1.1 數據庫環境配置原則
1.1.1 操作系統環境:
對於中小型數據庫系統,采用Linux操作系統比較合適,對於數據庫冗余要求負載均衡能力要求較高的系統,可以采用Oracle9i RAC的集群數據庫的方法,集群節點數范圍在2—64個。對於大型數據庫系統,可以采用Sun Solaris SPARC 64位小型機系統或HP 9000 系列小型機系統。RAD5 適合只讀操作的數據庫,RAD1 適合OLTP數據庫
1.1.2 內存要求
對於Linux操作系統下的數據庫,由於在正常情況下Oracle對SGA的管理能力不超過1.7G。所以總的物理內存在4G以下。SGA的大小為物理內存的50%—75%。對於64位的小型系統,Oracle數據庫對SGA的管理超過2G的限制,SGA設計在一個合適的范圍內:物理內存的50%—70%,當SGA過大的時候會導致內存分頁,影響系統性能。
1.1.3 交換區設計
當物理內存在2G以下的情況下,交換分區swap為物理內存的3倍,當物理內存>2G的情況下,swap大小為物理內存的1—2倍。
1.1.4 其他環境變量 參考Oracle相關的安裝文檔和隨機文檔。
1.2 數據庫設計原則
1.2.1 數據庫SID
數據庫SID是唯一標志數據庫的符號,命名長度不能超過5個字符。對於單節點數據庫,以字符開頭的5個長度以內字串作為SID的命名。對於集群數據庫,當命名SID後,各節點SID自動命名為SIDnn,其中nn為節點號:1,2,…,64。例如rac1、rac2、rac24。
1.2.2 數據庫全局名
.domain
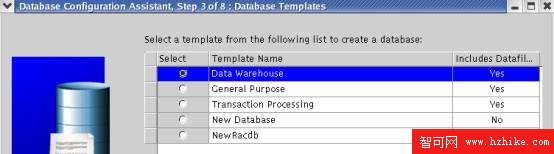
1.2.3 數據庫類型選擇
對於海量數據庫系統,采用data warehouse的類型。對於小型數據庫或OLTP類型的數據庫,采用Transaction Processing類型。
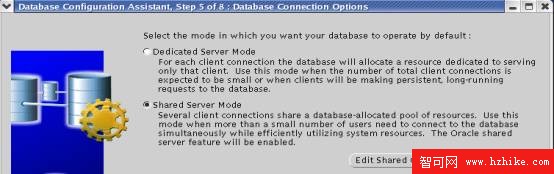
1.2.4 數據庫連接類型選擇
Oracle數據庫有專用服務器連接類型和多線程服務器MTS連接類型。對於批處理服務,需要專用服務器連接方式,而對於OLTP服務則MTS的連接方式比較合適。由於采用MTS後,可以通過配置網絡服務實現某些特定批處理服務采用專用服務器連接方式,所以數據庫設計時一般采用MTS類型。
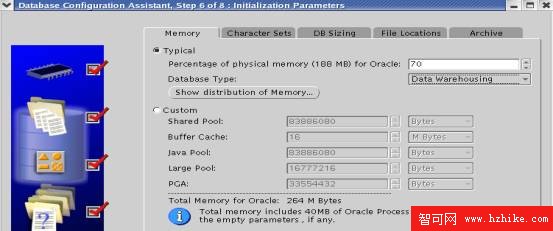
1.2.5 數據庫SGA配置
數據庫SGA可以采用手工配置或按物理內存比例配置,在數據庫初始設計階段采用按比例配置方式,在實際應用中按系統調優方式修改SGA。
1.2.6 數據庫字符集選擇
為了使數據庫能夠正確支持多國語言,必須配置合適的數據庫字符集,采用UTF8字符集。
注意:如果沒有大對象,在使用過程中進行語言轉換沒有什麼影響,具體過程如下(切記設定的字符集必須是Oracle支持,不然不能start)
SQL> shutdown immediate; SQL> startup mount; SQL> alter system enable restricted session; SQL> alter system set job_queue_processes=0; SQL> alter database open; SQL> alter database character set internal_use we8iso8859p1; SQL> shutdown immediate; SQL> startup
1.2.7 數據庫其他參數配置
1.2.7.1 DB_FILES
Db_files是數據庫能夠同時打開的文件數量,默認值是200個。當數據庫規劃時文件數量FILES接近或超過200個時候,按以下估計值配置:
DB_FILES = FILES * 1.5
1.2.7.2 Db_block_size
一個extent要是5個blocks的倍數為好,如:一個blocks是4096字節,那一個extent就是2M、4M或8M為好。Db_block_size是數據庫最小物理單元,一旦數據庫創建完成,該參數無法修改,db_block_size按以下規則調整:
數據倉庫類型: db_block_size盡可能大,采用8192 或 16384
OLTP類型: db_block_size 用比較小的取值范圍: 2048 或 4096
Blocks推薦是系統操作的塊倍數(裸設備塊大小是512字節,NTFS是 4K,使用8K的方式在大部分系統上通用)。
1.2.8 數據庫控制文件配置
1.2.8.1 控制文件鏡象
多個控制文件存放在不同的物理位置。
1.2.8.2 控制文件配置
控制文件中參數設置,最大的數據文件數量不能小於數據庫參數db_files。
