查詢是在表上進行的最頻繁的訪問。
在查詢數據時,很少有用戶願意查詢表中的所有數據,除非要對整個表進行處理。
一般情況下用戶總是查詢表中的一部分數據。
在SELECT語句中,通常需要通過WHERE子句指定查詢條件,以獲得滿足該條件的所有數據。
如果能夠在很小的范圍內查詢需要的數據,而不是在全表范圍內查詢,那麼將減少很多不必要的磁盤1/0 ,查詢的速度無疑會大大加快。
提供這種快速查詢的方法就是索引。
索引的基本概念
索引是一種建立在表上的數據庫對象,它主要用於加快對表的查詢操作。
合理使用索引可以大大減少磁盤訪問的次數,從而大大提高數據庫的性能。
使用索引的主要目的是加快查詢速度,另外,索引也可以作為唯一性約束。
如果在表的一個列上建立了唯一性索引,那麼系統將自動在這個列上建立唯一性約束,這樣可以保證插入這個列的數據是唯一的。
索引究竟是怎樣加快查詢速度的呢?
原來,索引是建立在表中的某個列或幾個列上的,這樣的列稱為索引列。
在創建索引時,數據庫服務器將對索引列的數據進行排序,並將排序的結果存儲在索引所占用的存儲空間中。
在查詢數據時,數據庫服務器首先在索引中查詢,然後再到表中查詢。
因為索引中的數據事先進行了排序,所以只需要很少的查找次數就可以找到需要的數據。
在索引中,不僅存儲了索引列上的數據,而且還存儲了一個ROWID 的值。
ROWID是表中的一個偽列,是數據庫服務器自動添加的,表中的每一行數據都有一個ROWID值,它代表這一行的標識,即一行數據在存儲空間的物理位置。
在訪問表中的數據時,都要根據這個偽列的值找到數據的實際存儲位置,然後再進行訪問。
由於索引列上的數據已經進行了排序,在索引中很快就能找到這行數據,然後根據ROWID就能直接到表中找到這行數據了。
需要注意的是,表是獨立於索引的,無論對在表上建立了多少索引,無論索引對表中的數據進行什麼樣的排序,表中的數據都不會有任何變化。
在查詢一行數據時,首先在索引中查詢該行的行標識,然後根據這個行標識找到表中的數據。
因為索引中的數據是經過排序的,所以采用了折半查找法查找數據,以達到快速查找的目的。
利用折半查找法在索引中查找數據的過程類似於遍歷一棵二叉樹,首先與根節點比較,如果與查找的數據相同,則一次訪問就完成查詢。
如果要查找的數據小於根節點,則在根節點的左子樹中查找,否則在右子樹中查找,這樣查找的范圍將縮小一半。
按照這種方法,每次將查找范圍縮小一半,然後在剩下的節點中繼續查找,直到找到所需的數據。
按照索引列的值是否允許重復,索引可以分為唯一性索引和非唯一性索引,其中唯一性索引可以保證索引列的值是唯一的。
按照索引列中列的數目,索引可以分為單列索引和復合索引。
按照索引列的數據的組織方式,索引可以分為B+樹索引、位圖索引、反向索引和基於函數的索引,這裡僅介紹B+樹索引的用法。
合理地使用索引固然可以大大提高數據庫的查詢性能,但是不合理的索引反而會降低數據庫的性能,尤其是在進行DML操作時。
在創建索引時,表中的數據將被排序,如果對表進行了DML操作,表中的數據發生了變化,這時索引中的數據也將被重新排序,如果在表上建立了多個索引,那麼每個索引中的數據都要被重新進行排序。
這種排序的開銷是很大的,尤其是表非常大時。
索引是關系型數據庫系統用來提高性能的有效方法之一,索引的使用可以減少磁盤訪問的次數,從而大大提高了系統的性能。
但是在設計索引時必須全面考慮在表上所進行的操作,如果在表上進行的主要操作是查詢操作,那麼可以考慮在表上建立索引,如果在表上要進行頻繁
的DML操作,那麼索引反而會引起更多的系統開銷。
一般來說,創建索引要遵循以下原則:
·如果每次查詢僅選擇表中的少量行,應該建立索引。
·如果在表上需要進行頻繁的DML操作,不要建立索引。
·盡量不要在有很多重復值的列上建立索引。
·不要在太小的表上建立索引。
在一個小表中查詢數據時,速度可能已經足夠快,如果建立索引,對查詢速度不僅沒有多大幫助,反而需要一定的系統開銷。
索引的創建、修改和刪除
索引可以自動創建,也可以手工創建。如果在表的一個列或幾個列上建立了主鍵約束或者
