hadoop的安裝配置這裡就不講了。
Sqoop的安裝也很簡單。 完成sqoop的安裝後,可以這樣測試是否可以連接到mysql(注意:mysql的jar包要放到 SQOOP_HOME/lib 下): sqoop list-databases --connect jdbc:mysql://192.168.1.109:3306/ --username root --password 19891231 結果如下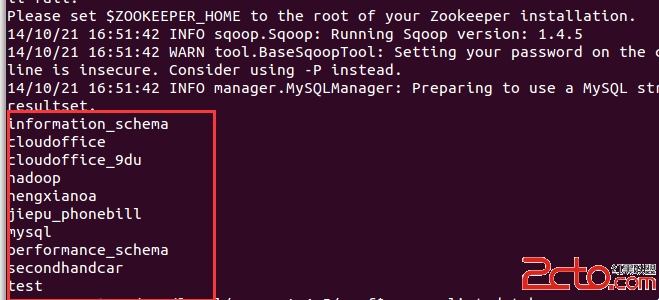 即說明sqoop已經可以正常使用了。 下面,要將mysql中的數據導入到hadoop中。 我准備的是一個300萬條數據的身份證數據表:
即說明sqoop已經可以正常使用了。 下面,要將mysql中的數據導入到hadoop中。 我准備的是一個300萬條數據的身份證數據表: 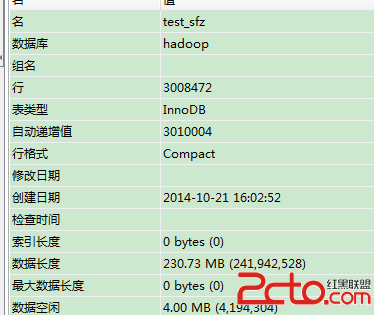 先啟動hive(使用命令行:hive 即可啟動) 然後使用sqoop導入數據到hive: sqoop import --connect jdbc:mysql://192.168.1.109:3306/hadoop --username root --password 19891231 --table test_sfz --hive-import sqoop 會啟動job來完成導入工作。
先啟動hive(使用命令行:hive 即可啟動) 然後使用sqoop導入數據到hive: sqoop import --connect jdbc:mysql://192.168.1.109:3306/hadoop --username root --password 19891231 --table test_sfz --hive-import sqoop 會啟動job來完成導入工作。 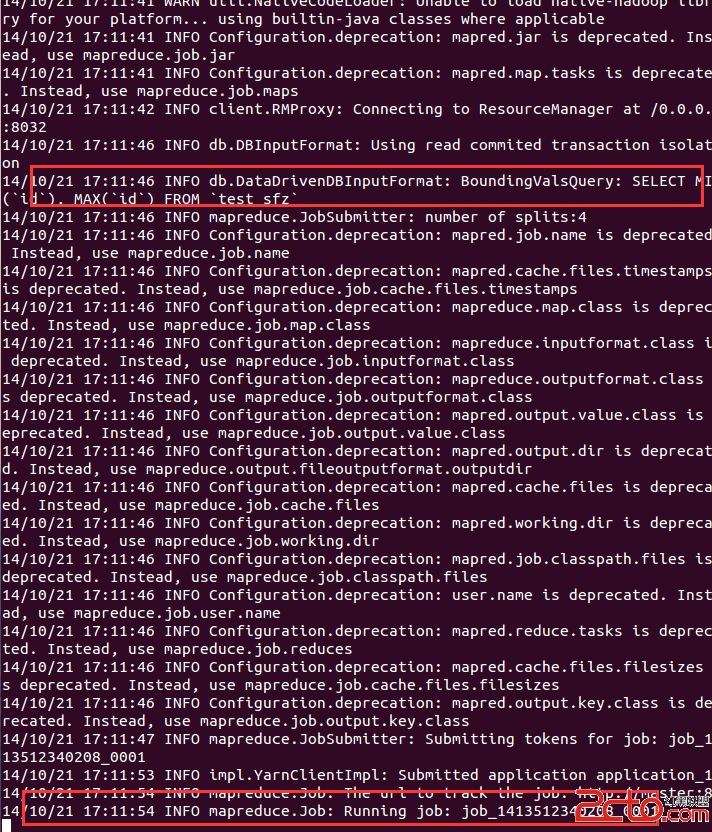
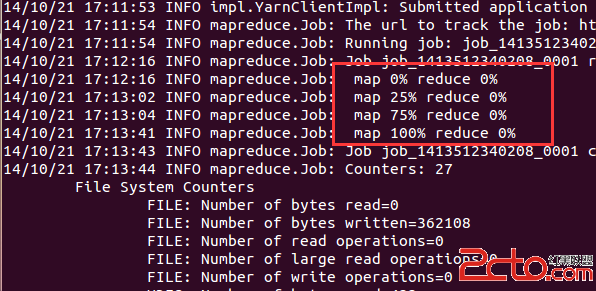 完成導入用了2分20秒,還是不錯的。 在hive中可以看到剛剛導入的數據表:
完成導入用了2分20秒,還是不錯的。 在hive中可以看到剛剛導入的數據表: 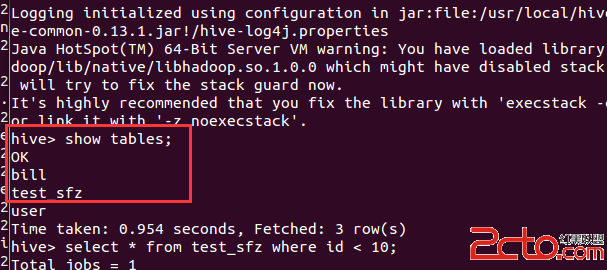 我們來一句sql測試一下數據: select * from test_sfz where id < 10;
我們來一句sql測試一下數據: select * from test_sfz where id < 10; 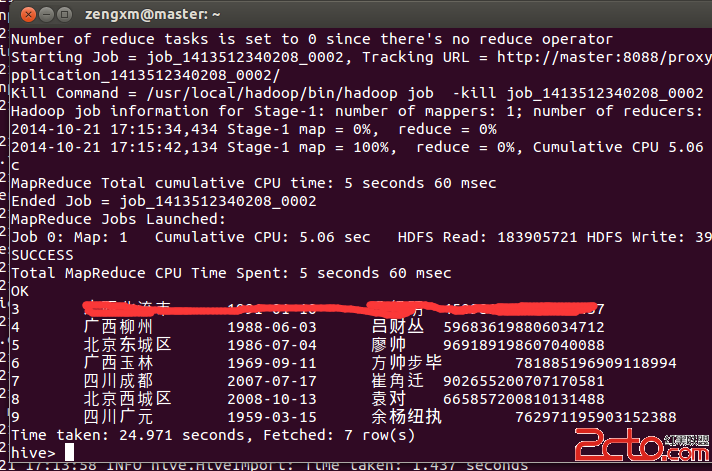 可以看到,hive完成這個任務用了將近25秒,確實是挺慢的(在mysql中幾乎是不費時間),但是要考慮到hive是創建了job在hadoop中跑,時間當然多。
可以看到,hive完成這個任務用了將近25秒,確實是挺慢的(在mysql中幾乎是不費時間),但是要考慮到hive是創建了job在hadoop中跑,時間當然多。
 hadoop 是運行在虛擬機上的偽分布式,虛擬機OS是ubuntu12.04 64位,配置如下:
hadoop 是運行在虛擬機上的偽分布式,虛擬機OS是ubuntu12.04 64位,配置如下: 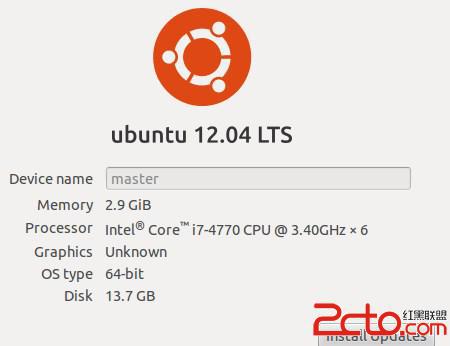
 1. 計算廣東的平均年齡 mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時: 5.642s hive:select (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時:168.259s 2. 對每個城市的的平均年齡進行從高到低的排序 mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:11.964s hive:select address, (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:311.714s
1. 計算廣東的平均年齡 mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時: 5.642s hive:select (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時:168.259s 2. 對每個城市的的平均年齡進行從高到低的排序 mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:11.964s hive:select address, (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:311.714s
 (這次用的時間很短!可能是因為TEST2中的導入時,我的主機在做其他耗資源的工作..) 1. 計算廣東的平均年齡 mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時: 6.605s hive:select (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時:188.206s 2. 對每個城市的的平均年齡進行從高到低的排序 mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:19.926s hive:select address, (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:411.816s
(這次用的時間很短!可能是因為TEST2中的導入時,我的主機在做其他耗資源的工作..) 1. 計算廣東的平均年齡 mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時: 6.605s hive:select (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like '廣東%'; 用時:188.206s 2. 對每個城市的的平均年齡進行從高到低的排序 mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:19.926s hive:select address, (sum(year('2014-10-01') - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用時:411.816s