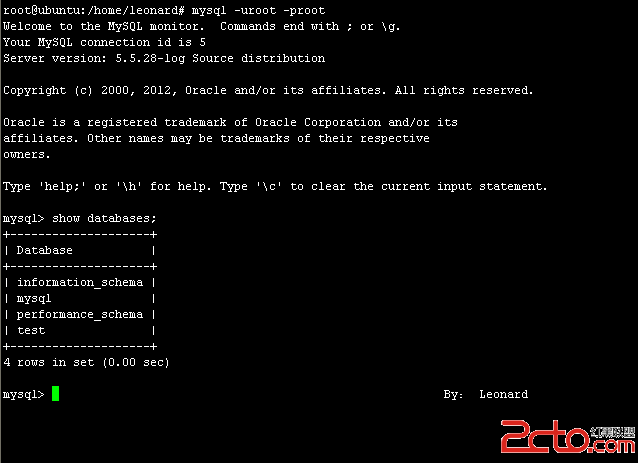
淺析innodb_support_xa與innodb_flush_log_at_trx_commit
很久以前對innodb_support_xa存在一點誤解,當初一直認為innodb_support_xa只控制外部xa事務,內部的xa事務是mysql內部進行控制,無法人為干預(這裡說的內部xa事務主要是指binlog與innodb的redo log保持一致性所采用的內部xa事務)。直到前陣子在微博上看到有人討論mysql數據安全時才仔細去手冊上查看了關於innodb_support_xa的解釋,這幾天又與同事再次討論了這個問題,於是想著還是將其記錄下來。先看官方手冊上對innodb_support_xa的解釋:
“EnablesInnoDBsupport for two-phase commit in XA transactions, causing an extra disk flush for transaction preparation. This set-ting is the default. The XA mechanism is used internally and is essential for any server that has its binary log turned on and is accepting changes to its data from more than one thread. If you turn it off, transactions can be written to the binary log in a different order from the one in which the live database is committing them. This can produce different data when the binary log is replayed in disaster recovery or on a replication slave. Do not turn it off on a replication master server unless you have an unusual setup where only one thread is able to change data.”
從官方解釋來看,innodb_support_xa的作用是分兩類:第一,支持多實例分布式事務(外部xa事務),這個一般在分布式數據庫環境中用得較多。第二,支持內部xa事務,說白了也就是說支持binlog與innodb redo log之間數據一致性。今天的重點是討論第二類內部xa事務。
首先我們需要明白為什麼需要保持binlog與redo log之間數據一致性,這裡分兩個方面來解釋:
第一,保證binlog裡面存在的事務一定在redo log裡面存在,也就是binlog裡不會比redo log多事務(可以少,因為redo log裡面記錄的事務可能有部分沒有commit,這些事務最終可能會被rollback)。先來看這樣一個場景(後面的場景都是假設binlog開啟):在一個AB復制環境下主庫crash,然後進行crash recovery,此時如果binlog裡面的的事務信息與redo log裡面的信息不一致,那麼就會出現主庫利用redo log進行恢復後,然後binlog部分的內容復制到從庫去,然後出現主從數據不一致狀態。所以需要保證binlog與redo log兩者事務一致性。
第二,保證binlog裡面事務順序與redo log事務順序一致性。這也是很重要的一點,假設兩者記錄的事務順序不一致,那麼會出現類似於主庫事務執行的順序是ta, tb, tc,td,但是binlog裡面記錄的是ta,tc, tb, td,binlog復制到從庫後導致主從的數據不一致。當然也由於當初蹩腳的設計導致BGC被打破,這裡就不詳說了。
為了達到上面說的兩點,mysql是怎麼來實現的呢?沒錯,答案是內部xa事務(核心是2pc)。現在mysql內部一個處理流程大概是這樣:
1. prepare ,然後將redo log持久化到磁盤
2. 如果前面prepare成功,那麼再繼續將事務日志持久化到binlog
3. 如果前面成功,那麼在redo log裡面寫上一個commit記錄
