innodb是一個多線程並發的存儲引擎,內部的讀寫都是用多線程來實現的,所以innodb內部實現了一個比較高效的並發同步機制。innodb並沒有直接使用系統提供的鎖(latch)同步結構,而是對其進行自己的封裝和實現優化,但是也兼容系統的鎖。我們先看一段innodb內部的注釋(MySQL-3.23):
Semaphore operations in operating systems are slow: Solaris on a 1993 Sparc takes 3 microseconds (us) for a lock-unlock pair and Windows NT on a 1995 Pentium takes 20 microseconds for a lock-unlock pair. Therefore, we have toimplement our own efficient spin lock mutex. Future operating systems mayprovide efficient spin locks, but we cannot count on that.
大概意思是說1995年的時候,一個Windows NT的 lock-unlock所需要耗費20us,即使是在Solaris 下也需要3us,這也就是他為什麼要實現自定義latch的目的,在innodb中作者實現了系統latch的封裝、自定義mutex和自定義rw_lock。下面我們來一一做分析。
typedef pthread_mutex os_fast_mutex_t;而os_event_t相對復雜,它是通過os_fast_mutex_t和一個pthread_cond_t來實現的,定義如下:
typedef struct os_event_struct
{
os_fast_mutex_t os_mutex;
ibool is_set;
pthread_cond_t cond_var;
}os_event_t;
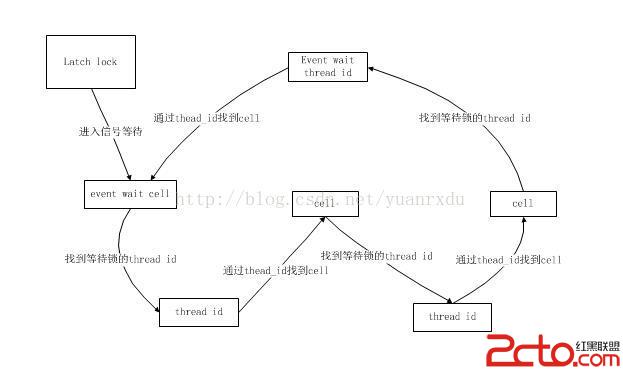
以下是os_event_t的兩線程信號控制的例子流程: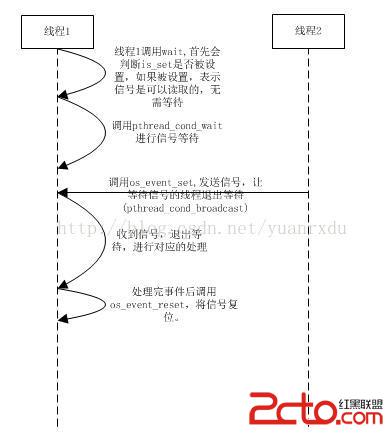
asm volatile("movl $1, %%eax; xchgl (%%ecx), %%eax" :
"=eax" (res), "=m" (*lw) :
"ecx" (lw));
這段代碼是什麼意思呢?其實就是將lw的值設置成1,並且返回設置lw之前的值(res),這個過程都是CPU需要回寫內存的,也就是CPU和內存是完全一致的。除了上面設置1以外,還有一個復位的實現,如下:
asm volatile("movl $0, %%eax; xchgl (%%ecx), %%eax" :
"=m" (*lw) : "ecx" (lw) : "eax");
這兩個函數交叉起來使用,就是gcc-4.1.2以後的__sync_lock_test_and_set的基本實現了。在MySQL-5.6的Innodb引擎當中,將以上匯編代碼采用了__sync_lock_test_and_set代替,我們可以采用原子操作實現一個簡單的mutex.
