innodb next-key lock解析
參考http://blog.csdn.net/zbszhangbosen/article/details/7434637#reply
這裡補充一些:
(1)InnoDB默認加鎖方式是next-key locking
(2)在聚集索引中,如果主鍵有唯一性約束(unique,auto increment),next-key locking 會自動降級為record locking。
(3)由於事務的隔離性和一致性要求,會對所有掃描到的record加鎖。比如:update ... where/delete .. where/select ...from...lock in share mode/ select .. from .. for update這都是next-key lock。
(4)注意優化器的選擇。包括聚集索引和輔助索引,有時會用全表掃描替代索引掃描,這時整張表(聚集索引表)都會被加鎖。
record lock:記錄鎖,也就是僅僅鎖著單獨的一行
gap lock:區間鎖,僅僅鎖住一個區間(注意這裡的區間都是開區間,也就是不包括邊界值,至於為什麼這麼定義?innodb官方定義的)
next-key lock:record lock+gap lock,所以next-key lock也就半開半閉區間,且是下界開,上界閉。(為什麼這麼定義?innodb官方定義的)
下面來舉個手冊上的例子看什麼是next-key lock。假如一個索引的行有10,11,13,20
那麼可能的next-key lock的包括:
(無窮小, 10]
(10,11]
(11,13]
(13,20]
(20, 無窮大) (這裡無窮大為什麼不是閉合?你數學不到家~~)
好了現在通過舉例子說明:
表test
mysql> show create table test;
+-------+--------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------+
| test | CREATE TABLE `test` (
`a` int(11) NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+--------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> select * from test;
+----+
| a |
+----+
| 11 |
| 12 |
| 13 |
| 14 |
+----+
4 rows in set (0.00 sec)
開始實驗:
(一)
session 1:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from test where a=11;
Query OK, 1 row affected (0.00 sec)
session 2:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test values(10);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values(15);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values(9);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values(16);
Query OK, 1 row affected (0.01 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
ok,上面的情況是預期的,因為a上有索引,那麼當然就只要鎖定一行,所以其他行的插入不會被阻塞。
那麼接下來的情況就有意思了
(二)
session 1(跟上一個session 1相同):
delete from test where a=22;
Query OK, 0 rows affected (0.01 sec)
session 2:
mysql> insert into test values (201);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (20);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (19);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (18);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (16);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (9);
Query OK, 1 row affected (0.00 sec)
從上面的結果來看,在a=11後面所有的行,也就是區間(11,無窮大)都被鎖定了。先不解釋原因,再來看一種情況:
(三)
session 1:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test;
+----+
| a |
+----+
| 7 |
| 9 |
| 10 |
| 12 |
| 13 |
| 14 |
| 15 |
| 22 |
| 23 |
| 24 |
| 25 |
+----+
11 rows in set (0.00 sec)
mysql> delete from test where a=21;
Query OK, 0 rows affected (0.00 sec)
session 2:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test values (20);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (26);
Query OK, 1 row affected (0.00 sec)
mysql> insert into test values (21);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (16);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into test values (6);
Query OK, 1 row affected (0.01 sec)
從這裡可以看出,現在被鎖住的區間就只有[16,21)了。
有了前面對三種類型的加鎖解釋,現在可以來解釋為什麼會這樣了,在innodb表中 delete from where ..針對掃描到的索引記錄加next-key鎖(具體的什麼語句加什麼鎖可以查看手冊,另外需要說明一下,行鎖加鎖對象永遠是索引記錄,因為innodb中表即索引) 。
在(一)中,實際上加的next-key lock就是(11,11] 因此也只有a=11這一條記錄被鎖住,其他所有插入都沒有關系。
在(二)中,因為a=22這條記錄不存在,而且22比表裡所有的記錄值都大,所以在innodb看來鎖住的區間就是(14, 無窮大)。所以在插入14以後的值都提示被鎖住,而14之前的則可以。
在(三)種,a=21也是不存在,但是在表裡面21前後都有記錄,因此這裡next-key lock的區間也就是(15,21],因此不在這個區間內的都可以插入。
那麼為什麼next-key lock都是下界開區間,上界閉區間呢?這個倒不重要,管它呢,但是有一點我個人卻覺得比較怪,比如說
delete test where a > 11 #------- 1
它的next-key lock是(11, 無窮大)
delete test where a < 11 #------- 2
它的next-key lock是(無窮小, 10]
這樣給人的感覺就很怪,因為在手冊上對next-key lock的定義:
Next-key lock: This is a combination of a record lock on the index record and a gap lock on the gapbefore the index record.
而在1那種情況下,如果按照手冊上的解釋,記錄鎖和它之前的gap那麼就會有些牽強。[今天再次看了一遍官方手冊,是之前自己的理解不到位,這個before是對的,因為innodb在加鎖時是所有掃描過程中遇到的記錄都會被加鎖,那麼對於1那種情況,實際上是從12開始掃描,但是因為要保證a>11的都被delete掉,因此得一直掃描下去那自然最大值就是無窮大,因為這個next-key lock就是無窮大這條記錄(這是假設的一條記錄,表示一個邊界)加上它之前的gap lock (11, 無窮大),所以在任何時候next-lock都是record lock加上這個record之前的一個gap lock]
但是只要我們自己能理解就行了:記錄鎖---鎖單條記錄;區間鎖---鎖一個開區間;next-key 鎖---前面兩者的結合,而不要管什麼before。
另外next-key lock雖然在很多時候是鎖一個區間,但要明白一個區間也可能只有一個元素,因此在稱delete from tb where key=x 這種情況下加next-key鎖也是完全正確的。
另外還提兩點:
1.如果我們的SQL語句裡面沒有利用到索引,那麼加鎖對象將是所有行(但不是加表鎖),所以建索引是很重要的
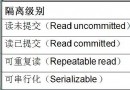
2.next-key lock是為防止幻讀的發生,而只有repeatable-read以及以上隔離級別才能防止幻讀,所以在read-committed隔離級別下面沒有next-key lock這一說法。