淺談MySQL和Lucene索引的比較剖析。本站提示廣大學習愛好者:(淺談MySQL和Lucene索引的比較剖析)文章只能為提供參考,不一定能成為您想要的結果。以下是淺談MySQL和Lucene索引的比較剖析正文
MySQL和Lucene都可以對數據構建索引並經由過程索引查詢數據,一個是關系型數據庫,一個是構建搜刮引擎(Solr、ElasticSearch)的焦點類庫。二者的索引(index)有甚麼差別呢?之前寫過一篇《Solr與MySQL查詢機能比較》,只是簡略的比較了下查詢機能,關於外部道理卻沒有說明,本文簡略剖析下二者的索引差別。
MySQL索引完成
在MySQL中,索引屬於存儲引擎級其余概念,分歧存儲引擎對索引的完成方法是分歧的,本文重要評論辯論MyISAM和InnoDB兩個存儲引擎的索引完成方法。
MyISAM索引完成
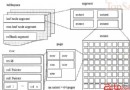
MyISAM引擎應用B+Tree作為索引構造,葉節點的data域寄存的是數據記載的地址。下圖是MyISAM索引的道理圖:

圖1是一個MyISAM表的主索引(Primary key)表示。可以看出MyISAM的索引文件僅僅保留數據記載的地址。在MyISAM中,主索引和幫助索引(Secondary key)在構造上沒有任何差別,只是主索引請求key是獨一的,而幫助索引的key可以反復。B+Tree的一切葉子節點包括一切症結字且是依照升序分列的。
MyISAM表的索引和數據是分別的,索引保留在”表名.MYI”文件內,而數據保留在“表名.MYD”文件內。
MyISAM的索引方法也叫做“非集合”的,之所以這麼稱謂是為了與InnoDB的集合索引辨別。
InnoDB索引完成
固然InnoDB也應用B+Tree作為索引構造,但詳細完成方法卻與MyISAM判然不同。
第一個嚴重差別是InnoDB的數據文件自己就是索引文件。從上文曉得,MyISAM索引文件和數據文件是分別的,索引文件僅保留數據記載的地址。而在InnoDB中,表數據文件自己就是按B+Tree組織的一個索引構造,這棵樹的葉節點data域保留了完全的數據記載。這個索引的key是數據表的主鍵,是以InnoDB表數據文件自己就是主索引。

圖2是InnoDB主索引(同時也是數據文件)的表示圖,可以看到葉節點包括了完全的數據記載。這類索引叫做集合索引。由於InnoDB的數據文件自己要按主鍵集合,所以InnoDB請求表必需有主鍵(MyISAM可以沒有),假如沒有顯式指定,則MySQL體系會主動選擇一個可以獨一標識數據記載的列作為主鍵,假如不存在這類列,則MySQL主動為InnoDB表生成一個隱含字段作為主鍵,這個字段長度為6個字節,類型為長整形。
第二個與MyISAM索引的分歧是InnoDB的幫助索引data域存儲響應記載主鍵的值而不是地址。換句話說,InnoDB的一切幫助索引都援用主鍵作為data域。例如,圖3為界說在Col3上的一個幫助索引:

這裡以英文字符的ASCII碼作為比擬原則。集合索引這類完成方法使得按主鍵的搜刮非常高效,然則幫助索引搜刮須要檢索兩遍索引:起首檢索幫助索引取得主鍵,然後用主鍵到主索引中檢索取得記載。
懂得分歧存儲引擎的索引完成方法關於准確應用和優化索引都異常有贊助,例如曉得了InnoDB的索引完成後,就很輕易明確為何不建議應用太長的字段作為主鍵,由於一切幫助索引都援用主索引,太長的主索引會令幫助索引變得過年夜。再例如,用非單調的字段作為主鍵在InnoDB中不是個好主張,由於InnoDB數據文件自己是一顆B+Tree,非單調的主鍵會形成在拔出新記載時數據文件為了保持B+Tree的特征而頻仍的決裂調劑,非常低效,而應用自增字段作為主鍵則是一個很好的選擇。
講MySQL索引的完成的文章許多,以上也是參考了《MySQL索引面前的數據構造及算法道理》,如今來看看Lucene的索引道理。
Lucene索引完成
Lucene的索引不是B+Tree組織的,而是倒排索引,Lucene的倒排索引由Term index,Team Dictionary和Posting List構成。

