檢查點的主要目的是以對數據庫的日常操作影響最小的方式刷新髒塊,以保障數據庫數據的一致性以及實例崩潰時可快速恢復。隨著業務的不斷運行,髒塊不斷的產生,Oracle又是如何將髒塊刷新到磁盤中去呢?
在8i之前,Oracle定期的鎖住所有的修改操作,刷新Buffer cache中的所有髒塊,這種刷新髒塊的方式被稱為完全檢查點,這極大的影響了效率,從9i之後只有當關閉數據庫時才會發生完全檢查點。
從8i開始,Oracle增加了增量檢查點的概念,增量檢查點的主要宗旨就是定期的刷新一部分髒塊。將髒塊一次刷新完是不合理的,因為髒塊不斷產生,沒有窮盡。像完全檢查點那樣停止用戶所有的修改操作,將髒塊刷新完再繼續,這絕對會極大的影響性能。所有增量檢查點的一次刷新部分塊是髒塊問題的最好解決辦法。那麼,每次刷新時,都刷新那些塊呢?根據統計研究,根據塊變髒的順序,每次刷新那些最早髒的塊,這種方式最為合理。為了實現這一點,Oracle在Buffer cache中又建立了一個鏈表,就是檢查點隊列。每個塊在它變髒時,會被鏈接到檢查點隊列的末尾。就好像排隊一樣,9:00來的人站在第一位,9:05來的人排第二位,以後每來一個人都站在隊伍的末尾,這個隊伍就是按來到的時間順序排列的一個隊列。檢查點隊列就是這樣,塊在變髒時會被鏈到末尾。因此檢查點隊列是按塊變髒的時間順序,將塊排成了一個隊列。
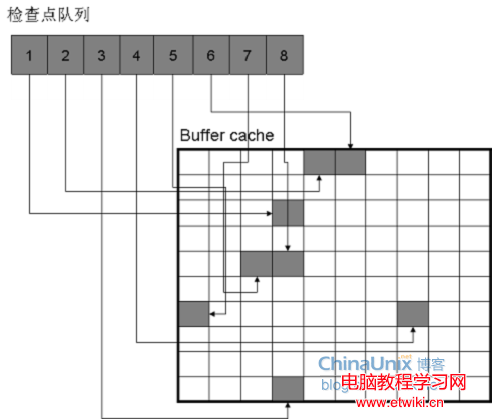
如上圖,檢查點隊列中的每一節點,都指向一個髒塊。檢查點隊列每個節點中的信息其實非常少,就是記錄對應塊在Buffer cache中的地址,髒塊對應的重做記錄在日志文件中的位置,另外還有前一個節點、後一個節點的地址。檢查點隊列還有LRU、髒LRU,這些都是雙向鏈表。雙向鏈表就是在節點中記錄前、後兩個節點的地址。
檢查點隊列頭部的塊是最早變髒的,因此,Oracle會定期喚醒DBWn從檢查點隊列頭開始,沿著檢查點隊列的順序,刷新髒塊。在刷新髒塊的同時,仍可以不斷的有新的髒塊被鏈接到檢查點隊列的尾部。這個定期喚醒DBWn刷新髒塊的操作,Oracle就稱為增量檢查點。
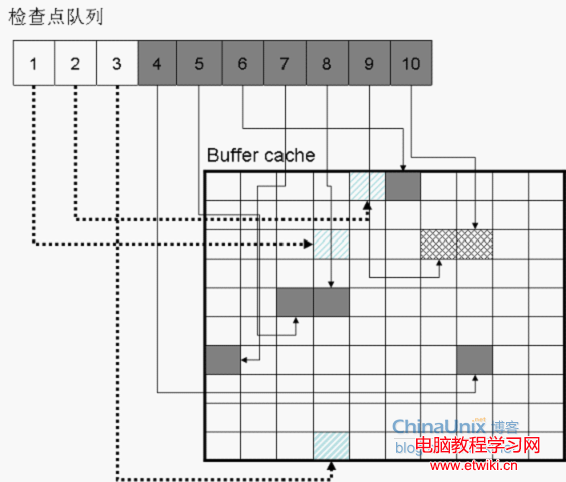
如上圖,1、2、3號節點所指向的髒塊已經被刷新為干淨塊。同時,又有兩個塊變髒,它們被鏈接到了檢查點隊列的末尾,它們是9號、10號節點。
