《基於Oracle的sql優化》裡關於哈希連接的原理介紹如下:
哈希連接(HASH JOIN)是一種兩個表在做表連接時主要依靠哈希運算來得到連接結果集的表連接方法。
在Oracle 7.3之前,Oracle數據庫中的常用表連接方法就只有排序合並連接和嵌套循環連接這兩種,但這兩種表連接方法都有其明顯缺陷。對於排序合並連接,如果兩個表在施加了目標SQL中指定的謂詞條件(如果有的話)後得到的結果集很大且需要排序的話,則這種情況下的排序合並連接的執行效率一定是很差的;而對於嵌套循環連接,如果驅動表所對應的驅動結果集的記錄數很大,即便在被驅動表的連接列上存在索引,此時使用嵌套循環連接的執行效率也同樣會很差。
為了解決排序合並連接和嵌套循環連接在上述情形下執行效率不高的問題,同時也為了給優化器提供一種新的選擇,Oracle在Oracle 7.3中引入了哈希連接。從理論上來說,哈希連接的執行效率會比排序合並連接和嵌套循環連接的執行效率要高,當然,實際情況並不總是這樣。
在Oracle 10g及其以後的Oracle數據庫版本中,優化器(實際上是CBO,因為哈希連接僅適用於CBO)在解析目標SQL時是否考慮哈希連接是受限於隱含參數_HASH_JOIN_ENABLED,而在Oracle10g以前的Oracle數據庫版本中,CBO在解析目標SQL時是否考慮哈希連接是受限於參數HASH_JOIN_ENABLED。
_HASH_JOIN_ENABLED的默認值是TRUE,表示允許CBO在解析目標SQL時考慮哈希連接。當然,即使你將該參數的值改成了FALSE,我們使用USE_HASH Hint依然可以讓CBO在解析目標SQL時考慮哈希連接,這說明USE_HASH Hint的優先級高於參數_HASH_JOIN_ENABLED。
如果兩個表(這裡將它們分別命名為表T1和表T2)在做表連接時使用的是哈希連接,則Oracle在做哈希連接時會依次順序執行如下步驟:
1、 首先Oracle會根據參數HASH_AREA_SIZE、DB_BLOCK_SIZE和_HASH_MULTIBLOCK_IO_COUNT的值來決定Hash Partition的數量(Hash Partition是一個邏輯上的概念,所有Hash Partition的集合就被稱之為Hash Table,即一個Hash Table是由多個Hash Partition所組成,而一個Hash Partition又是由多個Hash Bucket所組成);
2、 表T1和T2在施加了目標SQL中指定的謂詞條件(如果有的話)後得到的結果集中數據量較小的那個結果集會被Oracle選為哈希連接的驅動結果集,這裡我們假設T1所對應的結果集的數據量相對較小,我們記為S;T2所對應的結果集的數據量相對較大,我們記為B;顯然這裡S是驅動結果集,B是被驅動結果集;
3、 接著Oracle會遍歷S,讀取S中的每一條記錄,並對S中的每一條記錄按照該記錄在表T1中的連接列做哈希運算,這個哈希運算會使用兩個內置哈希函數,這兩個哈希函數會同時對該連接列計算哈希值,我們把這兩個內置哈希函數分別記為hash_func_1和hash_func_2,它們所計算出來的哈希值分別記為hash_value_1和hash_value_2;
4、 然後Oracle會按照hash_value_1的值把相應的S中的對應記錄存儲在不同Hash Partition的不同Hash Bucket裡,同時和該記錄存儲在一起的還有該記錄用hash_func_2計算出來的hash_value_2的值。注意,存儲在Hash Bucket裡的記錄並不是目標表的完整行記錄,而是只需要存儲位於目標SQL中的跟目標表相關的查詢列和連接列就足夠了;我們把S所對應的每一個Hash Partition記為Si;
5、 在構建Si的同時,Oracle會構建一個位圖(BITMAP),這個位圖用來標記Si所包含的每一個Hash Bucket是否有記錄(即記錄數是否大於0);