1.2.9 數據庫日志文件配置
1.2.9.1 日志文件大小
日志文件的大小由數據庫事務處理量決定,在設計過程中,確保每20分鐘切換一個日志文件。所以對於批處理系統,日志文件大小為幾百M 到幾G的大小。對於OLTP系統,日志文件大小為幾百M以內。
1.2.9.2 日志文件組數量
對於批處理系統,日志文件組為5—10組;對於OLTP系統,日志文件組為 3—5組,每組日志大小保持一致;對於集群數據庫系統,每節點有各自獨立的日志組。
1.2.9.3 日志成員數量
為了確保日志能夠鏡象作用,每日志組的成員為2個。
1.2.10 數據庫回滾段配置
在Oracle9i數據庫中,設計Undo表空間取代以前版本的回滾段表空間。
Undo 表空間大小的設計規范由以下公式計算:
UnDOSpace = UR * UPS *db_block_size+ 冗余量
UR: 表示在undo中保持的最長時間數(秒),由數據庫參數UNDO_RETENTION值決定。
UPS:表示在undo中,每秒產生的數據庫塊數量。
例如:在數據庫中保留2小時的回退數據,假定每小時產生200個數據庫塊。則UnDOSpace = 2 * 3600 * 200 * 4K = 5.8G
1.2.11 數據庫臨時段表空間配置
數據庫臨時段表空間根據實際生產環境情況調整其大小,表空間屬性為自動擴展。
1.2.12 數據庫系統表空間配置
系統表空間大小1G左右,除了存放數據庫數據字典的數據外,其他數據不得存儲在系統表空間。
1.3 數據庫表空間設計原則
1.3.1 表空間大小定義原則
當表空間 大小小於操作系統對最大文件限制時,表空間由一個文件組成。如果表空間大小大於操作系統對最大文件限制時,該表空間由多個數據文件組成,表空間的總大小為估算為:
Tablespace + sum (數據段+索引段)*150%。
1.3.2 表空間擴展性設計原則
CREATE TABLESPACE TBS_USERINFO DATAFILE '/oradata/tbs_userinfo.dbf' SIZE 8M REUSE AUTOEXTEND ON NEXT 2M MAXSIZE UNLIMITED NOLOGGING EXTENT MANAGEMENT LOCAL AUTOALLOCATE SEGMENT SPACE MANAGEMENT AUTO;
1.4 裸設備的使用
一個scsi設備可以 14個分區,unix操作系統256個分區,性能比文件系統方式高15%左右,空間大於要小於(實際分區大小減兩個Oracle的數據塊),比如100M,大於為100000K,推薦在unix使用軟連接(ln)方式把裸設備形成文件,用加入表空間時加resue 選項,當然也可只接把設備加入表空間,移動裸設備使用dd命令
對於Windows平台,Oracle提供軟連接工具,實現裸設備的使用,計算一條記錄的長度
2 數據庫邏輯設計原則
2.1 命名規范
2.1.1 表屬性規范
2.1.1.1 表名
前綴為Tbl_ 。數據表名稱必須以有特征含義的單詞或縮寫組成,中間可以用“_”分割,例如:tbl_pstn_detail。表名稱不能用雙引號包含。
2.1.1.2 表分區名
前綴為p 。分區名必須有特定含義的單詞或字串。
例如 :tbl_pstn_detail 的分區p2004100101表示該分區存儲 2004100101時段的數據。
2.1.1.3 字段名
字段名稱必須用字母開頭,采用有特征含義的單詞或縮寫,不能用雙引號包含。
2.1.1.4 主鍵名
前綴為PK_。主鍵名稱應是 前綴+表名+構成的字段名。如果復合主鍵的構成字段較多,則只包含第一個字段。表名可以去掉前綴。
2.1.1.5 外鍵名
前綴為FK_。外鍵名稱應是 前綴+ 外鍵表名 + 主鍵表名 + 外鍵表構成的字段名。表名可以去掉前綴。
2.1.2 索引
4.1.2.1 普通索引
前綴為IDX_。索引名稱應是 前綴+表名+構成的字段名。如果復合索引的構成字段較多,則只包含第一個字段,並添加序號。表名可以去掉前綴。
2.1.2.2 主鍵索引
前綴為IDX_PK_。索引名稱應是 前綴+表名+構成的主鍵字段名,在創建表時候用using index指定主鍵索引屬性。
2.1.2.3 唯一所以
前綴為IDX_UK_。索引名稱應是 前綴+表名+構成的字段名。
2.1.2.4 外鍵索引
前綴為IDX_FK_。索引名稱應是 前綴+表名+構成的外鍵字段名。
2.1.2.5 函數索引
前綴為IDX_func_。索引名稱應是 前綴+表名+構成的特征表達字符。
2.1.2.6 蔟索引
前綴為IDX_clu_。索引名稱應是 前綴+表名+構成的簇字段。
2.1.3 視圖
前綴為V_。按業務操作命名視圖。
2.1.4 實體化視圖
前綴為MV_。按業務操作命名實體化視圖。
