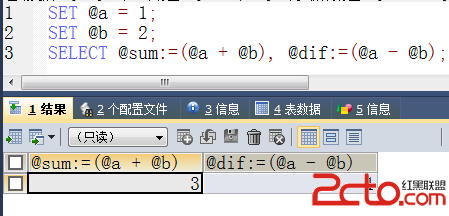
優化原則:小表驅動大表,即小的數據集驅動大的數據集。
############# 原理 (RBO) #####################
select * from A where id in (select id from B) 等價於: for select id from B for select * from A where A.id = B.id
當B表的數據集必須小於A表的數據集時,用in優於exists。
select * from A where exists (select 1 from B where B.id = A.id) 等價於 for select * from A for select * from B where B.id = A.id
當A表的數據集系小於B表的數據集時,用exists優於in。
注意:A表與B表的ID字段應建立索引。
例如:
/** 執行時間:0.313s **/ SELECT SQL_NO_CACHE * FROM rocky_member m WHERE EXISTS (SELECT 1 FROM rocky_vip_appro a WHERE m.ID = a.user_id AND a.passed = 1); /** 執行時間:0.160s **/ SELECT SQL_NO_CACHE * FROM rocky_member m WHERE m.ID in(SELECT ID FROM rocky_vip_appro WHERE passed = 1);
not in 和not exists用法類似。
in 是把外表和內表作hash 連接;
exists 是對外表作loop循環,每次loop循環再對內表進行查詢。
一直以來認為exists比in效率高的說法是不准確的。
如果查詢的兩個表大小相當,那麼用in和exists差別不大。
如果兩個表中一個較小,一個是大表,則子查詢表大的用exists,子查詢表小的用in。
希望對你有幫助。
算法上存在很大問題。我們先來分析該算法的執行次數。
按照你的方法,record表中的id字段要全部查詢一遍,也就是2W次查詢,而每次查詢,最壞
情況下需要與offline_record中的rec.id進行4W次比較,這又導致offline_record表的4W次
查詢(取rec_id )。假設滿足
a.* from record a where a.id not in(select b.rec_id from offline_record);
條件的記錄一共有N條,那麼,最壞情況下,該算法所做的查詢次數為:
2W(取record.id)+2W*4W(每取一次record.id就要取一次offline_record.rec_id且offline_record的最後一條數據滿足條件)+N(每
條滿足條件的記錄需要再在record中取該記錄全部數據)
所做的比較次數為:
2W*4w
考慮最好情況下的效率,該算法所做的查詢次數為:
2W(取record.id)+2W*1(每取一次record.id就要取一次offline_record.rec_id且offline_record的第一條數據滿足條件)+N(N(每
條滿足條件的記錄需要再在record中取該記錄全部數據)
所做的比較次數為:
2W*1
因此,該算法平均查詢次數為:
2W+(4w*2w+1)*2w/2+N ->8*10^12
天文數字!這還不考慮將近4億次的平均比較次數,所以你的執行效率當然低了
下面,我們對該算法來進行優化:
算法主要解決的問題是,取表record中id不等於offline_record.rec_id的數據。現假定id為record的主鍵(你的問題沒有指明,但是你會看到無論id是否主鍵都不影響分析),設計算法如下:
1、取offline_record.rec_id的結果為集合,並對該集合進行排序,設最終生成的集合為A 。則,查詢數據庫4w次,生成集合的算法按照O(N*ln N)的效率來算平均情況下比較O(4W*ln 4w),約等於64W次,排序次數按照O(N*ln N)的效率來算平均情況下比較O(4W*ln 4w),約等於64W次。
2、順序取record中的id與第一步生成的集合A進行比較,從而得出最終結果。該過程中由於record.id與A均為有序表,所以比較次數為2w次,查詢次數為2w+N次。
如上算法,查詢次數為 4W+2W+N=6W+N次,平均比較次數為 64W+64W+2W=130w次。
顯而易見,該算法對原算法進行了最大的優化,大概將速度提高了10*8倍。
考慮到對數據庫的查詢時間遠遠大於排序比較時間,改進厚的算法在實際操作中還會有更好的表現。
至於你對mysql查詢語句的優化,則是治標不治本之舉,雖然有用,但畢竟是微小量變,不足與影響全局,在一個壞的算法下,幾乎不能提升性能。