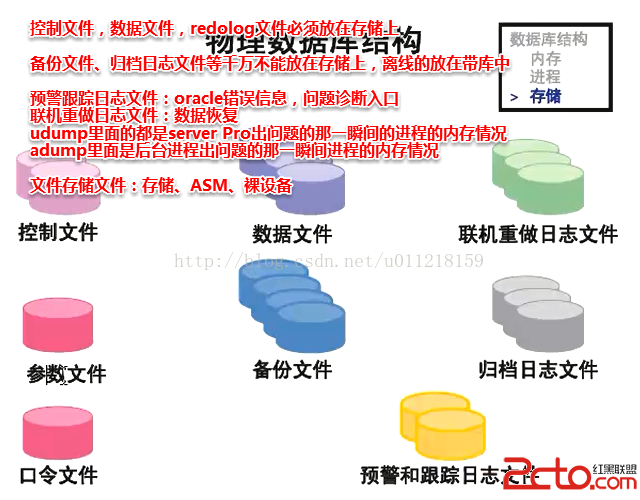
數據抽象:物理抽象、概念抽象、視圖級抽象,內模式、模式、外模式
SQL語言包括數據定義、數據操縱(data manipulation),數據控制(data control)
數據定義:create table,alter table,drop table, craete/drop index等
數據操縱:select ,insert,update,delete,
數據控制:grant,revoke
創建:create database database-name
刪除:drop database dbname
創建表:
綜合評價:★★
create table tabname(col1 type1 [not null][primary key],col2 type2 [not null],..)
根據已有的表創建新表:
(1)建一個新表,架構、字段屬性、約束條件、數據記錄跟舊表完全一樣:
create tabletab_new as select col1,col2…from tab_old;
(2)建一個新表,架構跟舊表完全一樣,但沒有內容:
create tabletab_new as select * from tab_old where 1=2;
刪除表:
drop table tabname;--刪除表結構
只刪除表數據:
delete from tabname;(dml操作需要事務提交)
truncate table tabname;(ddl操作立即生效)
修改表:
修改表名:alter table skate_test rename to table_name
添加表注釋:comment on table scott. table_name is '注釋內容';
添加列注釋:comment column on table_name.column_name is '注釋內容';
添加:alter table tablename add (column datatype [defaultvalue][null/not null],….);
修改:alter table tablename modify(column datatype [default value][null/not null],….);
刪除:alter table tablename drop(column);
注:列增加後將不能刪除。db2中列加上後數據類型也不能改變,唯一能改變的是增加varchar類型的長度。
cascade 關鍵字主要用於級聯,級聯刪除、級聯更新等,綜合評價:★★
刪除用戶:drop user user_name; 刪除用戶,drop user user_name cascade; 刪除此用戶名下的所有表和視圖
alter table table_name add constraint fk_tn_dept foreign key(dept) references dept(deptno) ([on delete set null],[on delete cascade]);
1、創建表的同時創建主鍵約束
(1)無命名
create table student (
studentid int primary key not null,
studentname varchar(8),
ageint);
(2)有命名
create table students (
studentid int ,
studentname varchar(8),
age int,
constraint yy primary key(pk_studentid));
2、向表中添加主鍵約束
alter table student add constraint pk_studentprimary key(pk_studentid);
3、刪除表中已有的主鍵約束
(1)有命名
alter table students drop constraint yy;
(2)無命名
可用SELECT * FROM user_cons_columns WHEREtable_name = ’ student’
查找表中主鍵名稱得student表中的主鍵名為SYS_C002715
alter table student drop constraintSYS_C002715;
主鍵與外鍵
主鍵是表格裡的(一個或多個)字段,只用來定義表格裡的行;主鍵裡的值總是唯一的。
外鍵是一個用來建立兩個表格之間關系的約束。這種關系一般都涉及一個表格裡的主鍵字段與另外一個表格(盡管可能是同一個表格)裡的一系列相連的字段。那麼這些相連的字段就是外鍵。
創建:create [unique] index idx_name on tabname(col_name….)