2.1.5 存儲過程
前綴為Proc_ 。按業務操作命名存儲過程
2.1.6 觸發器
前綴為Trig_ 。觸發器名應是 前綴 + 表名 + 觸發器名。
2.1.7 函數
前綴為Func_ 。按業務操作命名函數
2.1.8 數據包
前綴為Pkg_ 。按業務操作集合命名數據包。
2.1.9 序列
前綴為Seq_ 。按業務屬性命名。
2.1.10 表空間
2.1.10.1 公用表空間
前綴為Tbs_ 。 根據存儲的特性命名,例如: tbs_parameter 。
2.1.10.2 專用表空間
Tbs_<表名稱>_nn。該表空間專門存儲指定的某一個表,或某一表的若干個分區的數據
2.1.11 數據文件
<表空間名>nn.dbf 。nn =1,2,3,4,…等。
2.1.12 普通變量
前綴為Var_ 。 存放字符、數字、日期型變量。
2.1.13 游標變量
前綴為Cur_ 。存放游標記錄集。
2.1.14 記錄型變量
前綴為Rec_ 。 存放記錄型數據。
2.1.15 表類型變量
前綴為Tab_ 。 存放表類型數據。
2.1.16 數據庫鏈
前綴為dbl_ 。 表示分布式數據庫外部鏈接關系。
2.2 命名
2.2.1 語言
命名應該使用英文單詞,避免使用拼音,特別不應該使用拼音簡寫。命名不允許使用中文或者特殊字符。
英文單詞使用用對象本身意義相對或相近的單詞。選擇最簡單或最通用的單詞。不能使用毫不相干的單詞來命名
當一個單詞不能表達對象含義時,用詞組組合,如果組合太長時,采用用簡或縮寫,縮寫要基本能表達原單詞的意義。
當出現對象名重名時,是不同類型對象時,加類型前綴或後綴以示區別。
2.2.2 大小寫
名稱一律大寫,以方便不同數據庫移植,以及避免程序調用問題。
2.2.3 單詞分隔
命名的各單詞之間可以使用下劃線進行分隔。
2.2.4 保留字
命名不允許使用SQL保留字。
2.2.5 命名長度
表名、字段名、視圖名長度應限制在20個字符內(含前綴)。
2.2.6 字段名稱
同一個字段名在一個數據庫中只能代表一個意思。比如telephone在一個表中代表“電話號碼”的意思,在另外一個表中就不能代表“手機號碼”的意思。
不同的表用於相同內容的字段應該采用同樣的名稱,字段類型定義。
2.3 數據類型
2.3.1 字符型
固定長度的字串類型采用char,長度不固定的字串類型采用varchar。避免在長度不固定的情況下采用char類型。如果在數據遷移等出現以上情況,則必須使用trim()函數截去字串後的空格。
2.3.2 數字型
數字型字段盡量采用number類型。
2.3.3 日期和時間
2.3.3.1 系統時間
由數據庫產生的系統時間首選數據庫的日期型,如DATE類型。
2.3.3.2 外部時間
由數據導入或外部應用程序產生的日期時間類型采用varchar類型,數據格式采用:YYYYMMDDHH24MISS。
2.3.3.3 大字段
如無特別需要,避免使用大字段(blob,clob,long,text,image等)。
2.3.3.4 唯一鍵
對於數字型唯一鍵值,盡可能用系列sequence產生。
2.4 設計
2.4.1 范式
如無性能上的必須原因,應該使用關系數據庫理論,達到較高的范式,避免數據冗余,但是如果在數據量上與性能上無特別要求,考慮到實現的方便性可以有適當的數據冗余,但基本上要達到3NF.如非確實必要,避免一個字段中存儲多個標志的做法。如11101表示5個標志的一種取值。這往往是增加復雜度,降低性能的地方。
2.4.2.1 邏輯段設計原則
2.4.2.1.1 Tablespace
每個表在創建時候,必須指定所在的表空間,不要采用默認表空間以防止表建立在系統表空間上導致性能問題。對於事務比較繁忙的數據表,必須存放在該表的專用表空間中。
2.4.2.1.2 Pctused
默認pctused導致數據庫物理空間利用率非常低40%左右;對於update比較少或update不導致行增大的表,pctused可設置在60—85之間;對於update能夠導致行增大的表,update設置在40—70之間
2.4.2.1.3 Initrans
對於需要並行查詢或者在RAC數據庫中需要並行處理的表,initrans設置為2的倍數,否則,不設該值。
2.4.2.1.4 Storage
2.4.2.1.4.1 Initial
盡量減少表數據段的extents數量,initial的大小盡量接近數據段的大小64K,128K,… ,1M,2M,4M,8M,16M ,…,等按2的倍數進行圓整。例如表或分區數據段大小為28M,則initial取32M。
2.4.2.1.4.2 Next
表或分區擴展extents的大小,按上述方法進行圓整。當表或分區數據段無法按Initial接近值進行圓整的情況下,其大小可以按 Initial+Next進行圓整。此時,必須設置Minextents=2。 例如:表或分區數據段大小為150M,則Initial=128M;Next=32M,Minextents=2。
