眾所周知,在MySQL中,如果直接 ORDER BY RAND() 的話,效率非常差,因為會多次執行。事實上,如果等值查詢也是用 RAND() 的話也如此,我們先來看看下面這幾個SQL的不同執行計劃和執行耗時。
首先,看下建表DDL,這是一個沒有顯式自增主鍵的InnoDB表:
復制代碼 代碼如下:
[yejr@imysql]> show create table t_innodb_random\G
*************************** 1. row ***************************
Table: t_innodb_random
Create Table: CREATE TABLE `t_innodb_random` (
`id` int(10) unsigned NOT NULL,
`user` varchar(64) NOT NULL DEFAULT '',
KEY `idx_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
往這個表裡灌入一些測試數據,至少10萬以上, id 字段也是亂序的。
復制代碼 代碼如下:
[yejr@imysql]> select count(*) from t_innodb_random\G
*************************** 1. row ***************************
count(*): 393216
1、常量等值檢索:
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random where id = 13412\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_innodb_random
type: ref
possible_keys: idx_id
key: idx_id
key_len: 4
ref: const
rows: 1
Extra: Using index
[yejr@imysql]> select id from t_innodb_random where id = 13412;
1 row in set (0.00 sec)
可以看到執行計劃很不錯,是常量等值查詢,速度非常快。
2、使用RAND()函數乘以常量,求得隨機數後檢索:
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random where id = round(rand()*13241324)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_innodb_random
type: index
possible_keys: NULL
key: idx_id
key_len: 4
ref: NULL
rows: 393345
Extra: Using where; Using index
[yejr@imysql]> select id from t_innodb_random where id = round(rand()*13241324)\G
Empty set (0.26 sec)
可以看到執行計劃很糟糕,雖然是只掃描索引,但是做了全索引掃描,效率非常差。因為WHERE條件中包含了RAND(),使得MySQL把它當做變量來處理,無法用常量等值的方式查詢,效率很低。
我們把常量改成取t_innodb_random表的最大id值,再乘以RAND()求得隨機數後檢索看看什麼情況:
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random where id = round(rand()*(select max(id) from t_innodb_random))\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t_innodb_random
type: index
possible_keys: NULL
key: idx_id
key_len: 4
ref: NULL
rows: 393345
Extra: Using where; Using index
*************************** 2. row ***************************
id: 2
select_type: SUBQUERY
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Select tables optimized away
[yejr@imysql]> select id from t_innodb_random where id = round(rand()*(select max(id) from t_innodb_random))\G
Empty set (0.27 sec)
可以看到,執行計劃依然是全索引掃描,執行耗時也基本相當。
3、改造成普通子查詢模式 ,這裡有兩次子查詢
