眾所周知,系統讀取數據時,從內存中讀取要比從硬盤上速度要快好幾百倍。故現在絕大部分應用系統,都會最大程度的使用緩存(內存中的一個存儲區域),來提高系統的運行效率。MySQL數據庫也不例外。在這裡,筆者將結合自己的工作經驗,跟大家探討一下,MySQL數據庫中緩存的管理技巧:如何合理配置MySQL數據庫緩存,提高緩存命中率。
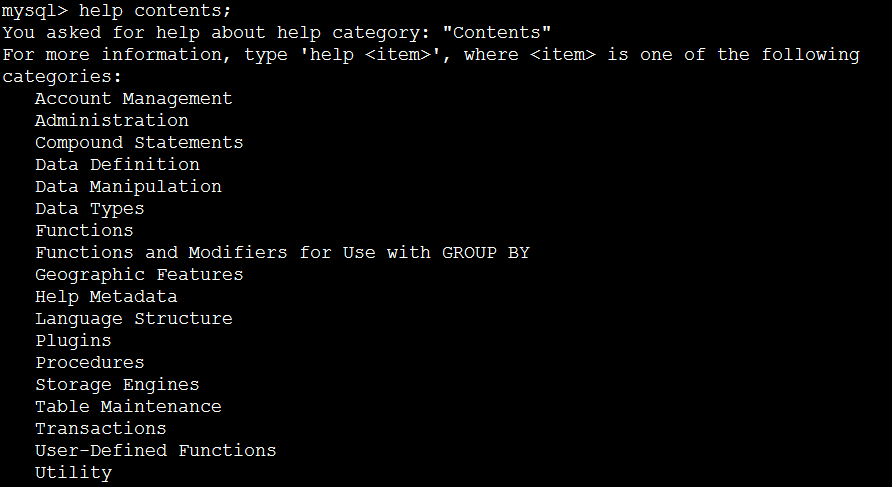
一、什麼時候應用系統會從緩存中獲取數據?
數據庫從服務器上讀取數據時,可以從硬盤的數據文件中獲取數據,也可以從數據庫緩存中讀取數據。現在數據庫管理員需要搞清楚的是,在什麼樣的情況下,系統是從緩存中讀取數據,而不是從硬盤的數據文件中讀取數據?
簡單的說,數據緩存就是內存中的一塊存儲區域,其存儲了用戶的SQL文本以及相關的查詢結果。通常情況下,用戶下次查詢時,如果所使用的SQL文本是相同的,並且自從上次查詢後,相關的紀錄沒有被更新過,此時數據庫就直接采用緩存中的內容。從這個原則中,可以看到如果要直接使用緩存中的數據,至少要滿足以下幾個條件。
一是所采用的SQL文本是相同的。當前後兩次用戶使用了相同的SQL語句(假設不考慮其他條件),則服務器會從緩存中讀取結果,而不需要再去解析和執行SQL語句。這裡需要注意的是,這裡的SQL文本必須一次不差的完全相同。如果前後兩次查詢,使用了不同的查詢條件。如第一次查詢時沒有輸入Where條件語句。後來發現數據量過多,利用了Where條件了過濾查詢的結果。此時即使最後的查詢結果是相同的,系統仍然是從數據文件中獲取數據,而不是從數據緩存中。再如,Select後面所使用的字段名稱也必須是相同的。如果有一個字段名稱不同或者前後兩次查詢所使用的字段數量不同,則系統都會認為是不同的SQL語句,而重新解析並查詢。
二是從數據緩存的角度考慮,大小寫是不敏感的。如前後兩次查詢時,采用的字段名稱可能只有大小寫的差異。如第一次使用的是大小,第二次使用的是小寫,這系統認為仍然是相同的SQL語句。或者說關鍵字大小寫等等這都是不敏感的。
三是要滿足二次查詢之間,數據記錄包括表結構都沒有被更改過。如果記錄所在的標更改了,如增加了一個字段等等,此時使用這個表的所有緩沖數據系統將自動清空。這裡需要注意,這裡指的更改是一個廣義的更改,包括表中任何數據或者結果的改變。舉一個簡單的例子,第一次查詢時用戶需要查詢2010年的出貨數據。查詢後有用戶在這個表中插入了一條2011年1月份的出貨信息。然後又有用戶需要查詢2010年的出貨信息。使用的SQL語句與第一次查詢時完全相同。在這種情況下,數據庫系統會使用緩存中的數據嗎?答案是否定的。因為當中間用戶插入一條記錄時,系統會自動清空跟這個表相關的所有緩存記錄。當第二次查詢時,緩存中已經沒有這張表對應的緩存信息。此時就需要重新解析並查詢。