6、 如果S的數據量很大,那麼在構建S所對應的Hash Table時,就可能會出現PGA的工作區(WORK AREA)被填滿的情況,這時候Oracle會把工作區中現有的Hash Partition中包含記錄數最多的Hash Partition寫到磁盤上(TEMP表空間);接著Oracle會繼續構建S所對應的Hash Table,在繼續構建的過程中,如果工作區又滿了,則Oracle會繼續重復上述挑選包含記錄數最多的Hash Partition並寫回到磁盤上的動作;如果要構建的記錄所對應的Hash Partition已經事先被Oracle寫回到了磁盤上,則此時Oracle就會去磁盤上更新該Hash Partition,即會把該條記錄和hash_value_2直接加到這個已經位於磁盤上的Hash Partition的相應Hash Bucket中;注意,極端情況下可能會出現只有某個Hash Partition的部分記錄還在內存中,該Hash Partition的剩余部分和余下的所有Hash Partition都已經被寫回到磁盤上;
7、 上述構建S所對應的Hash Table的過程會一直持續下去,直到遍歷完S中的所有記錄為止;
8、 接著,Oracle會對所有的Si按照它們所包含的記錄數來排序,然後Oracle會把這些已經排好序的Hash Partition按順序依次、並且盡可能的全部放到內存中(PGA的工作區),當然,如果實在放不下的話,放不下的那部分Hash Partition還是會位於磁盤上。我認為這個按照Si的記錄數來排序的動作不是必須要做的,因為這個排序動作的根本目的就是為了盡可能多的把那些記錄數較小的Hash Partition保留在內存中,而將那些已經被寫回到磁盤上、記錄數較大且現有內存已經放不下的Hash Partition保留在磁盤上,顯然,如果所有的Si本來就都在內存中,也沒發生過將Si寫回到磁盤的操作,那這裡根本就不需要排序了。
9、 至此Oracle已經處理完S,現在可以來開始處理B了;
10、 Oracle會遍歷B,讀取B中的每一條記錄,並對B中的每一條記錄按照該記錄在表T2中的連接列做哈希運算,這個哈希運算和步驟3中的哈希運算是一模一樣的,即這個哈希運算還是會用步驟3中的hash_func_1和hash_func_2,並且也會計算出兩個哈希值hash_value_1和hash_value_2;接著Oracle會按照該記錄所對應的哈希值hash_value_1去Si裡找匹配的Hash Bucket;如果能找到匹配的Hash Bucket,則Oracle還會遍歷該Hash Bucket中的每一條記錄,並會校驗存儲於該Hash Bucket中的每一條記錄的連接列,看是否是真的匹配(即這裡要校驗S和B中的匹配記錄所對應的連接列是否真的相等,因為對於Hash運算而言,不同的值經過哈希運算後的結果可能是一樣的),如果是真的匹配,則上述hash_value_1所對應B中的記錄的位於目標SQL中的查詢列和該Hash Bucket中的匹配記錄便會組合起來,一起作為滿足目標SQL連接條件的記錄返回;如果找不到匹配的Hash Bucket,則Oracle就會去訪問步驟5中構建的位圖,如果位圖顯示該Hash Bucket在Si中對應的記錄數大於0,則說明該Hash Bucket雖然不在內存中,但它已經被寫回到了磁盤上,則此時Oracle就會按照上述hash_value_1的值把相應B中的對應記錄也以Hash Partition的方式寫回到磁盤上,同時和該記錄存儲在一起的還有該記錄用hash_func_2計算出來的hash_value_2的值;如果位圖顯示該Hash Bucket在Si中對應的記錄數等於0,則Oracle就不用把上述hash_value_1所對應B中的記錄寫回到磁盤上了,因為這條記錄必然不滿足目標SQL的連接條件;這個根據位圖來決定是否將上述hash_value_1所對應B中的記錄寫回到磁盤的動作就是所謂的"位圖過濾";我們把B所對應的每一個Hash Partition記為Bj;
11、 上述去Si中查找匹配Hash Bucket和構建Bj的過程會一直持續下去,直到遍歷完B中的所有記錄為止;
12、 至此Oracle已經處理完所有位於內存中的Si和對應的Bj,現在只剩下位於磁盤上的Si和Bj還未處理;
13、 因為在構建Si和Bj時用的是同樣的哈希函數hash_func_1和hash_func_2,所以Oracle在處理位於磁盤上的Si和Bj的時候可以放心的配對處理,即只有對應Hash Partition Number值相同的Si和Bj才可能會產生滿足連接條件的記錄;這裡我們用Sn和Bn來表示位於磁盤上且對應Hash Partition Number值相同的Si和Bj;