有倒排索引(invertedindex)就有正排索引(forwardindex),正排索引就是文檔(Document)和它的字段Fields正向對應的關系:
DocID
name
sex
age
1
jack
男
18
2
lucy
女
17
3
peter
男
17
倒排索引是字段Field和具有這個Field的文檔對應的關系:
Sex字段:
男
[1,3]
女
[2]
Age字段:
18
[1]
17
[2,3]
Jack,lucy或許17,18這些叫做term,而[1,3]就是posting list。Posting list就是一個int型的數組,存儲了一切相符某個term的文檔id。那末甚麼是Term index和Term dictionary?
如上,假定name字段有許多個term,好比:Carla,Sara,Elin,Ada,Patty,Kate,Selena
假如依照如許的次序分列,找出某個特定的term必定很慢,由於term沒有排序,須要全體過濾一遍能力找出特定的term。排序以後就釀成了:Ada,Carla,Elin,Kate,Patty,Sara,Selena
如許便可以用二分查找的方法,比全遍歷更快地找出目的的term。若何組織這些term的方法就是 Term dictionary,意思就是term的字典。有了Term dictionary以後,便可以用比擬少的比擬次數和磁盤讀次數查找目的。然則磁盤的隨機讀操作依然長短常昂貴的,所以盡可能少的讀磁盤,有需要把一些數據緩存到內存裡。然則全部Term dictionary自己又太年夜了,沒法完全地放到內存裡。因而就有了Term index。Term index有點像一本字典的年夜的章節表。好比:
A開首的term ……………. Xxx頁
C開首的term ……………. Xxx頁
E開首的term ……………. Xxx頁
假如一切的term都是英文字符的話,能夠這個term index就真的是26個英文字符表組成的了。然則現實的情形是,term未必都是英文字符,term可所以隨意率性的byte數組。並且26個英文字符也未必是每個字符都有均等的term,好比x字符開首的term能夠一個都沒有,而s開首的term又特殊多。現實的term index是一棵trie 樹:

上圖例子是一個包括 "A", "to", "tea", "ted", "ten", "i", "in", 和 "inn" 的trie樹。這棵樹不會包括一切的term,它包括的是term的一些前綴。經由過程term index可以疾速地定位到term dictionary的某個offset,然後從這個地位再往後次序查找。再加上一些緊縮技巧(想懂得更多,搜刮 Lucene Finite State Transducers),Term index的尺寸可以只要一切term的尺寸的幾非常之一,使得用內存緩存全部term index釀成能夠。
全體下去說就是如許的後果:

由Term index到Term Dictionary,再到Posting List,經由過程某個字段的症結字去查詢成果的進程就比擬清晰了,經由過程多個症結字的Posting List停止AND或許OR停止交集或許並集的查詢也簡略了。
比較MySQL的B+Tree索引道理,可以發明:
1)Lucene的Term index和Term Dictionary其實對應的就是MySQL的B+Tree的功效,為症結字key供給索引。Lucene的inverted index可以比MySQL的b-tree檢索更快。
2)Term index在內存中是以FST(finite state transducers)的情勢保留的,其特色長短常節儉內存。所以Lucene搜刮一個症結字key的速度長短常快的,而MySQL的B+Tree須要讀磁盤比擬。
3)Term dictionary在磁盤上是以分block的方法保留的,一個block外部應用公共前綴緊縮,好比都是Ab開首的單詞便可以把Ab省去。如許Term dictionary可以比B-tree更勤儉磁盤空間。
4)Lucene對分歧的數據類型采取了分歧的索引方法,下面剖析是針對field為字符串的,好比針對int,有TrieIntField類型,針對經緯度,便可以用GeoHash編碼。
5)在 Mysql中給兩個字段自力樹立的索引沒法結合起來應用,必需春聯合查詢的場景樹立復合索引,而Lucene可以任何AND或許OR組合應用索引停止檢索。
以上就是小編為年夜家帶來的淺談MySQL和Lucene索引的比較剖析的全體內容了,願望對年夜家有所贊助,多多支撐~