2.4.2.1.4.3 Minextents
該參數表示表創建時候Extents的初始數量,一般取1—2。
2.4.2.1.4.4 Pctincrease
表示每個擴展Extents的增長率,設置pctincrease=0能夠獲得較好的存儲性能。
2.4.2.2 特殊表設計原則
2.4.2.2.1 分區表
對於數據量比較大的表,根據表數據的屬性進行分區,以得到較好的性能。如果表按某些字段進行增長,則采用按字段值范圍進行范圍分區;如果表按某個字段的幾個關鍵值進行分布,則采用列表分區;對於靜態表,則采用hash分區或列表分區;在范圍分區中,如果數據按某關鍵字段均衡分布,則采用子分區的復合分區方法。
2.4.2.2.2 聚蔟表
如果某幾個靜態表關系比較密切,則可以采用聚蔟表的方法。
2.4.2.3 完整性設計原則
2.4.2.3.1 主鍵約束
關聯表的父表要求有主健,主健字段或組合字段必須滿足非空屬性和唯一性要求。對於數據量比較大的父表,要求指定索引段。
2.4.2.3.2 外鍵關聯
對於關聯兩個表的字段,一般應該分別建立主鍵、外鍵。實際是否建立外鍵,根據對數據完整性的要求決定。為了提高性能,對於數據量比較大的標要求對外健建立索引。對於有要求級聯刪除屬性的外鍵,必須指定on delete cascade 。
2.4.2.3.3 NULL值
對於字段能否null,應該在sql建表腳本中明確指明,不應使用缺省。由於NULL值在參加任何運算中,結果均為NULL。所以在應用程序中必須利用nvl()函數把可能為NULL值得字段或變量轉換為非NULL的默認值。例如:NVL(sale,0)。
2.4.2.3.4 Check條件
對於字段有檢查性約束,要求指定check規則。
2.4.2.3.5 觸發器
觸發器是一種特殊的存儲過程,通過數據表的DML操作而觸發執行,起作用是為確保數據的完整性和一致性不被破壞而創建,實現數據的完整約束。
觸發器的before或after事務屬性的選擇時候,對表操作的事務屬性必須與應用程序事務屬性保持一致,以避免死鎖發生。在大型導入表中,盡量避免使用觸發器。
2.4.2.4 注釋
表、字段等應該有中文名稱注釋,以及需要說明的內容。
2.4.3 索引設計
對於查詢中需要作為查詢條件的字段,可以考慮建立索引。最終根據性能的需要決定是否建立索引。 對於復合索引,索引字段順序比較關鍵,把查詢頻率比較高的字段排在索引組合的最前面。 在分區表中,盡量采用local分區索引以方便分區維護。
除非時分區local索引,否則在創建索引段時候必須指定指定索引段的tablespace、storage屬性,具體參考4.4.2.1內容。
2.4.4 視圖設計
視圖是虛擬的數據庫表,在使用時要遵循以下原則:
從一個或多個庫表中查詢部分數據項;
為簡化查詢,將復雜的檢索或字查詢通過視圖實現;
提高數據的安全性,只將需要查看的數據信息顯示給權限有限的人員;
視圖中如果嵌套使用視圖,級數不得超過3級;
由於視圖中只能固定條件或沒有條件,所以對於數據量較大或隨時間的推移逐漸增多的庫表,不宜使用視圖;可以采用實體化視圖代替。
除特殊需要,避免類似Select * from [TableName] 而沒有檢索條件的視圖;
視圖中盡量避免出現數據排序的SQL語句。
2.4.5 包設計
存儲過程、函數、外部游標必須在指定的數據包對象PACKAGE中實現。存儲過程、函數的建立如同其它語言形式的編程過程,適合采用模塊化設計方法;當具體算法改變時,只需要修改需要存儲過程即可,不需要修改其它語言的源程序。當和數據庫頻繁交換數據是通過存儲過程可以提高運行速度,由於只有被授權的用戶才能執行存儲過程,所以存儲過程有利於提高系統的安全性。
存儲過程、函數必須檢索數據庫表記錄或數據庫其他對象,甚至修改(執行Insert、Delete、Update、Drop、Create等操作)數據庫信息。如果某項功能不需要和數據庫打交道,則不得通過數據庫存儲過程或函數的方式實現。在函數中避免采用DML或DDL語句。
在數據包采用存儲過程、函數重載的方法,簡化數據包設計,提高代碼效率。存儲過程、函數必須有相應的出錯處理功能。
2.4.6 安全性設計
4.4.6.1 管理默認用戶
在生產環境中,必須嚴格管理sys和system用戶,必須修改其默認密碼,禁止用該用戶建立數據庫應用對象。刪除或鎖定數據庫測試用戶scott 。
2.4.6.2 數據庫級用戶權限設計
必須按照應用需求,設計不同的用戶訪問權限。包括應用系統管理用戶,普通用戶等,按照業務需求建立不同的應用角色。
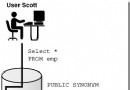
