最近在項目的生產環境中使用了mysql-mmm來提高數據庫的可用性和處理能力。在項目初期,mysql-mmm安裝、配置和部署對我們開發人員一直都是透明的。於是一個“美好”的願望開始在心中滋生:我們不需要管理數據庫,一旦有問題就會系統管理人員過來修復。可是,隨著項目的深入,這個願望也在逐步破裂。由於某些開發人員不當操作(當然,開發人員是不應該具有直接操作數據庫的權利的,這是管理上的問題。),導致MySQL Cluster主從狀態不統一,無法完成同步,從而造成主程序無法啟動。這時,我們的最初創建環境的系統管理人員,卻因為其他項目無法抽身,而他當初的警告也讓我們不敢“越雷池半步”。中間的幾次問題,都通過不同的方法臨時解決了:邀請了其他項目組的DBA、寫了腳本定時監控mysql-mmm的狀態等等。可是到了9月30號這一天一切都變了。數據庫又一次毫無征兆的崩潰了。這次更嚴重:一台slave無法啟動,兩台slave無法同步,只剩下master,還在苟延殘喘(這個詞有點過分!)。
難道MySQL Cluster真的有那麼麻煩嗎?終於忍無可忍了,不能再把希望寄托到別人身上!在把主程序的數據庫讀寫都切換到了master上以後,開始嘗試恢復MySQL Cluster的狀態。
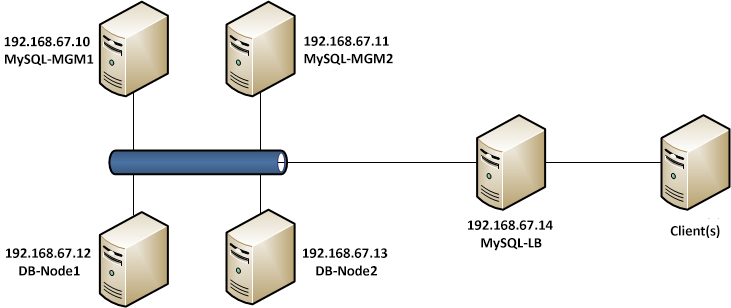
繼續之前,交代一下MySQL Cluster的配置:典型的writer/reader。db01和db02為master,db01,db02都為writer,同時db02還作為reader,db03和db04都是slave,作為reader。其中db04已經無法啟動。
為了防止萬一失敗不會造成更壞的影響,選擇了db04作為練手的對象。
問題1:MySQL無法啟動
現象1:使用service mysql start啟動時,進度一直持續。
備份現有的配置文件my.cnf,重新安裝MySQL。安裝後MySQL啟動正常,將備份的my.cnf,恢復到/etc/,重新啟動MySQL。出現錯誤:
現象2:Starting MySQL. ERROR! Manager of pid-file quit without updating file.
查看/var/lib/mysql/下面的*.err日志,找到相應的提示,根據錯誤提示進行相應的操作。由於現場丟失,只能在這裡給出錯誤原因:
a. 日志文件夾已滿,無法寫入。MySQL的數據文件和日志文件並沒有放在默認的/var/lib/mysql下面,而是另外指定了目錄/opt/mysql/data和/opt/mysql/log。通過df -h和du -h --max-depth=1命令查看,發現該目錄/opt/mysql目錄已經滿了,於是清空了/opt/mysql下面的所有文件,重新啟動,還是同樣的問題
b. 日志文件和數據文件不存在。於是重新創建data(數據)和log(日志)兩個目錄,根據my.cnf裡面的配置,分別將/var/lib/mysql下面的ibdata1和ib_logfile0、ib_logfile1分支復制到數據和日志目錄中。重新啟動,問題依舊。
c. mysql用戶無權讀取data和log目錄。和其他幾台服務器上的目錄比較結合錯誤日志發現,原來上面兩個文件夾是由root用戶創建的,mysql用戶沒有讀寫權限。chown -R mysql.mysql data修改目錄所有者。重新啟動,同樣錯誤信息躍然於眼前。
d. mysql無法在現有的數據文件和日志文件上進行操作。將ibdata1和ib_logfile0、ib_logfile1刪除,重新啟動。終於啟動成功,回到目錄下查看,已經新建了ibdata1和ib_logfile0、ib_logfile1。
問題2:無法導入dump文件。
服務啟動成功後,下面就是按照MySQL-MMM安裝指南進行配置了。從db01上dump出當前的數據庫內容,然後在db04上導入。由於導入是在9月30號下午進行,當時為了不耽誤班車,強行退出了導入進程,就出現這個錯誤 http://blog.csdn.net/mydeman/article/details/6843398。
今天在刪除了一些比較大的並且不再使用的數據庫後(一定要記得備份!!),dump出來的數據文件小了很多,可是在導出過程中直接退出了。通過ps查看,發現mysql已經停止,而且無法重啟。查看錯誤日志,發現如下信息:
[ERROR] /usr/sbin/mysqld: Disk is full writing './myapp/session.MYD' (Errcode: 28). Waiting for someone to free space... (Expect up to 60 secs delay for server to continue after freeing disk space)
原來在導入時,數據庫被創建到了默認的/var/lib/mysql下面,而這個目錄由於分配的空間很小,所以被占滿了。通過mv命令,將除了mysql以外的其他數據庫都移動到/opt/mysql/data/下面,然後通過ln -s建立連接。數據正常啟動,重啟導入進程,Bingo!
問題3:無法完成執行CHANGE MASTER命令。
在db04上數據文件導入完畢,按照MySQL-MMM安裝指南完成後續步驟,啟動SLAVE。然後到mysql-mmm admin節點上通過mmm_control set_online db04,將db04上線。mmm_control show查看狀態一切正常。
安裝恢復db04的步驟,恢復db02和db03。前面的步驟都很順利,可是執行CHANGE MASTER命令時出現了錯誤,日志中的錯誤信息:
Failed to open the relay log '//opt/mysql/log/mysql-bin-slave1.005457' (relay_log_pos 147636219)。
到/var/lib/mysql目錄下,發現其中已經存在了master.info和relay-log.info兩個文件。查看master.info文件,其中還是上一次同步時設置的內容。刪除這兩個文件。重新執行CHANGE MASTER命令。
由於在之前已經安裝了mysql-mmm的組件,因此這次恢復過程沒有涉及到mysql-mmm的配置,這個是接下來要解決的問題
摘自 mydeman的學習日志