檢查點隊列的頭,又被稱為檢查點位置,Checkpoint postion,這些名稱我們不必從字面上去理解。總之,檢查點位置就是檢查點隊列頭。檢查點隊列頭節點(也就是檢查點位置)的信息,Oracle會頻繁的將它記錄到控制文件中,而且會很頻繁的記錄。一般是每隔三秒,有一個專門的進程CKPT,會將檢查點位置記錄進控制文件。
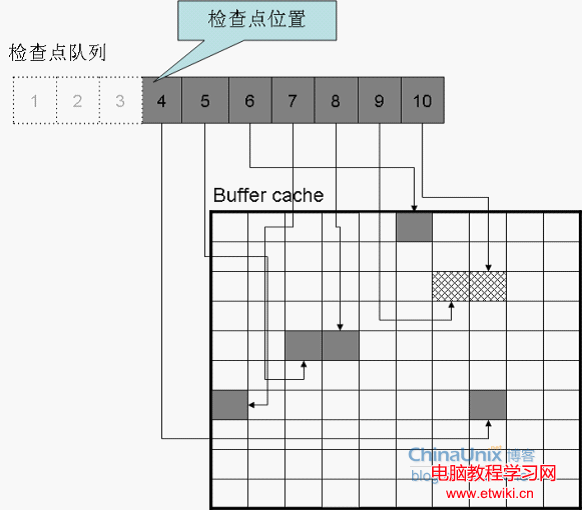
如上圖,當前的檢查點位置是檢查點隊列的1號節點。又一個三秒到了,CKPT進程啟動,將新的檢查點位置記入控制文件:
新的檢查點位置是4號節點,它對應當前變髒時間最早的髒塊。1、2、3號節點已經從檢查點隊列中摘除了。因為它們對應的髒塊已經不髒了。一般來說,控制文件中的檢查點位置之後的塊都是髒塊。但是有時也例外,因檢查點位置每三秒才會更新一次,就像上圖,1、2、3號節點對應的髒塊已經被刷新過了,但是由於三秒間隔沒到,檢查點位置還是指向1號節點。只有當三秒到後,檢查點位置才會被更新到4號節點上。
關於檢查點隊列、檢查點位置我們先說到這裡,在全面的介紹什麼是增量檢查點之前,我們先說一下檢查點隊列的一個重要作用。
讓我們先來總結一下用戶修改塊時,Oracle內部都發生了什麼:
1.如果塊不在Buffer cache,將塊讀入Buffer cache
2.先生成重做記錄,並記入日志緩存,在用戶提交時寫到日志文件中
3.在Buffer cache中修改塊
4.在Buffer cache中設置塊的髒標志位,標志塊變成髒塊,同時在檢查點隊列末尾增加一個新節點,記錄這個新髒塊的信息,信息包括:髒塊在Buffer cache中的位置,在步驟2時生成的與此髒塊對應的重做記錄位置。
5.用戶提交後,將相應的重做記錄從重做緩存寫入日志文件。
我現在將日志補充到上面的圖中:
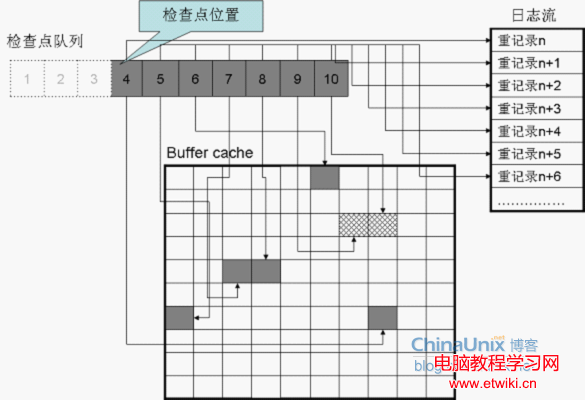
就像上圖,檢查點隊列的每個節點,都保存有髒塊的地址和髒塊對應的重做記錄的編號。髒塊在Buffer cache中的位置是隨機的,用戶不一定修改那個塊。但重做記錄是順序生成的,就和檢查點隊列的排列順序一樣。因為,它們都是當塊被修改而變髒時產生的。塊A先被修改,塊A的重做記錄就排在前面,塊B後被修改,塊B對應的重做記錄會被排在塊A對應的重做記錄的後面。和它們在檢查點中的順序是一樣。每當數據庫因異外而當機,比如異常死機、斷電等等,Buffer cache中有許多髒塊沒來的及寫到磁盤上。以圖為例,比如說現在斷電了,現在磁盤上還有7個髒塊,它們裡面有用戶修改過的數據,Oracle已經將反饋信息“你的修改完成”發送給用戶,用戶也以為他們的修改完成了,將為一直保存到數據庫中。但是,斷然的斷電,令這幾個髒塊中的數據丟失了,它們沒來得及寫到磁盤上。