用戶訪問另外的用戶對象時,應該通過創建同義詞對象synonym進行訪問。
2.4.6.3 角色與權限
確定每個角色對數據庫表的操作權限,如創建、檢索、更新、刪除等。每個角色擁有剛好能夠完成任務的權限,不多也不少。在應用時再為用戶分配角色,則每個用戶的權限等於他所兼角色的權限之和。
2.4.6.4 應用級用戶設計
應用級的用戶帳號密碼不能與數據庫相同,防止用戶直接操作數據庫。用戶只能用帳號登陸到應用軟件,通過應用軟件訪問數據庫,而沒有其它途徑操作數據庫。
2.4.6.5 用戶密碼管理
用戶帳號的密碼必須進行加密處理,確保在任何地方的查詢都不會出現密碼的明文。
2.5 SQL編寫
2.5.1 字符類型數據
SQL中的字符類型數據應該統一使用單引號。特別對純數字的字串,必須用單引號,否則會導致內部轉換而引起性能問題或索引失效問題。利用trim(),lower()等函數格式化匹配條件。
2.5.2 復雜sql
對於非常復雜的sql(特別是有多層嵌套,帶子句或相關查詢的),應該先考慮是否設計不當引起的。對於一些復雜SQL可以考慮使用程序實現。
USER_TAB_COMMENTS 數據字典
Comment on 可加注解
2.5.3 高效性
2.5.3.1 避免In子句
使用In 或 not In子句時,特別是當子句中有多個值時,且查詢數據表數據較多時,速度會明顯下降。可以采用連接查詢或外連接查詢來提高性能。
Char 比 varchar 查詢時高詢
在進行查詢及建立索引時,char比varchar的效率要高,當然varchar在存儲上比char要好
2.5.3.2 避免嵌套的Select子句
這個實際上是In子句的特例。
2.5.3.3 避免使用Select * 語句
如果不是必要取出所有數據,不要用*來代替,應給出字段列表,注:不含select count(*)。
2.5.3.4 避免不必要的排序
不必要的數據排序大大的降低系統性能。
2.5.4 健壯性
2.5.4.1 Insert語句
使用Insert語句一定要給出要插入值的字段列表,這樣即使更改了表結構加了字段也不會影響現有系統的運行。
2.5.4.2 Count(*)、Count(*)、count(distinct id)的區別
Select count(*) from testtab
得到表testtab的記錄數
select count(id) from testtab
得到表testtab id字段非空記錄數
select count(distinct id) from testtab
得到表testtab id字段值非相同記錄數
2.5.4.3 Not null 為字段類型性質的約束
本約束功能在後期無語法使期失效,可使用修改字段類型方式
alter table modify 字段名 類型 not null
alter table modify 字段名 類型
外鍵列如沒有明確說明not null,可插入null記錄(而null是在外部表的記錄中沒有的),如無可插null記錄的想法,要對外鍵字段加not null約束。
2.5.4.5 序列 sequence 跳號的問題
sequence 因回滾,系統崩潰(使用cache 內的值將認為已用),多表引用都將使其跳號,所以不能用於為連續序號 utl_row.cast_to_row
2.5.4.6 unicn\ intersect\ minus 使用ordey by的注意事項
以上語句進行連表操作,而表同表的字段順序的類型相同但字段標題名可不同,使用ordey by時後面如果是字段名,要求所有的表的字段標題名相同,否則用字段的順序號
select id,name,year from user1 union select no,name,to_number(null) year from user2 order by 1,name,year
2.5.5 安全性
2.5.5.1 Where 條件
無論在使用Select,還是使用破壞力極大的Update和Delete語句時,一定要檢查Where條件判斷的完整性,不要在運行時出現數據的重大丟失。如果不確定,最好先用Select語句帶上相同條件來果一下結果集,來檢驗條件是否正確。
2.5.6 完整性
有依賴關系的表,例如主外鍵關系表,在刪除父表時必須級聯刪除其子表相應數據,或則按照某種業務規則轉移該數據。9I中表中字段縮小及變類型,字段為空或表空,varchar和char長度不變可任意改,字段名和表名可字段可用 ALTER TABLE table SET UNUSED (column) 設定為不可用,注意無命令再設為可用
3 備份恢復設計原則
3.1 數據庫exp/imp備份恢復