#define LOCK() while(__sync_lock_test_and_set(&lock, 1)){}
#define UNLOCK() __sync_lock_release(&lock)
以上就是一個基本的無鎖結構的mutex,在linux下測試確實比pthread_mutex效率要高出不少。當然在innodb之中的mutex實現不會僅僅這麼簡單,需要考慮的因素還是比較多的,例如:同線程多次lock、lock自旋的周期、死鎖檢測等。
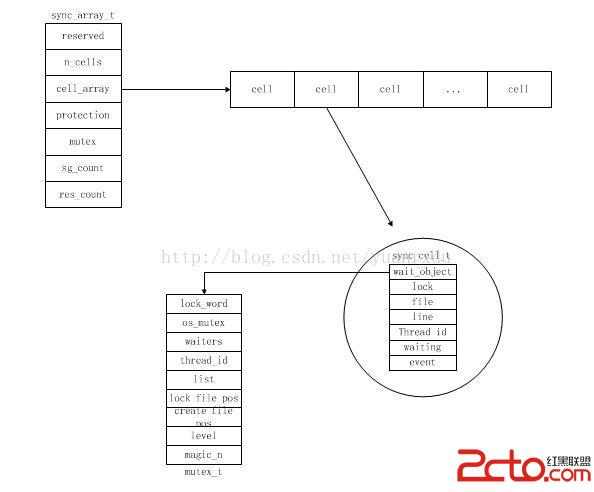
struct mutex_struct
{
ulint lock_word; /*mutex原子控制變量*/
os_fast_mutex_t os_fast_mutex; /*在編譯器或者系統部支持原子操作的時候采用的系統os_mutex來替代mutex*/
ulint waiters; /*是否有線程在等待鎖*/
UT_LIST_NODE_T(mutex_t) list; /*mutex list node*/
os_thread_id_t thread_id; /*獲得mutex的線程ID*/
char* file_name; /*mutex lock操作的文件/
ulint line; /*mutex lock操作的文件的行數*/
ulint level; /*鎖層ID*/
char* cfile_name; /*mute創建的文件*/
ulint cline; /*mutex創建的文件行數*/
ulint magic_n; /*魔法字*/
};
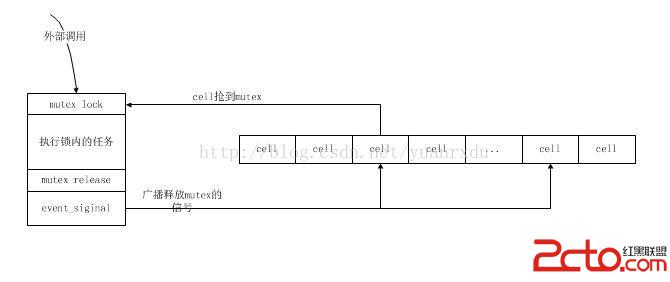
在自定義mute_t的接口方法中,最核心的兩個方法是:mutex_enter_func和mutex_exit方法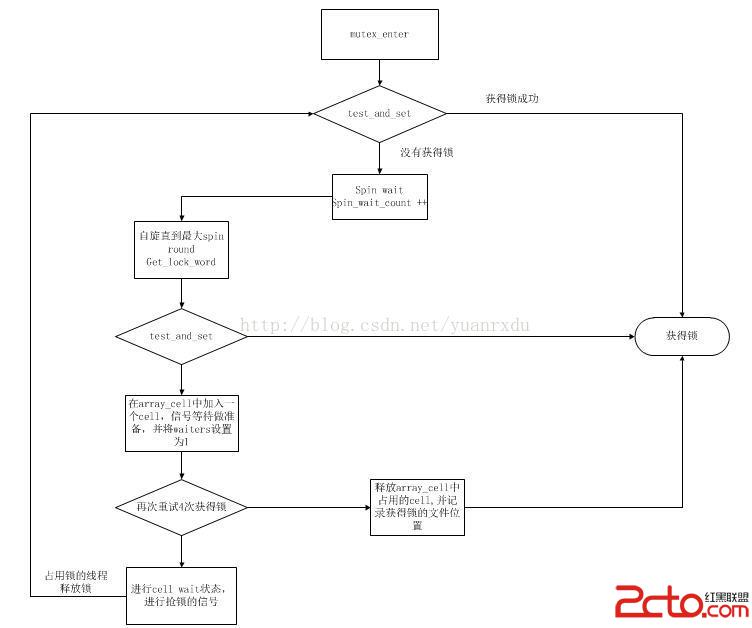
struct rw_lock_struct
{
ulint reader_count; /*獲得S-LATCH的讀者個數,一旦不為0,表示是S-LATCH鎖*/
