節編碼和兩字節編碼方式。對於00-7F的字符與ASCII保持一致,漢字采用2個字節表示。第一字節范圍是81-FE,避免與00-7F沖突。Unicode字符集是計算機科學領域裡的一項業界標准,支持了所有國家的文字字符。Unicode字符集有好幾種編碼方式,比如常見的utf-8,utf-16,utf-32等。Utf8采用1-4個字節表示字符,utf-16采用固定的2個字節,utf-32則采用4個字節存儲。
mysql與字符集
只要涉及到文字的地方,就會存在字符集和編碼方式。對於mysql數據庫系統而言,用戶從mysql client端敲入一條sql語句,通過TCP/IP傳遞給mysql server進程,到最終存入server端的文件,每個環節都涉及到字符存儲。涉及到字符存儲的地方,就涉及到字符集編碼,通過mysql提供的系統變量就可見一斑。mysql字符集設置系統變量以及含義如下表:
變量名
含義
character_set_server
默認的內部操作字符集
character_set_client
客戶端來源數據使用的字符集
character_set_connection
連接層字符集
character_set_results
查詢結果字符集
character_set_database
當前選中數據庫的默認字符集
character_set_system
系統元數據(字段名等)字符集
mysql字符編碼轉換流程
如果以上各個系統變量的設置不一致,比如character_set_client為UTF8,而character_set_database為GBK,則會出現需要進行編碼轉換的情況。那麼字符集轉換的原理是什麼?假設GBK字符集的字符串“小明”,需要轉為UTF8字符集存儲,實際就是對於“小明”字符串中的每個漢字去UTF8編碼表裡面查詢對應的二進制,然後存儲,僅此而已,編碼轉換並不涉及到復雜的算法。mysql字符集轉換主要涉及到幾個步驟:
1) 將數據從character_set_client設置轉換為character_set_connection設置;
2) 將character_set_connection設置轉為表字段的字符集設置;
3) 將操作結果從表字段字符集轉為character_set_results設置。
下面我通過一個常用的場景來描述字符集轉換的流程。用戶通過mysql命令行(如果是遠程連接:SecureCRT),敲入命令“insert into T values(1,’小明’)”,字符串’小明’在流轉過程中二進制存儲內容。
a) 用戶采用的客戶端為utf8字符集,character_set_client=gbk,character_set_connection=gbk, 表T采用gbk字符集。
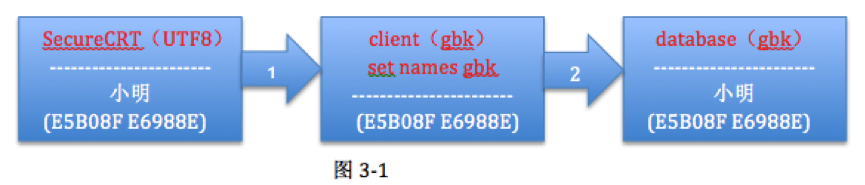
由於character_set_client、character_set_connection和表字符集均為GBK,不涉及編碼轉換。因此,表雖然為字符集雖然為GBK,但“小明”的編碼並非為GBK編碼的二進制流,而是UTF8的二進制流,兩個漢字占用了6個字節,而讀取則是一個逆向的過程,不涉及到編碼轉換,查詢依然能正確返回“小明”。
b) 在a)的情況下,改變character_set_client的設置為utf8,查詢插入的值。

可以看到返回的值是“灏忔槑”, 這是由於表的字符集是GBK,而客戶端請求是UTF8,那麼server將二進制流E5B08FE6988E對應的GBK漢字“灏忔槑”轉為UTF8漢字對應的二進制流E7818FE5BF94E6A791,因此查詢結果在SecureCRT就顯示為“灏忔槑”,即通常我們所謂的亂碼。
c) 在b)的情況下,設置SecureCRT的字符集為GBK,看看SecureCRT字符集設置對結果影響
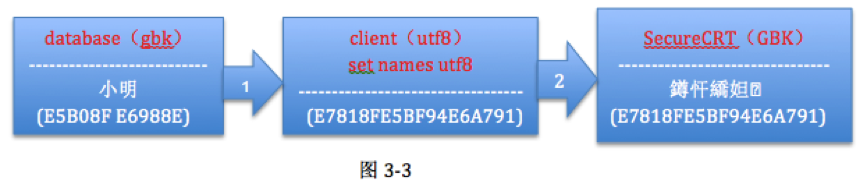
可以看到返回的是另外一組字符“鐏忓繑妲�”,整個流轉過程與b)一樣,只是在第一步發生了字節流轉換,設置SecureCRT字符集編碼,只是改變了顯示方式。
字符集相關的SQL語句
1) 查看字符集編碼設置
SHOW VARIABLES LIKE ‘%CHARACTER%’
2) 設置字符集編碼
SET NAMES xxx;
這個語句相當於設置了client的字符集,主要包含3個系統變量,character_set_client,character_set_connection和character_set_results。
3) 修改數據庫字符集
ALTER DATABASE DATABASENAME CHARACTER SET XXX;
這個語句只修改庫的字符集,影響後續創建的表的默認定義;對於已創建的表的字符集不受影響。
4) 修改表的字符集
ALTER TABLE TABLENAME CHARACTER SET XXX;
這個語句只修改表的字符集,影響後續該表新增列的默認定義,已有列的字符集不受影響。
ALTER TABLE TABLENAME CONVERT TO CHARACTER SET XXX;
這個語句同時修改表字符集和已有列字符集,並將已有數據進行字符集編碼轉換。
5) 修改列字符集
ALTER TABLE `TABLE_NAME` MODIFY COLUMN `COLUMN_NAME` CHARACTER SET xxx
6) 查詢字符的二進制編碼
SELECT HEX(COL_NAME) FROM TABLE_NAME; SELECT LENGTH(COL_NAME) FROM TABLE_NAME;
對於GBK的表,如果查出來一個字符占用了3個字節,比如圖1這種情況,則肯定是字符集在某個環節設置統一,圖1就是因為客戶端是UTF8,而mysqlclient和database都是GBK造成的。
mysql默認的字符集latin1
mysql 4.x版本之前默認采用的是latin1字符集(又稱ISO-8859-1),latin1字符集編碼方式采用單字節編碼。拋一個問題,latin1字符集的表,用戶寫入和讀取漢字是否有問題?答案是只要合理設置,沒有問題。假設SecureCRT為UTF8,character_set_client和表字符集均設置為latin1,參考第3節的分析,那麼用戶讀取和寫入數據的過程中,並不涉及字符集編碼轉換的問題,將UTF8的漢字字符轉為二進制流寫入database,提取出來後,secureCRT再將對應的二進制解碼為對應的漢字,所以不影響用戶的使用。但是,若character_set_client,character_set_connection,與表字符集設置等不統一,就可能出現亂碼的情況。