那麼假如在進行著三步時又任何一步失敗,crash recovery是怎麼進行的呢? 此時會先從redo log將最近一個檢查點開始的事務讀出來,然後參考binlog裡面的事務進行恢復。如果是在1 crash,那麼自然整個事務都回滾;如果是在2 crash,那麼也會整個事務回滾;如果是在3 crash(僅僅是commit記錄沒寫成功),那麼沒有關系因為2中已經記錄了此次事務的binlog,所以將這個進行commit。所以總結起來就是redo log裡凡是prepare成功,但commit失敗的事務都會先去binlog查找判斷其是否存在(通過XID進行判斷,是不是經常在binlog裡面看到Xid=xxxx?這就是xa事務id),如果有則將這個事務commit,否則rollback。
在這三個步驟中因為持久化需求每一步都需要fsync,但是如果真的每一步都需要fsync,那麼sync_binlog與innodb_flush_log_at_trx_commit兩個參數的意義又在哪?這裡還沒理得很清楚,希望自己以後補上來或是誰幫忙解答一下。
前面已經解釋完了通過內部xa事務來保證binlog裡記錄的事務不會比redo log多(也可以間接的理解為binlog一定只記錄提交事務),這麼做的原因是為了crash recovery後主從保持一致性。接下來解釋目前是怎麼來保證binlog與redo log之間順序一致的。
為什麼要保證binlog裡事務與redo log裡事務順序一致性原因前面已經解釋過。為了保證這一點帶來的問題相信了解過BGC的朋友都知道----臭名昭著的prepare_commit_mutex,沒錯就是它導致了正常情況下無法實現BGC,原理是什麼?在每次進行xa事務時,在prepare階段事務先拿到一個全局的prepare_commit_mutex, 然後執行前面說的持久化(fsync)redo log與binlog,然後等fsync完了之後再釋放prepare_commit_mutex,這樣相當於串行化的效果雖然保證了binlog與redo log之間順序一致性,但是卻導致每個事務都需要一個fsync操作,而大家都知道在一次持久化的過程中代價最大的操作就是fsync了,而想write()這些不落地的操作代價相對來說就很小。所以BGC得核心在於很多事務需要的fsync合並成一個fsync去做。
說了這麼多就只為了解釋innodb_support_xa=1的價值在哪,但是剛才也說了由於xa事務中需要多次fsync,所以開啟後會對性能有一定影響。從percona博客上看到06年他們測試時開啟後tps下降一半,但是我實際用mysql-5.5.12+sysbench-0.5+10塊SAS(raid 10)測試結果性能下面沒那麼明顯。在oltp模式下tps幾乎沒差別,不過它默認讀寫比例是4:1,後來換成純update測試,開始xa事務性能下降也僅僅是5%左右,沒有傳說中那麼大的差別。所以我懷疑可能的原因有兩個:第一,現在的mysql性能相對於06有了較大提升;第二,我測試的機器較好(10塊SAS盤做raid10),這樣即使開啟了xa事務,需要較多的fsync,但是由於存儲方面能抗住,所以沒有體現出太大的劣勢。
接下來順便談一下innodb_flush_log_at_trx_commit意義以及合理設置。innodb_flush_log_at_trx_commit有0、1、2三個值分別代表不同的使redo log落地策略。0表示每秒進行一次flush,但是每次事務commit不進行任何操作(每秒調用fsync使數據落地到磁盤,不過這裡需要注意如果底層存儲有cache,比如raid cache,那麼這時也不會真正落地,但是由於一般raid卡都帶有備用電源,所以一般都認為此時數據是安全的)。1代表每次事務提交都會進行flush,這是最安全的模式。2表示每秒flush,每次事務提交時不flush,而是調用write將redo log buffer裡面的redo log刷到os page cache。
那現在來比較三種策略的優劣勢:1由於每次事務commit都會是redo log落地所以是最安全的,但是由於fsync的次數增多導致性能下降比較厲害。0表示每秒flush,每次事務提交不進行任何操作,所以mysql crash或者os crash時會丟失一秒的事務。2相對於0來說了多了每次事務commit時會有一次write操作,此時數據雖然沒有落地到磁盤但是只要沒有 os crash,即使mysql crash,那麼事務是不會丟失的。2相對於0來說會稍微安全一點點。
所以關於這兩個參數,我的建議是主庫開始innodb_support_xa=1,從庫不開(因為從庫一般不會記binlog),數據一致性還是很重要的。而對於innodb_flush_log_at_trx_commit,除非是對數據很重要,不能丟事務,否則我建議設置成2。我看到有些公司設置成0。其實我個人認為都設置成0了就沒有多少理由不設置成2,因為2帶來的性能損耗是每個事務一個write操作,write操作的開銷相對於fsync還是小很多的,但是這點開銷換來了即使mysql掛掉事務依然不會丟的好處。