Oracle如何解決這個問題呢?很簡單,當數據庫重新啟動時,Oracle只需從控制文件中讀出檢查點位置,檢查點位置中記錄有重做記錄編號,根據此編號,Oracle可以很快的定位到日志文件中的重做記錄n,它讀出重做記錄n中的重做數據,將用戶的修改操作重現到數據庫。接著,Oracle讀取重做記錄n+1中的重做數據,重現用戶修改,這個過程將沿著日志流的順序,一直進行下去,直擋最後一條重做記錄,在上圖的例子中,最後一條重做記錄是第n+6條。這個過程完成後,用戶所有的修改又都被重現了,一點都不會丟失。只要你的日志文件是完整,日志流是完整的,就一點信息都不會丟失。
有人可能會有一個問題,重做記錄在生成後,也是先被送進重做緩存,再由重做緩存寫往日志文件。這樣的機制下,一定會有某些重做記錄在沒來的及寫到日志文件中時,數據庫突然當機,而造成這些重做記錄丟失。這樣,這些重做記錄所對應的髒塊,將得不到恢復。用戶還是會丟失一些數據。
這種情況的確會發生,但丟失的都是沒用的信息。為什麼這麼說的。Oracle會在用戶每次發出提交命令時,將事務所修改髒塊對應的重做記錄寫進日志文件,只有當這個操作完成時,用戶才會收到“提交完成”,這樣的信息,對於一個完整的事務,當用戶看到提交完成後,也就意味著所對應的重做記錄一定被寫到了日志文件中,即使發生異常死機,它也是絕對可以恢復。而當用戶沒有提交,或沒來得及提交,數據庫就崩潰了,那麼事務就是不完整的,這個事務必須被回滾,它根本用不著恢復。對於這樣不完整的事務,它對應的重做記錄有可能丟失,但這無所謂了,因為不完整的事務根本不需要恢復。也就是說,只有用戶的事務提交了,用戶的修改一定不會丟失。不過這還有一個前提,就是日志文件千萬不能損壞,DBA所要做的就是要保證日志文件不能損壞。DBA可以使用RAID1這樣的磁盤鏡像技術,或者多元備份日志文件,等等,這個我們在前面章節中已經講過了的。
我們上面所講到的這種恢復,是自動進行的,並且不需要DBA參與,它被稱之為實例恢復。
檢查點隊列與增量檢查點的作用我們已經說的差不多了,它們的主要目的就是讓DBWn沿檢查點隊列的順序刷新髒塊。還有,就是實例恢復。