Oracle數據庫的Exp、Imp提供了數據快速的備份和恢復手段,提供了數據庫級、用戶級和表級的數據備份恢復方式。這種方法一般作為數據庫輔助備份手段。
3.1.1 數據庫級備份原則
在數據庫的數據量比較小,或數據庫初始建立的情況下采用。不適合7*24的在線生產環境數據庫備份。
3.1.2 用戶級備份原則
在用戶對象表數據容量比較小、或則用戶對象初始建立的情況下使用。
3.1.3 表級備份原則
主要在以下場合采用的備份方式:
參數表備份
靜態表備份
分區表的分區備份。
3.2 數據庫冷備份原則
數據庫冷備份必須符合以下原則:
數據庫容量比較小。
數據庫允許關閉的情況。
3.3 Rman備份恢復原則
這種方式適用於7*24環境下的聯機熱備份情形。
3.3.1 Catalog數據庫
單獨建立備份恢復用的數據庫實例,盡可能與生產環境的數據庫分開,確保catalog與生產數據庫的網絡連接良好。在9I系統使用良好的備份策略以可,支持完全使用控制文件保存catalog信息,備份策略如下:
backup spfile format '/data/backup/%d_SPFILE_%T_%s_%p.bak'; sql "alter system archive log current"; backup archivelog all format '/data/backup/%d_ARC_%T_%s_%p.bak' delete all input; backup current controlfile format '/data/backup/%d_CTL_%T_%s_%p.bak'; 在spfile、控制文件、數據庫全丟的情況下可通過下面的方式恢復 RMAN> connect target connected to target database (not started) RMAN> startup RMAN> restore spfile from '/data/backup/COMMDB_SPFILE_20030411_9_1.bak'; SQL> startup ORA-00205: error in identifying controlfile, check alert log for more info RMAN> restore controlfile from 'd:\DB92_CTL_20031113_9_1.BAK'; Mout database: RMAN> recover database; RMAN> alter database open resetlogs;
注意:對數據庫設定控制文件保存備份信息為365天,具體語句如下。
alter system set control_file_record_keep_time=365 SCOPE=BOTH;
3.3.2 Archive Log
設置Archive Log 的位置,確保存儲介質有足夠的空間來保留指定時間內archive log的總量。建設定期對RMAN進行全備份,刪除冗余歸檔日志文件。
3.3.3 全備份策略
對於小容量數據庫,可以采用全備份策略。對於大容量數據庫,必須制定全備份策略方案,備份時對archive log進行轉儲,同時冷備份catalog 數據庫。
3.3.4 增量備份策略
對於大容量數據庫,必須制定增量備份、累積備份和全備份的周期,備份時對archive log進行轉儲,同時冷備份catalog 數據庫。
3.3.5 恢復原則
采用Rman腳本進行數據庫恢復。數據庫恢復有以下幾種:
3.3.5.1 局部恢復
主要用於恢復表空間、數據文件,一般不影響數據庫其他操作。
3.3.5.2 完全恢復
數據庫恢復到故障點,由catalog當前數據庫決定。
3.3.5.3 不完全恢復
恢復到數據庫的某一時間點或備份點。
恢復catalog數據庫。
恢復數據庫control file 。
恢復到數據庫某一時間點。
重設日志序列。
3.4 備用數據庫原則
數據庫系統在以下情況下可以考慮采用備用數據庫data guard原則:
數據庫容量適中。
數據庫嚴格要求7*24不間斷,或間斷時間要求控制在最小范圍內。
數據庫要求有異地備份冗余。
3.5 一些小經驗
使用oemc的oms時,首選項要求是節點和數據庫分別加入系統用戶(如:administrator)和數據庫DBA用戶(system)。節點的系統用戶必須有批處理作業登錄的權限
agent 不能啟動,lisnter修改後都要手動刪除Oracle\ora9\network\agent 中的*.q文件
Oracle\admin\my9i\bdump 中是用戶的出錯日志
改變表的空間的方式alter table hr.ssss move TABLESPACE example(要重建索引); 或用imp導入時,設定導入用戶只有某一表空間的使用權,無RESOURCE角色和UNLIMITED TABLESPACE權限
