在mysql中如果你是模糊查詢的話我們直接使用like即可實現了,當然很多時間like滿足不了我們的需要,我們可以使用正則匹配查詢了,下午我來給大家介紹。
模糊查詢最簡單的方法
在MySQL中我們可以使用LIKE或者NOT LIKE操作符進行比較。在MySQL中模式默認是不區分大小寫的。
查詢示例,student表
+--------+---------+-------+-----------------+---------+
| studid | name | marks | address | phone |
+--------+---------+-------+-----------------+---------+
mysql> select * from student where name like 'm%';
列出在表student中所有以字母M開頭的學生名字。
mysql> select * from student where name like '%e';
列出所有以字母e結尾的學生名字。
代碼如下 復制代碼mysql> select * from student where name like '%a%';
列出在任何地方包含任何特定字母的學生名字。以下的查詢示例將列出包含"a"字母的學生名字。
代碼如下 復制代碼mysql> select * from student where name like '_____';
假如我們要查找的名字包括5個字母,我們就可以使用特殊的字母"_"(下劃線)。將列好在表student中包括5個字母學生的名字。
正則匹配查詢:
由MySQL提供的模式匹配的其他類型是使用擴展正則表達式。當你對這類模式進行匹配測試時,使用REGEXP和NOT REGEXP操作符(或RLIKE和NOT RLIKE,它們是同義詞)。
擴展正則表達式的一些字符是:
“.” 匹配任何單個的字符。
一個字符類“[...]”匹配在方括號內的任何字符。例如,“[abc]”匹配“a”、“b”或“c”。為了命名字符的一個范圍,使用一個“-”。“[a-z]”匹配任何小寫字母,而“[0-9]”匹配任何數字。
“ * ”匹配零個或多個在它前面的東西。例如,“x*”匹配任何數量的“x”字符,“[0-9]*”匹配的任何數量的數字,而“.*”匹配任何數量的任何東西。
正則表達式是區分大小寫的,但是如果你希望,你能使用一個字符類匹配兩種寫法。例如,“[aA]”匹配小寫或大寫的“a”而“[a-zA-Z]”匹配兩種寫法的任何字母。
如果它出現在被測試值的任何地方,模式就匹配(只要他們匹配整個值,SQL模式匹配)。
為了定位一個模式以便它必須匹配被測試值的開始或結尾,在模式開始處使用“^”或在模式的結尾用“$”。
為了說明擴展正則表達式如何工作,上面所示的LIKE查詢在下面使用REGEXP重寫:
為了找出以“b”開頭的名字,使用“^”匹配名字的開始並且“[bB]”匹配小寫或大寫的“b”:
代碼如下 復制代碼mysql> SELECT * FROM pet WHERE name REGEXP “^[bB]“;
+——–+——–+———+——+————+————+
| name | owner | species | sex | birth | death |
+——–+——–+———+——+————+————+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+——–+——–+———+——+————+————+
為了找出以“fy”結尾的名字,使用“$”匹配名字的結尾:
代碼如下 復制代碼mysql> SELECT * FROM pet WHERE name REGEXP “fy$”;
+——–+——–+———+——+————+——-+
| name | owner | species | sex | birth | death |
+——–+——–+———+——+————+——-+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+——–+——–+———+——+————+——-+
為了找出包含一個“w”的名字,使用“[wW]”匹配小寫或大寫的“w”:
代碼如下 復制代碼mysql> SELECT * FROM pet WHERE name REGEXP “[wW]“;
+———-+——-+———+——+————+————+
| name | owner | species | sex | birth | death |
+———-+——-+———+——+————+————+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
+———-+——-+———+——+————+————+