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random where id = (select round(rand()*(select max(id) from t_innodb_random)) as nid)\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t_innodb_random
type: index
possible_keys: NULL
key: idx_id
key_len: 4
ref: NULL
rows: 393345
Extra: Using where; Using index
*************************** 2. row ***************************
id: 3
select_type: SUBQUERY
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Select tables optimized away
[yejr@imysql]> select id from t_innodb_random where id = (select round(rand()*(select max(id) from t_innodb_random)) as nid)\G
Empty set (0.27 sec)
可以看到,執行計劃也不好,執行耗時較慢。
4、改造成JOIN關聯查詢,不過最大值還是用常量表示
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random t1 join (select round(rand()*13241324) as id2) as t2 where t1.id = t2.id2\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: system
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: t1
type: ref
possible_keys: idx_id
key: idx_id
key_len: 4
ref: const
rows: 1
Extra: Using where; Using index
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: No tables used
[yejr@imysql]> select id from t_innodb_random t1 join (select round(rand()*13241324) as id2) as t2 where t1.id = t2.id2\G
Empty set (0.00 sec)
這時候執行計劃就非常完美了,和最開始的常量等值查詢是一樣的了,執行耗時也非常之快。
這種方法雖然很好,但是有可能查詢不到記錄,改造范圍查找,但結果LIMIT 1就可以了:
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random where id > (select round(rand()*(select max(id) from t_innodb_random)) as nid) limit 1\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t_innodb_random
type: index
possible_keys: NULL
key: idx_id
key_len: 4
ref: NULL
rows: 393345
Extra: Using where; Using index
*************************** 2. row ***************************
id: 3
select_type: SUBQUERY
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Select tables optimized away
[yejr@imysql]> select id from t_innodb_random where id > (select round(rand()*(select max(id) from t_innodb_random)) as nid) limit 1\G
*************************** 1. row ***************************
id: 1301
1 row in set (0.00 sec)
可以看到,雖然執行計劃也是全索引掃描,但是因為有了LIMIT 1,只需要找到一條記錄,即可終止掃描,所以效率還是很快的。
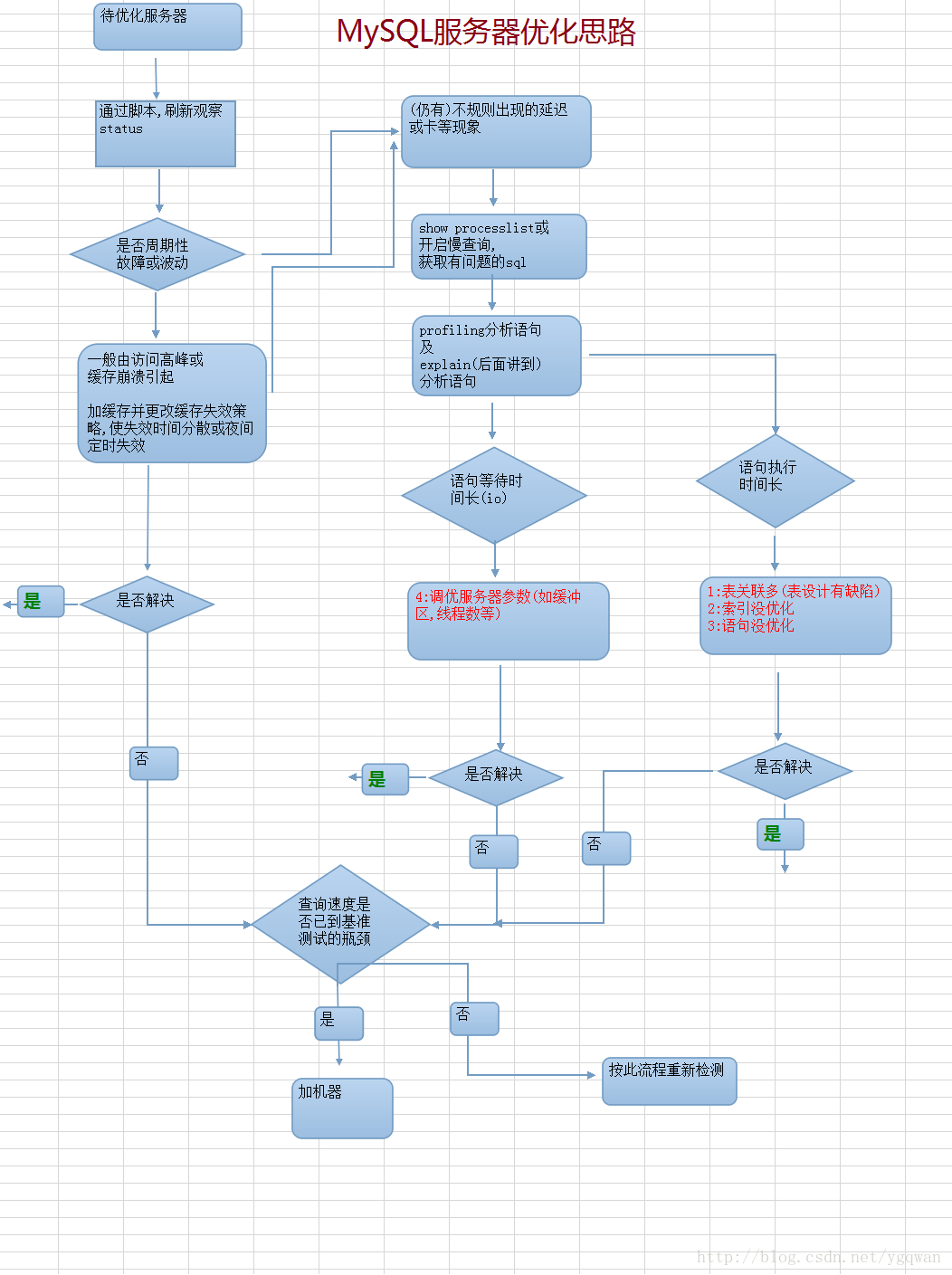
小結:
從數據庫中隨機取一條記錄時,可以把RAND()生成隨機數放在JOIN子查詢中以提高效率。
5、再來看看用ORDRR BY RAND()方式一次取得多個隨機值的方式:
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random order by rand() limit 1000\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_innodb_random
type: index
possible_keys: NULL
key: idx_id
key_len: 4
ref: NULL
rows: 393345
Extra: Using index; Using temporary; Using filesort
[yejr@imysql]> select id from t_innodb_random order by rand() limit 1000;
1000 rows in set (0.41 sec)
全索引掃描,生成排序臨時表,太差太慢了。
6、把隨機數放在子查詢裡看看:
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random where id > (select rand() * (select max(id) from t_innodb_random) as nid) limit 1000\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t_innodb_random
type: index
possible_keys: NULL
key: idx_id
key_len: 4
ref: NULL
rows: 393345
Extra: Using where; Using index
*************************** 2. row ***************************
id: 3
select_type: SUBQUERY
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Select tables optimized away
[yejr@imysql]> select id from t_innodb_random where id > (select rand() * (select max(id) from t_innodb_random) as nid) limit 1000\G
1000 rows in set (0.04 sec)
嗯,提速了不少,這個看起來還不賴:)
7、仿照上面的方法,改成JOIN和隨機數子查詢關聯
復制代碼 代碼如下:
[yejr@imysql]> explain select id from t_innodb_random t1 join (select rand() * (select max(id) from t_innodb_random) as nid) t2 on t1.id > t2.nid limit 1000\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: system
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: t1
type: range
possible_keys: idx_id
key: idx_id
key_len: 4
ref: NULL
rows: 196672
Extra: Using where; Using index
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: No tables used
*************************** 4. row ***************************
id: 3
select_type: SUBQUERY
table: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Select tables optimized away
[yejr@imysql]> select id from t_innodb_random t1 join (select rand() * (select max(id) from t_innodb_random) as nid) t2 on t1.id > t2.nid limit 1000\G
1000 rows in set (0.00 sec)
可以看到,全索引檢索,發現符合記錄的條件後,直接取得1000行,這個方法是最快的。
綜上,想從MySQL數據庫中隨機取一條或者N條記錄時,最好把RAND()生成隨機數放在JOIN子查詢中以提高效率。
上面說了那麼多的廢話,最後簡單說下,就是把下面這個SQL:
復制代碼 代碼如下:
SELECT id FROM table ORDER BY RAND() LIMIT n;
改造成下面這個:
復制代碼 代碼如下:
SELECT id FROM table t1 JOIN (SELECT RAND() * (SELECT MAX(id) FROM table) AS nid) t2 ON t1.id > t2.nid LIMIT n;
