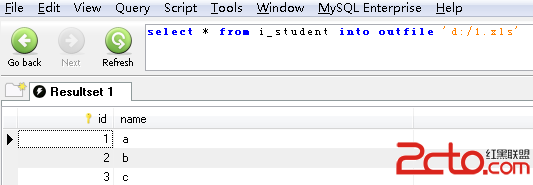
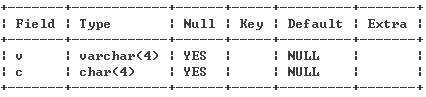
生產環境MySQL Server核心參數的配置 ⑴ lower_case_table_names ● 推薦理由 GNU/Linux 平台,對數據庫、表、存儲過程等對象名稱大小寫敏感 為減少開發人員的開發成本,為此推薦大家設置該參數使對象名稱都自動轉換成小寫 ● 參數介紹 取值范圍: 為0:區分大小寫、Linux 平台默認值 為1:不區分大小寫 Linux安裝的MySQL的配置文件中(/etc/my.cnf)、是沒有lower_case_table_names=1這行的 在Windows安裝的MySQL的配置文件中(my.ini)、是有lower_case_table_names=1這行的 所以、特別提醒下、在 Replication 配置下、Master和Slave中該參數應當保持一致!! ⑵ max_connect_errors ● 推薦理由 一台物理服務器只要連接 MySQL 數據庫服務器 異常中斷累計超過10次,就再也無法連接上mysqld服務 為此建議大家設置此值至少大於等於10 處理方案有 2 : 要麼重啟mysqld、要麼 mysqladmin flush-hosts ● 參數介紹 不過、該參數和安全相關、 某些黑客或許會嘗試失敗來暴力破解密碼、該值如若設置過大會留下可趁之際 ⑶ interactive_timeout和wait_timeout ● 推薦理由 如果你的MySQL Server有大量的閒置連接,他們不僅會白白消耗內存,而且如果連接一直在累加 那麼、最終肯定會達到MySQL Server的連接上限數,這會報'too many connections'的錯誤 推薦值: inactive_timeout=172800 wait_timeout=172800 ● 參數介紹 interactive_timeout 參數含義:服務器關閉交互式連接所等待的秒數 wait_timeout 參數含義:服務器關閉非交互式連接所等待的秒數 ⑷ transaction-isolation和binlog-format 推薦配置 ▼只讀為主的業務應用場景 transaction-isolation=read-commited binlog-format=mixed ▼非只讀為主的業務應用場景 transaction-isolation=repeatabled-read binlog-format=mixed ⑸ innodb_adaptive_hash_index ● 推薦理由 InnoDB引擎會根據數據的訪問頻繁度,把表的數據逐漸緩到內存,若是一張表的數據大量緩存在內存中 則使用 HASH Index 會更高效 InnoDB內有Hash Index機制,監控數據的訪 問情況,可以自動創建和維護一個Hash Index ⑹ innodb_max_dirty_pages_pct ● 推薦理由 InnoDB較之MyISAM,一個重要特性是InnoDB會在內存中開辟一個Buffer Pool來存儲最近訪問的數據塊/索引塊 使得下次再次訪問這個塊時速度能夠很快、當InnoDB對需要修改數據塊的時候 會先記錄修改日志,然後直接對Buffer_Pool中的數據塊的操作 記錄日志是順序寫,對數據塊的操作是內存操作,這讓InnoDB在很多場景下有這很好的速度優勢 上面對內存塊修改完成後,InnoDB就向客戶端返回了 可這時實際磁盤上的數據塊,還並沒有被更新,我們把這樣的page稱為Dirty Page 在InnoDB的後台有一個專門的線程來做將內存數據塊Flush到磁盤的工作 參數innodb_max_dirty_pages_pct可以直接控制了Dirty_Page在Buffer_Pool中所占的比率 一般范圍建議設置為5%~90% 比例設置較小,有利於減少mysqld服務出現問題的時候恢復時間,缺點則是需要更多的物理I/O ● 參數介紹 innodb_max_dirty_pages_pct與檢查點的關系 show innodb status\G;查看檢查點位置 