14、 對於每一對兒Sn和Bn,它們之中記錄數較少的會被當作驅動結果集,然後Oracle會用這個驅動結果集的Hash Bucket裡記錄的hash_value_2來構建新的Hash Table,另外一個記錄數較大的會被當作被驅動結果集,然後Oracle會用這個被驅動結果集的Hash Bucket裡記錄的hash_value_2去上述構建的新Hash Table中找匹配記錄;注意,對每一對兒Sn和Bn而言,Oracle始終會選擇它們中記錄數較少的來作為驅動結果集,所以每一對兒Sn和Bn的驅動結果集都可能會發生變化,這就是所謂的"動態角色互換";
15、 步驟14中如果存在匹配記錄,則該匹配記錄也會作為滿足目標SQL連接條件的記錄返回;
16、 上述處理Sn和Bn的過程會一直持續下去,直到遍歷完所有的Sn和Bn為止。
對於哈希連接的優缺點及適用場景,我們有如下總結:
哈希連接不一定會排序,或者說大多數情況下都不需要排序;
哈希連接的驅動表所對應的連接列的可選擇性應盡可能的好,因為這個可選擇性會影響對應Hash Bucket中的記錄數,而Hash Bucket中的記錄數又會直接影響從該Hash Bucket中查找匹配記錄的效率;如果一個Hash Bucket裡所包含的記錄數過多,則可能會嚴重降低所對應哈希連接的執行效率,此時典型的表現就是該哈希連接執行了很長時間都沒有結束,數據庫所在database server上的CPU占用率很高,但目標SQL所消耗的邏輯讀卻很低,因為此時大部分時間都耗費在了遍歷上述Hash Bucket裡的所有記錄上,而遍歷Hash Bucket裡記錄這個動作是發生在PGA的工作區裡,所以不耗費邏輯讀;
哈希連接只適用於CBO、它也只能用於等值連接條件(即使是哈希反連接,Oracle實際上也是將其轉換成了等價的等值連接);
哈希連接很適合於一個小表和大表之間的表連接,特別是在小表的連接列的可選擇性非常好的情況下,這時候哈希連接的執行時間就可以近似看作是和全表掃描那個大表所耗費的時間相當;
當兩個表做哈希連接時,如果這兩個表在施加了目標SQL中指定的謂詞條件(如果有的話)後得到的結果集中數據量較小的那個結果集所對應的Hash Table能夠完全被容納在內存中時(PGA的工作區),則此時的哈希連接的執行效率會非常高。
對於以上的說明有兩點不明:
第一個疑問已在作者博客裡詢問,第三個問題作者在他博客下面回答了讀者的疑問,"之所以用兩個hash函數是為了使各個hash bucket裡的值分布的更加均勻",另一個函數就是計算hash值了。
對於第二個問題,在另外一個作者的一篇博客中找到,"在將S表讀入內存分區時,oracle即記錄連接鍵的唯一值,構建成所謂的位圖向量",可見位圖向量記錄的是小表S的唯一鍵值:
引自:http://blog.163.com/chunlei_cl/blog/static/81843020146253596868/
原文:
深入理解Oracle表:三大表連接方式詳解之Hash Join的定義,原理,算法,成本,模式和位圖
Hash Join只能用於相等連接,且只能在CBO優化器模式下。相對於nested loop join,hash join更適合處理大型結果集
Hash Join的執行計劃第1個是hash表(build table),第2個探查表(probe table),一般不叫內外表,nested loop才有內外表
Hash表也就是所謂的內表,探查表所謂的外表
兩者的執行計劃形如:
nested loop
outer table --驅動表
inner table
hash join
build table (inner table) --驅動表
probe table (outer table)
先看一張圖片,大致了解Hash Join的過程:
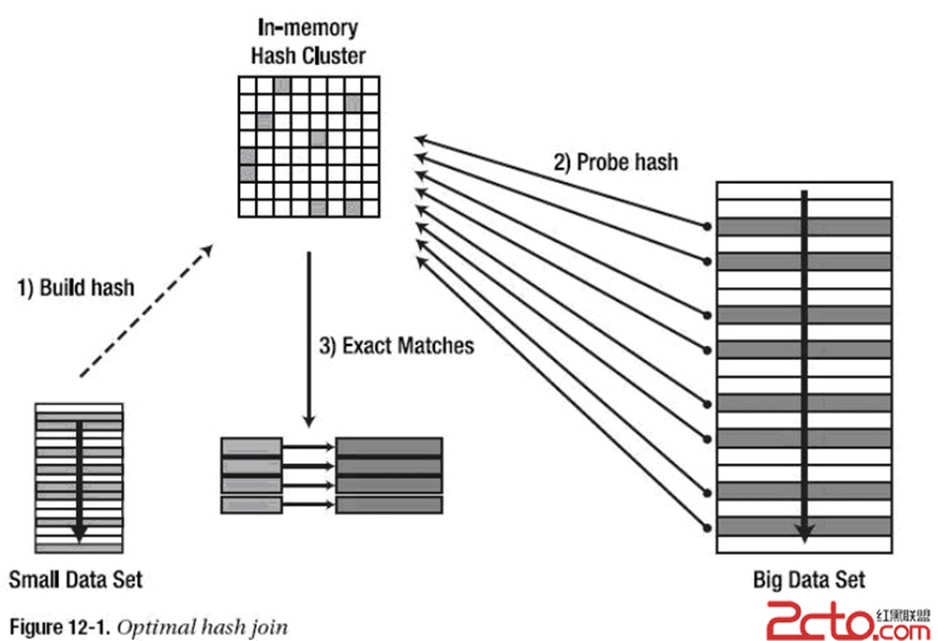
下面詳細了解一下Hash Join
㈠ Hash join概念
Hash join算法的一個基本思想就是根據小的row sources(稱作build input 也就是前文提到的build table,我們記較小的表為S,較大的表為B)
建立一個可以存在於hash area內存中的hash table
然後用大的row sources(稱作probe input,也就是前文提到的probe table) 來探測前面所建的hash table
如果hash area內存不夠大,hash table就無法完全存放在hash area內存中