唯一性約束,那麼數據庫服務器將自動在這些列上建立唯一性索引,這時索引的名字與約束的
名字相同。
手工創建索引需要執行SQL命令,創建索引的命令是CREATE INDEX 。一個用戶可以在自
己的模式中創建索引,只要這個用戶具有CREATE INDEX這個系統權限。如果希望在其他用戶
的模式中創建索引,那麼需要具有CREATE ANY INDEX這個系統權限。
CREATE INDEX 命令的語法格式為:
CREATE INDEX 索引名 ON 表名(列1,列2 ...);
在這個索引中,索引列只有一個,這樣的索引稱為單列索引。
如果要建立復合索引,則要指定多個列。
例如:
CREATE INDEX ind_de_dn ON test(deptno, dname);
復合索引主要用於多個條件的查詢語句中。
在默認情況下,創建的索引是非唯一的,也就是說,在表中的索引列上允許存在重復值。
如果要創建唯一性索引,那麼需要使用關鍵字UNIQUE 。
例如:
CREATE UNIQUE INDEX ind_de ON test(deptno);
一般情況下,在指定索引中的列時,要遵循以下原則:
在WHERE子句中經常使用的列上創建索引。
盡量不要在具有大量重復值的列上創建索引。
具有唯一值的列是建立索引的最佳選擇,但是究竟是否在這個列上建立索引,還要看是否對這個列經常進行查詢。
如果WHERE子句中的條件涉及多個列,可以考慮在這些列上創建一個復合索引。
正如前面所說,合理設計的索引將提高系統的性能,而不合理的索引反而會降低系統性能。
所以,在數據庫的運行過程中,要經常利用SQL Trace檢查索引是否被使用,檢查索引是否像期望的那樣提高了數據庫的性能。
如果一個索引並設有被頻繁地使用,或者一個索引對數據庫性能的提高只有微小的幫助甚至設有幫助,這時可以考慮刪除這個索引。
索引信息的查詢
與索引有關的數據字典有兩個: user_indexes和user_ind_columns 。
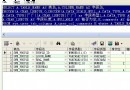
例如,要查詢索引的類型、所基於的表、是否唯一性索引,以反狀態、等信息,可以執行以下查詢語句:
SELECT index_type, table_name, status FROM user_indexes WHERE index_name='IND_DE';
下面的查詢語句用來獲得索引所基於的表和表上的列:
SELECT table_name, column_name FROM user_ind_columns WHERE index_name='IND_DE';
數據字典視圖user_ind_columns各列的定義和意義如下:
名稱 意義
INDEX_NAME Index name
TABLE_NAME Table or cluster name
COLUMN_NAME Column name or attribute of object column
COLUMN_POSITION Position of column or attribute within index
COLUMN_LENGTH Maximum length of the column or attribute, in bytes
CHAR_LENGTH Maximum length of the column or attribute, in characters
DESCEND DESC if this column is sorted descending on disk, otherwise ASC
注:cluster 簇表;
attribute 屬性
數據字典視圖user_indexes常用各列的定義和意義如下:
名稱 意義
INDEX_NAME 索引名稱
INDEX_TYPE 索引類型
TABLE_OWNER 對象屬主
TABLE_NAME 對象名稱
TABLE_TYPE 對象類型
STATUS 狀態
注:數據字典視圖user_indexes上列有很多。