減小innodb_max_dirty_pages_pct、會增加檢查點事件發生的頻率、從而減少髒頁數量 生產環境中、我們經常發現: 數據庫運行一段時間後,經常導致服務器大量的swap 有可能是innodb中的髒數據太多了,因為沒有free space了,mysql通知OS,把一些髒頁交換出去 那麼我們可嘗試減小innodb_max_dirty_pages_pct ⑺ innodb_commit_concurrency ● 推薦理由 參數含義:同一時刻,允許多少個線程同時提交InnoDB事務,默認值為0,范圍0-1000 0:允許任意數量的事務在同一時間點提交 N>0:允許N個事務在同一時間點提交 不過、在mysqld提供服務時、不允許把非0改為0或者把0改為非0、但可以在兩個非0值之間進行變更 ⑻ innodb_fast_shutdown and innodb_force_recovery ● 推薦理由 innodb_fast_shutdown 參數含義:設置innodb引擎關閉的方式,默認值為:1,正常關閉的狀態 0:mysqld服務關閉前,先進行數據完全的清理和插入緩沖區的合並操作 若是髒數據較多或者服務器性能等因素,會導致此過程需要數分鐘或者更長時間 1:正常關閉mysqld服務,針對innodb引擎不做任何其他的操作 2:若是mysqld出現崩潰,立即刷事務日志到磁盤上並且冷關閉mysqld服務 沒有提交的事務將會丟失,但是再啟動mysqld服務的時候會進行事務回滾恢復 innodb_force_recovery 參數含義:mysqld服務出現崩潰之後,InnoDB引擎進行回滾的模式,默認值為0,可設置的值0~6 0:正常的關閉和啟動,不會做任何強迫恢復操作 1:跳過錯誤頁,讓mysqld服務繼續運行。跳過錯誤索引記錄和存儲頁,嘗試用: SELECT * INOT OUTFILE ‘../filename’ FROM tablename;方式,完成數據備份 2:阻止InnoDB的主線程運行。清理操作時出現mysqld服務崩潰,則會阻止數據恢復操作 3:恢復的時候,不進行事務回滾 4:阻止INSERT緩沖區的合並操作。不做合並操作,為防止出現mysqld服務崩潰。不計算表的統計信息 5:mysqld服務啟動的時候不檢查回滾日志:InnoDB引擎對待每個不確定的事務就像提交的事務一樣 6:不做事務日志前滾恢復操作 推薦的參數組合配置: innodb_fast_shutdown = 1 #若是機房條件較好可設置為0(雙路電源、UPS、RAID卡電池和供電系統穩定性) innodb_force_recovery =0 #至於出問題的時候,設置為何值,要視出錯的原因和程度,對數據後續做的操作 ⑼ innodb_additional_mem_pool_size ● 推薦理由 參數含義:開辟一片內存用於緩存InnoDB引擎的數據字典信息和內部數據結構(比如:自適應HASH索引結構) 默認值:build-in版本默認值為:1M;Plugin-innodb版本默認值為:8M; 若是mysqld服務上的表對象數量較多,InnoDB引擎數據量很大,且innodb_buffer_pool_size的值設置較大 則應該適當地調整innodb_additional_mem_pool_size的值 若是出現緩存區的內存不足,則會直接向OS申請內存分配,並且會向MySQL的error log文件寫入警告信息 ⑽ innodb_buffer_pool_size ● 推薦理由 參數含義:開辟一片內存用於緩存InnoDB引擎表的數據和索引 參數最大值:受限於CPU的架構,支持32位還是支持64位,另外還受限於OS為32位還是64位 innodb_buffer_pool_size的值設置合適,會節約訪問表對象中數據的物理IO InnoDB占用的內存,除innodb_buffer_pool_size用於存儲頁面緩存數據外,另外正常情況下還有大約8%的開銷 主要用在每個緩存頁幀的描述、adaptive hash等數據結構,如果不是安全關閉,啟動時還要恢復的話 還要另開大約12%的內存用於恢復,兩者相加就有差不多21%的開銷 所以、在分配innodb_buffer_pool_size時應該多加留意 對於一個專用的DB,理論上可以分到60%-80%的內存給DB. 