針對這種情況,Oracle在連接鍵利用一個hash函數將build input和probe input分割成多個不相連的分區
分別記作Si和Bi,這個階段叫做分區階段;然後各自相應的分區,即Si和Bi再做Hash join,這個階段叫做join階段
如果HASH表太大,無法一次構造在內存中,則分成若干個partition,寫入磁盤的temporary segment,則會多一個寫的代價,會降低效率
至於小表的概念,對於 hash join 來說,能容納在 pga 中的 hash table 都可以叫小表,通常比如:
pga_aggregate_target big integer 1073741824
hash area size 大體能使用到40多 M ,這樣的話通常可能容納 幾十萬的記錄
hash area size缺省是2*sort_area_size,我們可以直接修改SORT_AREA_SIZE 的大小,HASH_AREA_SIZE也會跟著改變的
如果你的workarea_size_policy=auto,那麼我們只需設定pga_aggregate_target
但請記住,這是一個session級別的參數,有時,我們更傾向於把hash_area_size的大小設成驅動表的1.6倍左右
驅動表僅僅用於nested loop join 和 hash join,但Hash join不需要在驅動表上存在索引,而nested loop join則迫切需求
一兩百萬記錄的表 join上 千萬記錄的表,hash join的通常表現非常好
不過,多與少,大與小,很多時候很難量化,具體情況還得具體分析
如果在分區後,針對某個分區所建的hash table還是太大的話,oracle就采用nested loop hash join
所謂的nested-loops hash join就是對部分Si建立hash table,然後讀取所有的Bi與所建的hash table做連接
然後再對剩余的Si建立hash table,再將所有的Bi與所建的hash table做連接,直至所有的Si都連接完了
㈡ Hash Join原理
考慮以下兩個數據集:
S={1,1,1,3,3,4,4,4,4,5,8,8,8,8,10}
B={0,0,1,1,1,1,2,2,2,2,2,2,3,8,9,9,9,10,10,11}
Hash Join的第一步就是判定小表(即build input)是否能完全存放在hash area內存中
如果能完全存放在內存中,則在內存中建立hash table,這是最簡單的hash join
如果不能全部存放在內存中,則build input必須分區。分區的個數叫做fan-out
Fan-out是由hash_area_size和cluster size來決定的。其中cluster size等於db_block_size * _hash_multiblock_io_count
hash_multiblock_io_count是個隱藏參數,在9.0.1以後就不再使用了
[sql]
sys@ORCL> ed
Wrote file afiedt.buf
1 select a.ksppinm name,b.ksppstvl value,a.ksppdesc description
2 from x$ksppi a,x$ksppcv b
3 where a.indx = b.indx
4* and a.ksppinm like '%hash_multiblock_io_count%'
sys@ORCL> /
NAME VALUE DESCRIPTION
------------------------------ ----- ------------------------------------------------------------
_hash_multiblock_io_count 0 number of blocks hash join will read/write at once
Oracle采用內部一個hash函數作用於連接鍵上,將S和B分割成多個分區
在這裡我們假設這個hash函數為求余函數,即Mod(join_column_value,10)
這樣產生十個分區,如下表:
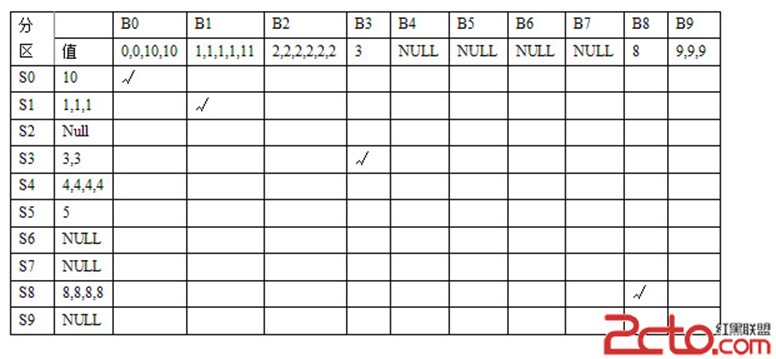