ulint writer; /*獲得X-LATCH的狀態,主要有RW_LOCK_EX、RW_LOCK_WAIT_EX、
RW_LOCK_NOT_LOCKED, 處於RW_LOCK_EX表示是一個x-latch
鎖,RW_LOCK_WAIT_EX的狀態表示是一個S-LATCH鎖*/
os_thread_id_t writer_thread; /*獲得X-LATCH的線程ID或者第一個等待成為x-latch的線程ID*/
ulint writer_count; /*同一線程中X-latch lock次數*/
mutex_t mutex; /*保護rw_lock結構中數據的互斥量*/
ulint pass; /*默認為0,如果是非0,表示線程可以將latch控制權轉移給其他線程,
在insert buffer有相關的調用*/
ulint waiters; /*有讀或者寫在等待獲得latch*/
ibool writer_is_wait_ex;
UT_LIST_NODE_T(rw_lock_t) list;
UT_LIST_BASE_NODE_T(rw_lock_debug_t) debug_list;
ulint level; /*level標示,用於檢測死鎖*/
/*用於調試的信息*/
char* cfile_name; /*rw_lock創建時的文件*/
ulint cline; /*rw_lock創建是的文件行位置*/
char* last_s_file_name; /*最後獲得S-latch時的文件*/
char* last_x_file_name; /*最後獲得X-latch時的文件*/
ulint last_s_line; /*最後獲得S-latch時的文件行位置*/
ulint last_x_line; /*最後獲得X-latch時的文件行位置*/
ulint magic_n; /*魔法字*/
};