分到60%-80%是不是就OK了,就不用管了.當然不是了 是不是合適,可以通過show engine innodb status\G; 查看命中情況. 當命中沒達到97%以上,都可以考慮加內存 在保證系統不宕機,不發生內存溢出(OOM),不發生嚴重內存swap,給myisam、其他應用及系統預留一定份額前提下 給innodb分配的buffer越大越好,浪費就浪費點,早晚都能用上的,誰讓內存越來越便宜了呢 ⑾ innodb_flush_log_at_trx_commit AND sync_binlog ● 推薦理由 innodb_flush_log_at_trx_commit = N N=0 – 每隔一秒,把事務日志緩存區的數據寫到日志文件中,以及把日志文件的數據刷新到磁盤上 N=1 – 每個事務提交時候,把事務日志從緩存區寫到日志文件中,並且刷新日志文件的數據到磁盤上 N=2 – 每事務提交的時候,把事務日志數據從緩存區寫到日志文件中;每隔一秒,刷新一次日志文件 但不一定刷新到磁盤上,而是取決於操作系統的調度 sync_binlog = N N>0 — 每向二進制日志文件寫入N條SQL或N個事務後,則把二進制日志文件的數據刷新到磁盤上 N=0 — 不主動刷新二進制日志文件的數據到磁盤上,而是由操作系統決定 推薦配置組合: N=1,1 — 適合數據安全性要求非常高,而且磁盤IO寫能力足夠支持業務,比如充值消費系統 N=1,0 — 適合數據安全性要求高,磁盤IO寫能力支持業務不富余,允許備庫落後或無復制 N=2,0或2,m(0<m<100) — 適合數據安全性有要求,允許丟失一點事務日志,復制架構的延遲也能接受 N=0,0 — 磁盤IO寫能力有限,無復制或允許復制延遲稍微長點能接受,例如:日志性登記業務 ⑿ innodb_file_per_table ● 推薦理由 參數含義:每個表一個表空間 如果設置了便可以明確知道innodb表究竟占多大空間了 表備份方便了,刪除能回收空間 如果是共享表空間, 當你的表多,表空間會撐得很大; 當然隨著表的刪除,也會留下不少空隙 如果是獨立表空間, 在做數據維護的時候也會特別清晰,比如alter table , 結束後會把臨時產生的空間釋放; 而如果是共享表空間,臨時擴大的空間,是不會及時收縮的、可能會存在大量碎片 共享表空間在Insert操作上稍有優勢。其它都沒獨立表空間表現好 ⒀ key_buffer_size ● 推薦理由 對於我們只使用InnoDB引擎的數據庫系統而言,此參數值也不能設置過於偏小 因為臨時表可能會使用到此鍵緩存區空間,索引緩存區推薦:64M ⒁ query_cache_type和query_cache_size ● 推薦理由 query_cache_type=N N=0 —- 禁用查詢緩存的功能 N=1 —- 啟用產訊緩存的功能,緩存所有符合要求的查詢結果集,除SELECT SQL_NO_CACHE.., 以及不符合查詢緩存設置的結果集外 N=2 —- 僅僅緩存SELECT SQL_CACHE …子句的查詢結果集,除不符合查詢緩存設置的結果集外 query_cache_size 查詢緩存設置多大才是合理?至少需要從四個維度考慮: ① 查詢緩存區對DDL和DML語句的性能影響; ② 查詢緩存區的內部維護成本; ③ 查詢緩存區的命中率及內存使用率等綜合考慮 ④ 業務類型 query_cache_size的工作原理: 一個SELECT查詢在DB中工作後,DB會把該語句緩存下來,當同樣的一個SQL再次來到DB裡調用時, DB在該表沒發生變化的情況下把結果從緩存中返回給Client 這裡有一個關建點,就是DB在利用Query_cache工作時,要求該語句涉及的表在這段時間內沒有發生變更 那如果該表在發生變更時,Query_cache裡的數據又怎麼處理呢? 首先要把Query_cache和該表相關的語句全部置為失效,然後在寫入更新 那麼如果Query_cache非常大,該表的查詢結構又比較多,查詢語句失效也慢,一個更新或是Insert就會很慢 所以在數據庫寫入量或是更新量也比較大的系統,該參數不適合分配過大。而且在高並發,寫入量大的系統,建系把該功能禁掉