經過這樣的分區之後,只需要相應的分區之間做join即可(也就是所謂的partition pairs)
如果有一個分區為NULL的話,則相應的分區join即可忽略
在將S表讀入內存分區時,oracle即記錄連接鍵的唯一值,構建成所謂的位圖向量
它需要占hash area內存的5%左右。在這裡即為{1,3,4,5,8,10}
當對B表進行分區時,將每一個連接鍵上的值與位圖向量相比較,如果不在其中,則將其記錄丟棄
在我們這個例子中,B表中以下數據將被丟棄{0,0,2,2,2,2,2,2,9,9,9,9,9}
這個過程就是位圖向量過濾
當S1,B1做完連接後,接著對Si,Bi進行連接
這裡oracle將比較兩個分區,選取小的那個做build input,就是動態角色互換
這個動態角色互換發生在除第一對分區以外的分區上面
㈢ Hash Join算法
第1步:判定小表是否能夠全部存放在hash area內存中,如果可以,則做內存hash join。如果不行,轉第二步
第2步:決定fan-out數
(Number of Partitions) * C<= Favm *M
其中C為Cluster size,其值為DB_BLOCK_SIZE*HASH_MULTIBLOCK_IO_COUNT
Favm為hash area內存可以使用的百分比,一般為0.8左右
M為Hash_area_size的大小
第3步:讀取部分小表S,采用內部hash函數(這裡稱為hash_fun_1)
將連接鍵值映射至某個分區,同時采用hash_fun_2函數對連接鍵值產生另外一個hash值
這個hash值用於創建hash table用,並且與連接鍵值存放在一起
第4步:對build input建立位圖向量
第5步:如果內存中沒有空間了,則將分區寫至磁盤上
第6步:讀取小表S的剩余部分,重復第三步,直至小表S全部讀完
第7步:將分區按大小排序,選取幾個分區建立hash table(這裡選取分區的原則是使選取的數量最多)
第8步:根據前面用hash_fun_2函數計算好的hash值,建立hash table
第9步:讀取表B,采用位圖向量進行位圖向量過濾
第10步:對通過過濾的數據采用hash_fun_1函數將數據映射到相應的分區中去,並計算hash_fun_2的hash值
第11步:如果所落的分區在內存中,則將前面通過hash_fun_2函數計算所得的hash值與內存中已存在的hash table做連接
將結果寫致磁盤上。如果所落的分區不在內存中,則將相應的值與表S相應的分區放在一起
第12步:繼續讀取表B,重復第9步,直至表B讀取完畢
第13步:讀取相應的(Si,Bi)做hash連接。在這裡會發生動態角色互換
第14步:如果分區過後,最小的分區也比內存大,則發生nested-loop hash join
㈣ Hash Join的成本
⑴ In-Memory Hash Join
Cost(HJ)=Read(S)+ build hash table in memory(CPU)+Read(B) + Perform In memory Join(CPU)
忽略cpu的時間,則:
Cost(HJ)=Read(S)+Read(B)
⑵ On-Disk Hash Join
根據上述的步驟描述,我們可以看出:
Cost(HJ)=Cost(HJ1)+Cost(HJ2)
其中Cost(HJ1)的成本就是掃描S,B表,並將無法放在內存上的部分寫回磁盤,對應前面第2步至第12步
Cost(HJ2)即為做nested-loop hash join的成本,對應前面的第13步至第14步
其中Cost(HJ1)近似等於Read(S)+Read(B)+Write((S-M)+(B-B*M/S))
因為在做nested-loop hash join時,對每一chunk的build input,都需要讀取整個probe input,因此
Cost(HJ2)近似等於Read((S-M)+n*(B-B*M/S)),其中n是nested-loop hash join需要循環的次數:n=(S/F)/M
一般情況下,如果n大於10的話,hash join的性能將大大下降
從n的計算公式可以看出,n與Fan-out成反比例,提高fan-out,可以降低n
當hash_area_size是固定時,可以降低cluster size來提高fan-out
從這裡我們可以看出,提高hash_multiblock_io_count參數的值並不一定提高hash join的性能