在rw_lock_t獲得鎖和釋放鎖的主要接口是:rw_lock_s_lock_func、rw_lock_x_lock_func、rw_lock_s_unlock_func、rw_lock_x_unlock_func四個關鍵函數。 其中rw_lock_s_lock_func和rw_lock_x_lock_func中定義了自旋函數,這兩個自旋函數的流程和mutex_t中的自旋函數實現流程是相似的,其目的是要在自旋期間就完成鎖的獲得。具體細節可以查看sync0rw.c中的rw_lock_s_lock_spin/rw_lock_x_lock_func的代碼實現。從上面結構的定義和函數的實現可以知道rw_lock有四種狀態: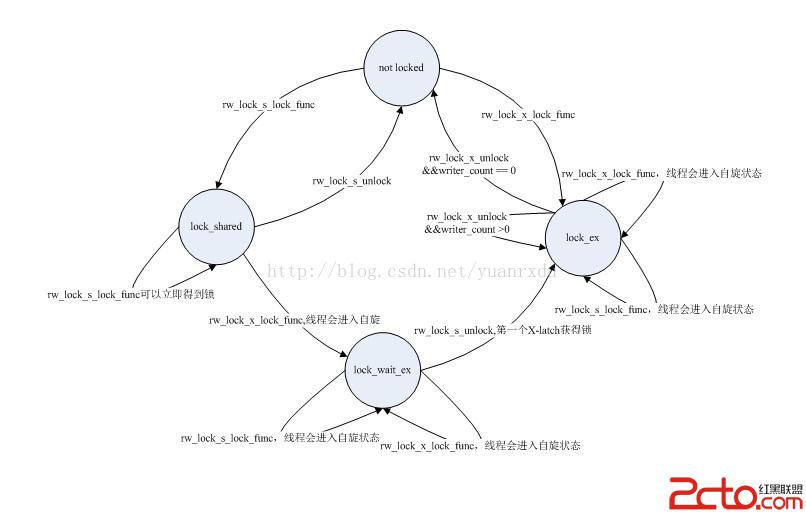
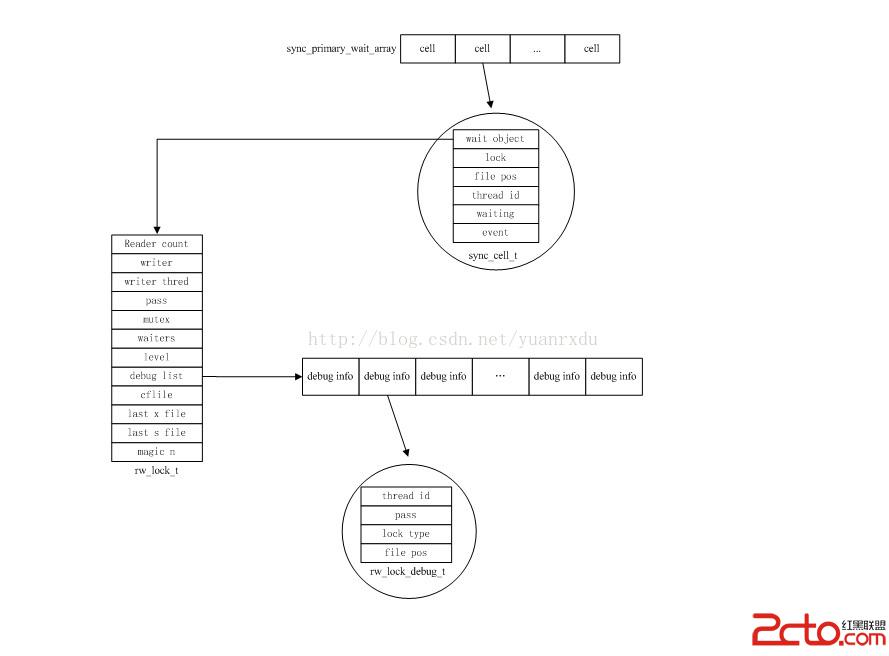
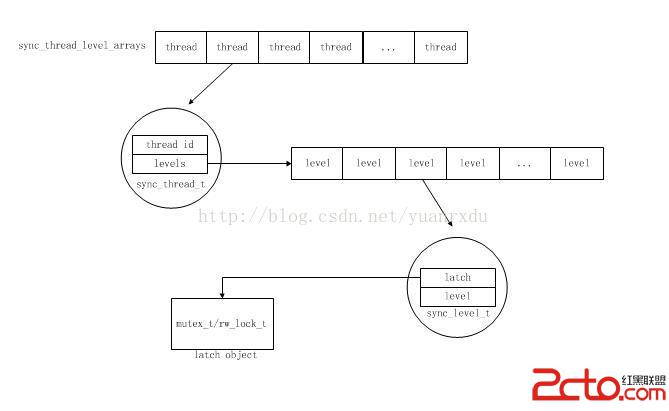
/*sync_thread_t*/
struct sync_thread_struct
{
os_thread_id_t id; /*占用latch的thread的id*/
sync_level_t* levels; /*latch的信息,sync_level_t結構內容*/
};
/*sync_level_t*/
struct sync_level_struct
{
void* latch; /*latch句柄,是mute_t或者rw_lock_t的結構指針*/
ulint level; /*latch的level標識ID*/
};
在latch獲得的時候,innodb會調用mutex_set_debug_info函數向sync_thread_t中加入一個latch被獲得的狀態信息,其實就是包括獲得latch的線程id、獲得latch的文件位置和latch的層標識(具體的細節可以查看mutex_enter_func和mutex_spin_wait)。只有占用了latch才會體現在sync_thread_t中,如果只是在等待獲得latch是不會加入到sync_thread_t當中的。innodb可以通過sync_thread_levels_empty_gen函數來輸出所有latch等待依賴的cell_t序列,追蹤線程等待的位置。