就可以享受在SQL中直接取得隨機數了,不用再在程序中構造一串隨機數去檢索了。
1、選取最適用的字段屬性
MySQL 可以很好的支持大數據量的存取,但是一般說來,數據庫中的表越小,在它上面執行的查詢也就會越快。因此,在創建表的時候,為了獲得更好的性能,我們可以將表中字段的寬度設得盡可能小。例如,在定義郵政編碼這個字段時,如果將其設置為CHAR(255),顯然給數據庫增加了不必要的空間,甚至使用VARCHAR這種類型也是多余的,因為CHAR(6)就可以很好的完成任務了。同樣的,如果可以的話,我們應該使用MEDIUMINT而不是BIGIN來定義整型字段。
另外一個提高效率的方法是在可能的情況下,應該盡量把字段設置為NOT NULL,這樣在將來執行查詢的時候,數據庫不用去比較NULL值。
對於某些文本字段,例如“省份”或者“性別”,我們可以將它們定義為ENUM類型。因為在MySQL中,ENUM類型被當作數值型數據來處理,而數值型數據被處理起來的速度要比文本類型快得多。這樣,我們又可以提高數據庫的性能。
2、使用連接(JOIN)來代替子查詢(Sub-Queries)
MySQL 從4.1開始支持SQL的子查詢。這個技術可以使用SELECT語句來創建一個單列的查詢結果,然後把這個結果作為過濾條件用在另一個查詢中。例如,我們要將客戶基本信息表中沒有任何訂單的客戶刪除掉,就可以利用子查詢先從銷售信息表中將所有發出訂單的客戶ID取出來,然後將結果傳遞給主查詢,如下所示:
DELETE FROM customerinfo
WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )
使用子查詢可以一次性的完成很多邏輯上需要多個步驟才能完成的SQL操作,同時也可以避免事務或者表鎖死,並且寫起來也很容易。但是,有些情況下,子查詢可以被更有效率的連接(JOIN).. 替代。例如,假設我們要將所有沒有訂單記錄的用戶取出來,可以用下面這個查詢完成:
SELECT * FROM customerinfo
WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )
如果使用連接(JOIN).. 來完成這個查詢工作,速度將會快很多。尤其是當salesinfo表中對CustomerID建有索引的話,性能將會更好,查詢如下:
SELECT * FROM customerinfo
LEFT JOIN salesinfoON customerinfo.CustomerID=salesinfo.
CustomerID
WHERE salesinfo.CustomerID IS NULL
連接(JOIN).. 之所以更有效率一些,是因為 MySQL不需要在內存中創建臨時表來完成這個邏輯上的需要兩個步驟的查詢工作。
3、使用聯合(UNION)來代替手動創建的臨時表
MySQL 從 4.0 的版本開始支持 UNION 查詢,它可以把需要使用臨時表的兩條或更多的 SELECT 查詢合並的一個查詢中。在客戶端的查詢會話結束的時候,臨時表會被自動刪除,從而保證數據庫整齊、高效。使用 UNION 來創建查詢的時候,我們只需要用 UNION作為關鍵字把多個 SELECT 語句連接起來就可以了,要注意的是所有 SELECT 語句中的字段數目要想同。下面的例子就演示了一個使用 UNION的查詢。
SELECT Name, Phone FROM client
UNION
SELECT Name, BirthDate FROM author......余下全文>>
(1).數據庫設計方面,這是DBA和Architect的責任,設計結構良好的數據庫,必要的時候,去正規化(英文是這個:denormalize,中文翻譯成啥我不知道),允許部分數據冗余,避免JOIN操作,以提高查詢效率
(2).系統架構設計方面,表散列,把海量數據散列到幾個不同的表裡面.快慢表,快表只留最新數據,慢表是歷史存檔.集群,主服務器Read & write,從服務器read only,或者N台服務器,各機器互為Master
(3).(1)和(2)超越PHP Programmer的要求了,會更好,不會沒關系.檢查有沒有少加索引
(4).寫高效的SQL語句,看看有沒有寫低效的SQL語句,比如生成笛卡爾積的全連接啊,大量的Group By和order by,沒有limit等等.必要的時候,把數據庫邏輯封裝到DBMS端的存儲過程裡面.緩存查詢結果,explain每一個sql語句
(5).所得皆必須,只從數據庫取必需的數據,比如查詢某篇文章的評論數,select count(*) ... where article_id = ? 就可以了,不要先select * ... where article_id = ?然後msql_num_rows.
只傳送必須的SQL語句,比如修改文章的時候,如果用戶只修改了標題,那就update ... set title = ? where article_id = ?不要set content = ?(大文本)
(6).必要的時候用不同的存儲引擎.比如InnoDB可以減少死鎖.HEAP可以提高一個數量級的查詢速度