㈤ Hash Join的過程
一次完整的hash join如下:
1 計算小表的分區(bucket)數--Hash分桶
決定hash join的一個重要因素是小表的分區(bucket)數
這個數字由hash_area_size、hash_multiblock_io_count和db_block_size參數共同決定
Oracle會保留hash area的20%來存儲分區的頭信息、hash位圖信息和hash表
因此,這個數字的計算公式是:
Bucket數=0.8*hash_area_size/(hash_multiblock_io_count*db_block_size)
2 Hash計算
讀取小表數據(簡稱為R),並對每一條數據根據hash算法進行計算
Oracle采用兩種hash算法進行計算,計算出能達到最快速度的hash值(第一hash值和第二hash值)
而關於這些分區的全部hash值(第一hash值)就成為hash表
3 存放數據到hash內存中
將經過hash算法計算的數據,根據各個bucket的hash值(第一hash值)分別放入相應的bucket中
第二hash值就存放在各條記錄中
4 創建hash位圖
與此同時,也創建了一個關於這兩個hash值映射關系的hash位圖
5 超出內存大小部分被移到磁盤
如果hash area被占滿,那最大一個分區就會被寫到磁盤(臨時表空間)上去
任何需要寫入到磁盤分區上的記錄都會導致磁盤分區被更新
這樣的話,就會嚴重影響性能,因此一定要盡量避免這種情況
2-5一直持續到整個表的數據讀取完畢
6 對分區排序
為了能充分利用內存,盡量存儲更多的分區,Oracle會按照各個分區的大小將他們在內存中排序
7 讀取大表數據,進行hash匹配
接下來就開始讀取大表(簡稱S)中的數據
按順序每讀取一條記錄,計算它的hash值,並檢查是否與內存中的分區的hash值一致
如果是,返回join數據
如果內存中的分區沒有符合的,就將S中的數據寫入到一個新的分區中,這個分區也采用與計算R一樣的算法計算出hash值
也就是說這些S中的數據產生的新的分區數應該和R的分區集的分區數一樣。這些新的分區被存儲在磁盤(臨時表空間)上
8 完全大表全部數據的讀取
一直按照7進行,直到大表中的所有數據的讀取完畢
9 處理沒有join的數據
這個時候就產生了一大堆join好的數據和從R和S中計算存儲在磁盤上的分區
10 二次hash計算
從R和S的分區集中抽取出最小的一個分區,使用第二種hash函數計算出並在內存中創建hash表
采用第二種hash函數的原因是為了使數據分布性更好
11 二次hash匹配
在從另一個數據源(與hash在內存的那個分區所屬數據源不同的)中讀取分區數據,與內存中的新hash表進行匹配。返回join數據
12 完成全部hash join
繼續按照9-11處理剩余分區,直到全部處理完畢
㈥ Hash Join的模式
Oracle中,Hash Join也有三種模式:optimal,one-pass,multi-pass
⑴ optimal
當驅動結果集生成的hash表全部可以放入PGA的hash area時,稱為optimal,大致過程如下:
① 先根據驅動表,得到驅動結果集
② 在hash area生成hash bulket,並將若干bulket分成一組,成為一個partition,還會生成一個bitmap的列表,每個bulket在上面占一位
③ 對結果集的join鍵做hash運算,將數據分散到相應partition的bulket中
當運算完成後,如果鍵值唯一性較高的話,bulket裡的數據會比較均勻,也有可能有的桶裡面數據會是空的
這樣bitmap上對應的標志位就是0,有數據的桶,標志位會是1
④ 開始掃描第二張表,對jion鍵做hash運算,確定應該到某個partition的某個bulket去探測
探測之前,會看這個bulket的bitmap是否會1,如果為0,表示沒數據,這行就直接丟棄掉
⑤ 如果bitmap為1,則在桶內做精確匹配,判斷OK後,返回數據
這個是最優的hash join,他的成本基本是兩張表的full table scan,在加微量的hash運算
博客開篇的那幅圖描述的也就是這種情況
⑵ one-pass
如果進程的pga很小,或者驅動表結果集很大,超過了hash area的大小,會怎麼辦?