既然如果一個正規表達式出現在值的任何地方,其模式匹配了,就不必再先前的查詢中在模式的兩方面放置一個通配符以使得它匹配整個值,就像如果你使用了一個SQL模式那樣。
為了找出包含正好5個字符的名字,使用“^”和“$”匹配名字的開始和結尾,和5個“.”實例在兩者之間:
代碼如下 復制代碼mysql> SELECT * FROM pet WHERE name REGEXP “^…..$”;
+——-+——–+———+——+————+——-+
| name | owner | species | sex | birth | death |
+——-+——–+———+——+————+——-+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+——-+——–+———+——+————+——-+
你也可以使用“{n}”“重復n次”操作符重寫先前的查詢:
代碼如下 復制代碼mysql> SELECT * FROM pet WHERE name REGEXP “^.{5}$”;
+——-+——–+———+——+————+——-+
| name | owner | species | sex | birth | death |
+——-+——–+———+——+————+——-+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+——-+——–+———+——+————+——-+
如果你使用中文我們可以利用mysql分詞插件來實現模糊查詢了
一、來源
Mysql全文檢索的解析器缺省是按空格切分的,不能直接支持全文檢索中文。從5.1版本開始,Mysql全文檢索的解析器以插件的方式提供。獵兔提供符合Mysql插件格式的中文分詞模塊。
二、環境與安裝
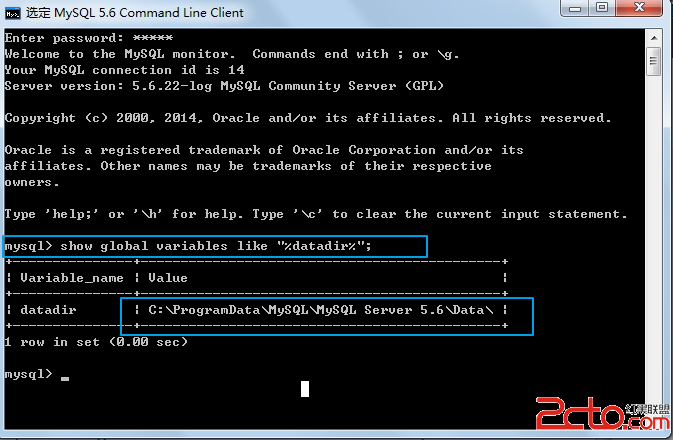
首先下載Mysql5.1版本。然後在gb2312或gbk的環境下啟動Mysql服務。
代碼如下 復制代碼# cd /usr/local/mysql/bin
# ./mysqld-max --user=mysql --default-character-set=gbk
把seg.so拷貝到插件指定的路徑,缺省是 /usr/local/mysql/lib/mysql
代碼如下 復制代碼# cp ./seg.so /usr/local/mysql/lib/mysql/seg.so
把詞典拷貝到Mysql的Data路徑下的Dic子目錄,缺省是 /usr/local/mysql/data/Dic/
進入Mysql:
代碼如下 復制代碼# mysql --default-character-set=gbk
安裝插件:
mysql>INSTALL PLUGIN cn_parser SONAME 'seg.so';
三、使用中文分詞插件
創建表:
代碼如下 復制代碼mysql>CREATE TABLE t (c VARCHAR(255), FULLTEXT (c) WITH PARSER cn_parser) default charset gbk;
mysql>INSERT INTO t VALUES ('測試中文');
mysql>INSERT INTO t VALUES ('老師說明天開會');
mysql> INSERT INTO t VALUES ('購買手機');
查詢:
mysql> SELECT MATCH(c) AGAINST('說明'),c FROM t;
代碼如下 復制代碼+-----------------------------------+-----------------------+
| MATCH(c) AGAINST('說明') | c |
+-----------------------------------+-----------------------+
| 0 | 測試中文 |
| 0 | 老師說明天開會 |
| 0 | 購買手機 |
+-----------------------------------+-----------------------+
3 rows in set (0.00 sec)
mysql> SELECT MATCH(c) AGAINST('說'), c FROM t;
+--------------------------------+-----------------------+
| MATCH(c) AGAINST('說') | c |
+--------------------------------+-----------------------+
| 0 | 測試中文 |
| 0.58370667695999 | 老師說明天開會 |
| 0 | 購買手機 |
+--------------------------------+-----------------------+
3 rows in set (0.00 sec)