aleter system set log_checkpoint_to_alter=true,後可報警文件發現checkpoint的起動和結束時間。
3.6 系統調優知識
3.6.1.1 生成狀態報表(statspack的使用)
使用(存放位置@?\rdbms\admin\)的文件生成報表用戶
@?\rdbms\admin\Spcreate.sql建表
將timed_statistics設定true
使用生成的perfstat用戶登錄,執行以下語句手動收集信息
Exex statspack.snap
Exec statspack.snap(I_SNAP_LEVEL=>0,I_MODEFY_PRAMETER=>TRUE) 0級,最少10最大
使用下面的語句生成狀態報表
@?\rdbms\admin\Spreport.sql
其他相關文件
delete stats$snapshot ;清原來記錄數據
@?\rdbms\admin\Saputo.sql
select job from user_jobs 取用戶作業號
exec dbms_remove(作業號)
timed_statistics=true要求
@?\rdbms\admin\spdrop.sql ;
3.6.1.2 sql追蹤
設定全部用戶跟蹤
alter system set sql_trace=true;
用戶級別跟蹤
alter session set sql_trace=true;
用戶的跟蹤文件生成在 admin\{pid}\udump\{pid} _ora_{ SPID}.trc 中,spid從下面語句得到
SELECT b.name bkpr, s.username, p.spid,s.sid,s.serial# FROM v$bgprocess b, v$session s, v$process p WHERE p.addr = b.paddr(+) AND p.addr = s.paddr and s.username=user;
DBA對特定用戶跟蹤
exec dbms_system_set_Sql_trace_in_session(sid,serial#,true)
信息從下面得到
SELECT b.name bkpr, s.username, p.spid,s.sid,s.serial#,osuser,s.program
FROM v$bgprocess b, v$session s, v$process p
WHERE p.addr = b.paddr(+)
AND p.addr = s.paddr;
/*p.spid用於sql_trace時日志編號,dbms_system.set_sql_trace_in_session(sid,erial#,true)*/
用戶的跟蹤文件生成在 admin\{pid}\udump 中
系統的跟蹤文件生成在admin\{pid}\bdump\alert_{pid}.log
tkprof.exe將log文件生成格式化文本
在av Rd(ms) 20以上說明表空間使用過用頻繁,考慮將表分開其他表空間上
系統變量fast_start_mttr_target的值要大到不產生log等待,當然也可通過加log組使其不等待
reao log大小應為每30分鐘切換一次
建議表空間的利用率不超80%
buffer hit 要達80%以上為好
3.6.1.3 內存調整
一般的內存分配原則
SGA 50%(其中80% DATA BUFFER,15% SHARE POOL,5其他)
PGA30%
OS 20%
例如:2G的Windows的平台,OS 300M,SAG 1.2G,PGA 500M
內存分配的基本單位
SGA《=128M 4M
SGA》128M 64位系統16M,32M系統8M
動態分配時總值不可大於sga_max_size
通過V$SGA_DYNAMIC_FREE_MEMORY取空閒內存空間
在縮小時如果內存空間實際在應用中,CPU利用率將達100%,最後將語句出錯。
V$SGASTAT 可看實際的使用情況
Redo log buffer一般在5M內,可通過v$sessuon_wait看是否等,v$sysstat
可也通過報警文件看是否等切換,方法可加組。可通過nologging(數據庫也要設定支持nologging)方法減少日志文件產生量。
Java_pool 沒有設定時,使用shared_pool_size
3.6.1.3.1 shared_pool
本緩沖區用於sql語句,pl sql等的對象保存
Cursor_sharing{Exact|Similar|force} 游標共享設定