當然會用到臨時表空間,此時oracle的處理方式稍微復雜點需奧注意上面提到的有個partition的概念
可以這麼理解,數據是經過兩次hash運算的,先確定你的partition,再確定你的bulket
假設hash area小於整個hash table,但至少大於一個partition的size,這個時候走的就是one-pass
當我們生成好hash表後,狀況是部分partition留在內存中,其他的partition留在磁盤臨時表空間中
當然也有可能某個partition一半在內存,一半在磁盤,剩下的步驟大致如下:
① 掃描第二張表,對join鍵做hash運算,確定好對應的partition和bulket
② 查看bitmap,確定bulket是否有數據,沒有則直接丟棄
③ 如果有數據,並且這個partition是在內存中的,就進入對應的桶去精確匹配,能匹配上,就返回這行數據,否則丟棄
④ 如果partition是在磁盤上的,則將這行數據放入磁盤中暫存起來,保存的形式也是partition,bulket的方式
⑤ 當第二張表被掃描完後,剩下的是驅動表和探測表生成的一大堆partition,保留在磁盤上
⑥ 由於兩邊的數據都按照相同的hash算法做了partition和bulket,現在只要成對的比較兩邊partition數據即可
並且在比較的時候,oracle也做了優化處理,沒有嚴格的驅動與被驅動關系
他會在partition對中選較小的一個作為驅動來進行,直到磁盤上所有的partition對都join完
可以發現,相比optimal,他多出的成本是對於無法放入內存的partition,重新讀取了一次,所以稱為one-pass
只要你的內存保證能裝下一個partition,oracle都會騰挪空間,每個磁盤partition做到one-pass
⑶ multi-pass
這是最復雜,最糟糕的hash join
此時hash area小到連一個partition也容納不下,當掃描好驅動表後
可能只有半個partition留在hash area中,另半個加其他的partition全在磁盤上
剩下的步驟和one-pass比價類似,不同的是針對partition的處理
由於驅動表只有半個partition在內存中,探測表對應的partition數據做探測時
如果匹配不上,這行還不能直接丟棄,需要繼續保留到磁盤,和驅動表剩下的半個partition再做join
這裡舉例的是內存可以裝下半個partition,如果裝的更少的話,反復join的次數將更多
當發生multi-pass時,partition物理讀的次數會顯著增加
㈦ Hash Join的位圖
這個位圖包含了每個hash分區是否有有值的信息。它記錄了有數據的分區的hash值
這個位圖的最大作用就是,如果probe input中的數據沒有與內存中的hash表匹配上
先查看這個位圖,以決定是否將沒有匹配的數據寫入磁盤
那些不可能匹配到的數據(即位圖上對應的分區沒有數據)就不再寫入磁盤
㈧ 小結
① 確認小表是驅動表
② 確認涉及到的表和連接鍵分析過了
③ 如果在連接鍵上數據不均勻的話,建議做柱狀圖
④ 如果可以,調大hash_area_size的大小或pga_aggregate_target的值
⑤ Hash Join適合於小表與大表連接、返回大型結果集的連接