四是需要注意,默認字符集對緩存命中率的影響。通常情況下,如果客戶端與服務器之間所采用的默認字符集不同,則即使查詢語句相同、在兩次查詢之間記錄與表結構也沒有被更改,系統仍然認為是不同的查詢。對於這一點需要特別的注意,大家比較容易忽視。
二、提高緩存命中率的建議。
從上面的條件分析中可以看出,利用緩存中的數據具有比較嚴格的條件。其實這些條件也是合情合理的。主要是為了保障數據的一致性。對以上這些條件有深入的認識之後,現在數據庫管理員需要考慮的是,如何來提高這個緩存的命中率?對此筆者有如下幾個建議。
一是在配置時,客戶端與服務器端要使用相同的字符集。如果客戶端(或者說第三方工具)與服務器端使用的字符集不同,那麼任何情況下都不會使用緩存功能。特別在國內,需要用到中文的字符集。此時特別需要注意,客戶端默認字符集要與服務器端的默認字符集相同。注意,這裡是相同,而不是兼容。有時候即使采用了不同的字符集,客戶端上仍然可以正常顯示。這主要是因為有些字符集雖然不相同,但是是相互兼容的。在緩存管理上,需要相同,光兼容還不行。
二是在客戶端上,要固化查詢的語句。如現在有財務人員和采購人員同時從系統中查詢11月份的出貨數據。顯然他們崗位職責不同,所需要字段的內容是不同的。此時在客戶端出,可以允許用戶設置自己所需要的表單格式。但是筆者建議,後台所采用的SQL語句最好是相同的。這裡數據會經過三個渠道:後台數據庫、客戶端、用戶。筆者的意識時,後台數據庫與客戶端之間的交互采用相同的SQL語句。然後客戶端與用戶之間進行交互時,根據用戶定義的格式(包括字段前後的排列、不包括查詢條件語句的差異)向用戶顯示數據。此時由於采用了相同的SQL語句(只是用戶對於顯示格式的要求不同),從而可以提高應用系統的查詢效率。
三是提高內存中緩存的配置,來提高命中率。一般在服務器啟動時,操作系統會跟數據庫軟件協商緩存空間的大小。當緩存工作不足時,緩存中最舊的緩存記錄會被最新的消息所覆蓋。可見,如果能夠提高緩存空間,就可以提高命中率。這就好像打靶,目標多了,命中的幾率也會高許多。不過用戶的並發數越多,這個設置的效果會越不明顯。
四是通過分區表可以提高緩存的命中率。在上面的條件分析中,大家可以看到,只要所查詢的表中插入了一條記錄,系統就會清空緩存記錄。現在以查詢出貨記錄為例。出貨記錄表每天都在更新,而用戶在年初時,會經常需要查詢上一年的出貨記錄。此時由於這個表中的數據每個小時都在更新,那麼緩存中的信息會不斷的被情況。此時緩存的命中率顯然不會很高。針對這種情況,筆者建議可以采用分區表。如可以通過系統設置,將2010年的出貨記錄單獨存放在一個出貨的分區表中。即每一個年度都使用一張單獨的分區表。此時2011年的紀錄,就不會影響到2010年的分區表。此時如果用戶重復查詢2010年的出貨信息,只要其使用的SQL語句相同(沒有采用不同的查詢條件),那麼就可以享受緩存機制所帶來的效益,提高應用系統的查詢效果。。
三、多個應用對緩存的影響。