淺談innodb的索引頁結構,插入緩沖,自適應哈希索引。本站提示廣大學習愛好者:(淺談innodb的索引頁結構,插入緩沖,自適應哈希索引)文章只能為提供參考,不一定能成為您想要的結果。以下是淺談innodb的索引頁結構,插入緩沖,自適應哈希索引正文
Physical Structure of an InnoDB Index
所有的innodb索引都是btree索引,索引記錄保存在葉子上,默認的索引頁大小是16K。當有新的記錄插入時,innodb出於對將來的insert和update操作的考慮,會嘗試留下1/16的空閒頁大小。
如果索引記錄是完全按照索引記錄的大小順序插入的,那麼索引也將填滿整個頁大小的15/16,如果插入順序完全隨機,那麼索引頁基本上填充為1/2至15/16自建。如果填充因子低於1/2,innodb會嘗試重建b-tree。
Mysql5.6以後,可以通過innodb_page_size參數設置當前實例下每個索引頁的大小,一旦設定,無法再更改回來。推薦的配置一般是16K,8K或者4K。另外假如一個Mysql實例設置了不同於默認值的innodb_page_size A,那麼將無法使用其他不同於A值的實例上的文件(比如做一個物理備份和恢復)
Insert Buffering
數據庫應用通常按照主鍵順序插入的,在這種情況下,因為聚集索引的順序和這個主鍵值的順序完全一致,insert操作將會減少很多的隨機IO。
另一方面,二級索引通常不是唯一的,那麼在二級索引中插入數據時是一個相對隨機的順序。同樣的,delete和update操作在影響數據頁時,涉及到索引的變更,在二級索引上也並不是緊挨著的。這就導致了大量的隨機IO。
當插入一條記錄,或者從非唯一的二級索引刪除一條記錄,innodb首先會去檢查該二級索引頁是否在緩沖池中。如果在緩沖池,innodb將會直接在內存中修改這個索引頁。如果該索引也不在緩沖池,那麼innodb將會將這個修改記錄到插入緩沖,也就是insertbuffer。Insert buffer通常都比較小,所以能夠保證全部在緩沖池中,並且更新非常頻繁。這個修改的進程就是change buffering(通常情況下,它只會只作用於insert操作,所以也被稱為insertbuffering,而該數據結構就是insert buffer)
Disk I/O for Flushing the Insert Buffer
那麼插入緩沖如何減少隨機IO的呢?每個一段時間,insert buffer會去合並在insertbuffer中的二級非唯一索引。通常情況下,它會合並N個修改到同一個btree索引的索引頁中,從而節約了很多IO操作。經測試,insertbuffer可以提高15倍的插入速度。
在事務提交後,insert buffer可能還在合並寫入。所以,假如當DB異常重啟,reovery階段,當有非常多的二級索引需要更新或插入時,insert buffer將可能花費很長時間,甚至幾個小時。在這個階段,磁盤IO將會增加,那麼就會導致disk-bound類型的查詢有顯著的性能下滑。
Adaptive Hash Indexes
自適應哈希索引(AHI)使得innodb在緩沖池擁有足夠的內存和某些工作負載下,看起來更像一個內存數據庫,並且不會犧牲任何事務的特點和穩定性。這個特色由參數innodb_adaptive_hash_index控制,動態參數,默認為on表示打開自適應哈希索引,關閉AHI後內置哈希表將會被立馬清空,而正常的操作依舊可以繼續,只是直接通過訪問B-TREE索引。重新使能AHI後哈希表又會被重建。
通過觀察搜素模式,mysql會利用index key的前綴建立哈希索引,這個前綴可以是任意長度,並且它可能僅僅是B-tree上的某些值,而不是整個b-tree。哈希索引通過檢測,會在經常被訪問的index pages上建立哈希索引。
如果一個表幾乎大部分都在緩沖池中,那麼建立一個哈希索引能夠加快等值查詢,通過將btree的索引值轉換成一個排序指針。Innodb有這個機制,可以監控索引的搜索情況,如果它注意到有些查詢通過建立哈希索引可以優化查詢,那麼它會自動建立,所以說它是“自適應的”。
在某些工作負載下,通過哈希索引查找帶來的性能提升價值遠大於這個額外的監控索引搜索情況和保持這個哈希表結構所帶來的開銷。但某些時候,在負載較高的情況下,自適應哈希索引中添加的read/write 鎖也會帶來競爭,比如高並發的join操作。Like操作和%的通配符同樣不適用於AHI。如果工作負載不適合AHI,建議將它關閉,以免帶來不必要的性能開銷。因為mysql內部很難預示在一個特定的場合下AHI到底是否合適,推薦做一個實際工作負載的壓測(有無AHI兩種情況)。在5.6及以後版本中將會考慮讓越來越多的工作負載最好disable掉自適應哈希索引,盡管目前而言它默認還是開啟的。
哈希索引的創建往往是基於現有的b-tree,innodb可以通過觀察b-tree的搜索情況建立任意長度的b-tree索引前綴的方式建立哈希索引。一個哈希索引可以只是部分的,僅包括b-tree index中最經常被訪問到的頁。
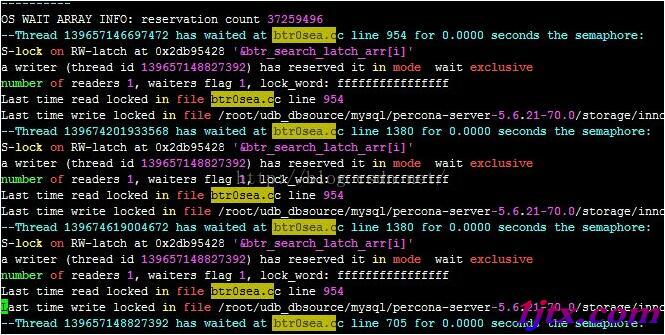
你可以通過觀察show engine innodb status結果中的SEMAPHORES部分來決定是否使用自適應哈希索引。如果你看到很多線程都在btr0sea.c文件上創建rw-latch上waiting,那麼建議關閉掉自適應哈希索引。本人曾經碰到過的一個case截圖如下,典型的高並發模式下AHI引起的競爭,需要關閉AHI
以上這篇淺談innodb的索引頁結構,插入緩沖,自適應哈希索引就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持。