初學Oracle時,你可能會對Oracle中PGA和UGA兩者間的區別產生疑問,這裡就PGA和UGA兩者間的區別發表下個人意見,在這裡拿出來和大家分享一下。
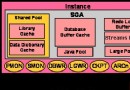
The Process Memory除SGA(System Global Area)之外,Oracle進程還使用下面三個全局區:
The Process Global Area (PGA);
The User Global Area (UGA);
The Call Global Area (CGA)。
實際上PGA和UGA兩者間的區別跟一個進程和一個會話之間的區別是類似的。盡管說進程和會話之間一般都是一對一的關系,但實際上比這個更復雜。一個很明顯的情況是MTS配置,會話往往會比進程多得多。在這種配置下,每一個進程會有一個PGA,每一個會話會有一個UGA。PGA所包含的信息跟會話是無任何關聯的,而UGA包含的信息是以特定的會話為基礎的。
The PGA:進程全局區(PGA)即可以理解為Process Global Area,也可以理解為Program Global Area。它的內存段是在進程私有區(Process Private Memory)而不是在共享區(Shared Memory)。它是個全局區意味著它包含了所有代碼有可能進入的全局變量和數據結構,但是它是不被所有進程共享的。每個Oracle的服務器進程都包含有屬於自己的PGA,它只包含了本進程的相關特定信息。PGA中的結構不需要由latches來保護,因為其它的進程是不能進入到這裡面來訪問的。
PGA包含的是有關進程正在使用的操作系統資源信息以及進程的狀態信息,而其它的進程所使用的Oracle的共享資源是在SGA中。PGA是私有的而不是共享的,這個機制是有必要的,因為當進程死掉後可以把這些資源清除和釋放掉。
PGA包含兩個主要區域:Fixed PGA和Variable PGA或稱為PGA Heap。 Fixed PGA的作用跟Fixed SGA是類似的,都包含原子變量(不可分的),小的數據結構和指向Variable PGA的指針。
Variable PGA是一個堆。它的Chunks可以從Fixed Table X$KSMPP查看得到,這個表的結構跟前面有提到的X$KSMSP是相同的。PGA HEAP包含了一些有關Fixed Table的永久性內存,它跟某些參數的設置有依賴關系。這些參數包含DB_FILES,LOG_FILES,CONTROL_FILES。
The UGA:UGA(User Global Area)包含的是特定會話的信息,有如下一些:
所打開游標的持續和運行時間內的區域;
包的狀態信息,特定的變量;
Java會話狀態;
可以用的ROLES;
被ENABLE的跟蹤事件;
起作用的NLS參數設置;
打開的DBLINK;
會話的入口控制。
跟PGA一樣,UGA也由兩區組成:Fixed UGA和Variable UGA,也稱為UGA HEAP。 Fixed UGA包含了大約70個原子變量,小的數據結構和指向Variable UGA的指針。
UGA HEAP中的Chunks可以從它們自己的會話中通過查看表X$KSMUP獲得相關信息,這個表的結構跟X$KSMSP是一樣的。UGA HEAP包含了一些有關fixed tables的永久性內存段,跟一些參數的設置有依賴關系。這些參數有OPEN_CURSORS,OPEN_LINKS,和MAX_ENABLE_ROLES。
UGA在內存中的位置依賴於會話的配置方式。如果會話連接的配置方式是專用服務器模式(DDS)即是一個會話對應一個進程,則UGA是放在PGA中的。在PGA中,Fixed UGA是其中的一個Chunk,而UGA HEAP是PGA的一個子堆(Subheap)。如果會話連接是配置為共享服務器模式(MTS), Fixed UGA是SHARED POOL中的一個Chunk,而UGA HEAP則是SHARED POOL中的子堆(Subheap)
The CGA:
跟其它的全局區不同,Call Global Area是短暫性存在的。它只有在調用數據期間存在,一般是在對實例的最低級別的調用時才需要CGA,如下:
分析一個SQL語句;
執行一個SQL語句;
取出一個SELECT語句的輸出。
一個單獨的CGA在遞歸調用時是需要的。在SQL語句的分析過程中,對數據字典信息的遞歸調用是需要的,因為要對SQL語句進行語法分析,還有在語句的優化期間要計算執行計劃。執行PL/SQL塊時在處理SQL語句的執行時也是需要遞歸調用的,在DML語句的執行時要處理觸發器執行也是需要遞歸調用的。
不管UGA是放在PGA中還是在SGA中,CGA都是PGA的一個子堆(Subheap)。這個事實的一個重要推論是在一個調用的期間會話必須是一個進程。對於在一個MTS的Oracle數據庫進程應用開發時關於這一點的理解是很重要的。如果相應的調用較多,就得增加processes的數量以適應調用的增加。
沒有CGA中的數據結構,CALLS是沒法工作的。而實際上跟一次CALL相關的數據結構一般都是放在UGA中,如SQL AREA,PL/SQL AREA和SORT AREA它們都必須在UGA中,因為它們要在各CALLS之間要一直存在並且可用。而CGA中所包含的數據結構是要在一次CALL結束後能夠釋放的。例如CGA包含了關於遞歸調用的信息,直接I/O BUFFER等還有其它的一些臨時性的數據結構。
Java Call Memory也是在CGA中。這一段內存比Oracle的其它內存段管理得更密集。它分成三個Space: Stack Space, New Space, Old Space。在New Space和Old Space中不再被參考使用的Chunks,根據它們在使用期間的長度及SIZE的不同,在調用的執行過程中將被當成不用的Chunks收集起來。New Space Chunks很多次的不用的Chunks的反復收集過程中沒有被收集的Chunks將會被放到Old Space Chunks中。這是在Oracle內存管理中唯一的一個廢物收集(garbage collection),其它的Oracle內存段都是釋放Dead Chunks。