Force方式適用OLTP數據庫,Exact方式適合數據倉庫,similar為智能方式
hard parses 硬SQL語句分析,每秒要底於100次,小要加大shared_pool
soft parse 軟SQL語句分析,OLTP要達90%以上,小要加大shared_pool
不建議用無命名PL SQL段
如果有大PL SQL(存儲過程)對象可強制保存於內存,也可加大SHARED_POOL_RESERVED_SIZE,大小不可過SHARED_POOL_SIZE的50%,不然實例不能起動
3.6.1.3.2 db_cache
本緩沖區用於數據庫數據對象保存
db_cache_advice 為on,可以提出通過企業管理器看到系統建議
通過select * from v$system_event 進行系統查看。
發現存在free buffer waits,說明不能將data buffer及時寫入data file;
可通過增加加CPU後,加db_writer_processes=CPU數改善。
也可設disk_asynch_io為true,使用異步IO(前提同要操作系統支持)db_writer_processes=1時(只有一個CPU的情況下),也可通加大dbwr_io_slaves來改善。db_writer_processes>1,不可用本功能
調整效果排序:異步IO>CPU>dbwr_io_slaves
Buffer Busy Waits大說明出現IO沖突
Buffer Busy Waits 大 和 dbbock大說明全表掃描多,說明數據不能讀入,可加大
db_cache_size來改善.
Undo block大要加大回滾段(手動管理方式,9I默認是自動管理)
undo header 大要加大回滾段(手動管理方式,9I默認是自動管理)
db_cache命中率99%,不是唯一因素,關系是不要出現等待。建議達90%以上。
內存使用建議:
系統可以設三個緩沖區,建表時可設定用那個緩沖區(默認在db_cache_size)
db_cache_size (默認區)
db_keep_cache_size (常訪問,小於db_keep_cache_size的10%的表可放於本區)
db_recycle_cache_size (一個事物完成後常時間不再使用,或兩倍大小於緩沖區)
3.6.2 排序的優化
9I為專用服務器時系統變量workarea_size_policy 設定為auto, statistics_level設定為 TYPICAL 可獲取v$pga_target_advice中的優化建議。參數pga_aggregate_target值為所有連接用戶可用排序內存。
9I為共享服務器時workarea_size_policy設定為menaul, sort_area_size值為每用戶排序內存。
如果內存不足將使用TEMP表空間進行排序,排序使用比率disk/meme應小於5%
盡量少用排序,如果使用排序功能,盡量在字段上加索引進行優化。
SQL分析模式:RBO(基於規則)方案小表(驅動表)放在最後,優先使用索引,對SQL語句要求嚴格(8I以前的模式);CBO (基於開銷)根據統計值進行選擇開銷最少,性能最優的最佳方式進行,但本方式DBA(使用analyze table語句)要定期進行分析統計.系統設定通過optimizer_mode 系統參數
說明: 指定優化程序的行為。如果設置為 RULE, 就會使用基於規則的優化程序, 除非查詢含有提示。如果設置為 CHOOSE, 就會使用基於成本的優化程序, 除非語句中的表不包含統計信息。ALL_ROWS 或 FIRST_ROWS
始終使用基於成本的優化程序。
值范圍: RULE | CHOOSE | FIRST_ROWS | ALL_ROWS
默認值: CHOOSE
{rule(RBO)|choose(自動選擇)|fist_rows| fist_rows_n|all_row}
3.6.3 統計信息
進行某表的統計分析
EXECUTE dbms_stats.gather_table_stats ('HR','EMPLOYEES');
查看結果
SELECT num_rows, blocks, empty_blocks as empty, avg_space, chain_cnt, avg_row_len FROM dba_tables WHERE owner = 'HR' AND table_name = 'EMPLOYEES';
4 設計工具
統一使用Sybase power designer設計工具,在該工具上完成物理模型的設計。所有的數據庫對象盡可能在物理模型上進行設計,而且每個物理模型都要有相應的文字描述。
所有的數據庫對象變更以數據庫物理模型為基准。為了避免字符敏感問題,產生的腳本以大寫字母為標准。