最近遇到業務的一個類似文件系統的存儲需求,對於如何在mysql中存儲一顆樹進行了一些討論,分享一下,看看有沒有更優的解決方案。
一、現有情況
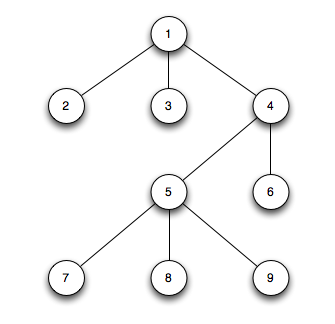
首先,先假設有這麼一顆樹,一共9個節點,1是root節點,一共深3層。(當然實際業務不會這麼簡單)
原有的表結構如下:
id parents_id name full_path 1 0 a /a 2 1 b /a/b 3 1 c /a/c 4 1 d /a/d 5 4 e /a/d/e 6 4 f /a/d/f 7 5 g /a/d/e/g 8 5 h /a/d/e/h 9 5 i /a/d/e/i
需要滿足的幾個基本需求為:
1、從上到下逐層展開目錄層級
2、知道某一個目錄反查其全路徑
3、rename某一個路徑的名字
4、將某一個目錄挪到其他目錄下
現有的表結構可以滿足以上的需求:
、 id parents_id、 full_path id、 name$newname id、 parents_id$new_parents_id,full_path=$new_full_path id$id;(修改父子關系到新的關系上)
但是現有的表結構會遇到的問題就是,第3和第4個需求,其並不是只更新一行即可,由於有full_path的存在,所有被修改的節點,其下面的所有節點的full_path都需要修改。這就無形之間增加了很多寫操作,如果這顆樹比較深,比如有100層,那麼修改第3層的數據,那麼就意味著其下面97層的所有數據都需要被修改,這個產生的寫操作就有些恐怖了。
以列子所示,如果4的name被修改,都會影響4,5,6,7,8,9一共6行數據的更新,這個寫邏輯放大的有點厲害。
namex,full_path id full_path id full_path id full_path id full_path id full_path id;
那麼如何解決這個問題呢?
1、去除full_path字段
上面所述問題最嚴重的就是寫邏輯放大的問題,采用去除full_path字段後,6條update就變成1條update的了。
這個優化看起來完美解決寫邏輯放大問題,但是引入了另一個問題,那就是需求2的滿足費勁了。
原有SQL是:
full_path id$id;
但是去除full_path字段之後,變為:
parents_id id parents_id id $parents_id;
以示例來說,如果要得到9的全路徑,那麼就需要如下SQL
parents_id,name id parents_id,name id parents_id,name id parents_id,name id ;
當最後判斷到parents_id=0的時候結束,然後將所有name聚合在一起。
如果所有操作都需要前端實現,那麼就需要前端和DB交互4次,這期間消耗的鏈接成本會極大的延長總體的響應時間,基本是不可接收的。
如果要采用這種方案,目前看來只有使用存儲過程,將所有計算都在本地完成之後在返回給端,保證一次請求,一次返回,這樣才最效率,但是mysql的存儲過程個人不太建議使用,風險較大。
2、產品規范
我們的問題會發生在樹的層級特別多的情況下,那麼可以通過產品規范來進行限制,比如最深只能有4層,這樣就將問題遏制在發生之前了。(當然,有些時候這種最有效的優化方案是最不可能實現的,產品不會那麼容易妥協)
3、增加cache
問題既然是寫邏輯放大,那麼如果我們將優化思路從降低寫入次數,改為提高寫入性能呢?
我們引入redis這種nosql存儲,將id和full_path存放在redis中,每次更新數據庫之後在更新redis,redis的寫入性能遠高於mysql,這樣問題也可以得到解決。
只不過由於更新不是同步的,采用異步更新之後,數據會最終一致,但是在某一個特殊時間點可能會存在不一致。
並且由於存儲架構變化,需要代碼方面做出一定的妥協,無論是讀操作還是寫操作。
4、整體改變存儲結構
以上方案都是在不大改現有表結構的基礎上做出的,那麼有沒有可能修改表結構之後情況會不一樣呢?
我們對所示例子的存儲結構引入層級的概念,去除full_path,看看是否可以解決問題。
新的表結構如下:
id_name(id和name映射關系)
id name 1 a 2 b 3 c 4 d 5 e 6 f 7 g 8 h 9 i
relation(父子關系)
id chailds depth 1 1 0 1 2 1 1 3 1 1 4 1 1 5 2 1 6 2 1 7 3 1 8 3 1 9 3 2 2 0 3 3 0 4 4 0 4 5 1 4 7 2 4 8 2 4 9 2 5 5 0 5 7 1 5 8 1 5 9 1 6 6 0 7 7 0 8 8 0 9 9 0
這兩張新表第一張不用解釋了,第二張id字段存放節點id,chailds字段存放其所有子節點(並不是直接chaild,而是不論層級都存放),depth字段存放其子節點和本節點的層級關系。
我們看下這麼設計是否可以滿足最初的4個需求:
需求1:逐層展開目錄
id,depth table2 id name table1 id$id;
由於每個id都存放了其所有的子節點,所以如果查詢4的所有下屬目錄,直接select id,depth from table2 where id = 4;一條SQL即可獲得所有結果,只要前端在處理一下即可。
id chailds depth 4 4 0 4 5 1 4 6 1 4 7 2 4 8 2 4 9 2
需求2:根據某一個目錄獲知其全路徑
id,depth table2 chailds $id;
由於每個id都存放了所有子節點,所以反差也是一條sql的事情。比如查詢9的全路徑,那麼select id,depth from table2 where chailds=9;得到的結果應該是
id chailds depth 9 9 0 5 9 1 4 9 2 1 9 3
通過上述結果,前端進行計算處理就可以得到9的全路徑了,並且是一條sql獲得,不需要前端和db多次交互,也不需要引入存儲過程。
需求3:更改目錄名稱
table1 name $new_name id $id ;
這個最簡單了,只需要更改映射表即可。
需求4:更改節點的父子關系
id table2 id$id depth table2 id id table2 id table2 ($sql2_id,$id,$depth);
這個需求目前看來最麻煩,我們以示例所示,如果將5挪到3下面需要經過哪些操作?
I:先查出來5都屬於哪些節點的子節點。
select id from table 2 where id=5 and depth > 0;
id
chailds depth 1 5 2 4 5 1
II:刪除這些記錄。
delete from table2 where id=1 and chailds=5;
delete from table2 where id=4 and chailds=5;
III:查出新父節點是哪些節點的子節點。
select id,depth from table where chailds=3 and depth > 0 ;
id chailds depth 1 3 1
IIII:
根據III的結果插入新的關系。
insert into table2 values (1,5,2);
由於新父節點只是1的子節點,故只需要在增加5和1個關系既可,同時由於3是5的新父節點,那麼5和1的深度關系應該比3的關系“+1”。
而所有5下面的節點都不需要更改,因為這麼設計所有節點都是自己子節點的root,所以只要修改5的關系即可。
但是這個解決方案明顯可以看出來,需要存儲的關系比原有情況多了很多倍,尤其是關系層級深的情況下。
三、總結
目前看來,並沒有什麼特別優秀的方案,都需要付出一定的代價。
ps:本文的思路參考了《SQL反模式》,如果有興趣的讀者可以去研讀一下。