刪除:drop index idxname
注:索引是不可更改的,想更改必須刪除重新建。
索引作用:
第一、通過創建唯一性索引,可以保證數據庫表中每一行數據的唯一性。
第二、可以大大加快數據的檢索速度,這也是創建索引的最主要的原因。
第三、可以加速表和表之間的連接,特別是在實現數據的參考完整性方面特別有意義。
第四、在使用分組和排序子句進行數據檢索時,同樣可以顯著減少查詢中分組和排序的時間。
第五, 通過使用索引,可以在查詢的過程中,使用優化隱藏器,提高系統的性能。
索引的作用?和它的優點缺點是什麼?
索引就一種特殊的查詢表,數據庫的搜索引擎可以利用它加速對數據的檢索。
優點:它很類似與現實生活中書的目錄,不需要查詢整本書內容就可以找到想要的數據。索引可以是唯一的,創建索引允許指定單個列或者是多個列。
缺點:是它減慢了數據錄入的速度,同時也增加了數據庫的尺寸大小。
創建、修改:create or replace view view_name as select statement
刪除:drop view view_name
選擇:select * from table1 where 范圍
插入:insert into table1(field1,field2) values(value1,value2)
刪除:delete from table1 where 范圍
更新:update table1 set field1=value1 where 范圍
查找:select * from table1 where field1 like ’%value1%’ ---like語法★★★
排序:select * from table1 order by field1,field2 [desc]
總數:select count(*) as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
a:union 運算符
union 運算符通過組合其他兩個結果表(例如table1 和 table2)並消去表中任何重復行而派生出一個結果表。當 all 隨 union 一起使用時(即 union all),不消除重復行。兩種情況下,派生表的每一行不是來自 table1 就是來自 table2。
b:minus 運算符
minus 運算符通過包括所有在 table1 中但不在 table2 中的行並消除所有重復行而派生出一個結果表。
c:intersect 運算符
intersect 運算符通過只包括 table1 和 table2 中都有的行並消除所有重復行而派生出一個結果表。
內連接,只連接匹配的行
selecta.c1,b.c2 from a join b on a.c3 = b.c3;
左外連接
包含左邊表的全部行以及右邊表中全部匹配的行
selecta.c1,b.c2 from a left join b on a.c3 = b.c3;
右外連接
包含右邊表的全部行以及左邊表中全部匹配的行
selecta.c1,b.c2 from a right join b on a.c3 = b.c3;
全外連接
綜合評價:★★
包含左、右兩個表的全部行
selecta.c1,b.c2 from a full join b on a.c3 = b.c3;
非等連接
使用等值以外的條件來匹配左、右兩個表中的行
selecta.c1,b.c2 from a join b on a.c3 != b.c3;
自連接
使用同一張表中的不同字段進行匹配
select *from t1 a,t1 b where a.a1 = b.a3
交叉連接
綜合評價:★★
生成笛卡爾積——它不使用任何匹配或者選取條件,而是直接將一個數據源中的每個行與另一個數據源的每個行一一匹
配
select a.c1,b.c2 from a,b;
多表關聯
select * from a left inner join b ona.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
內聯接,外聯接區別:內連接是保證兩個表中所有的行都要滿足連接條件,而外連接則不然。
在外連接中,某些不滿條件的列也會顯示出來,也就是說,只限制其中一個表的行,而不限制另一個表的行。分左連接、右連接、全連接三種
oracle8i,9i 表連接方法。
一般的相等連接: select * from a, b where a.id = b.id; 這個就屬於內連接。
對於外連接:
oracle中可以使用“(+) ”來表示,9i可以使用left/right/fullouter join
leftouter join:左外關聯
selecte.last_name, e.department_id, d.department_name
fromemployees e
leftouter join departments d
on(e.department_id = d.department_id);
等價於
selecte.last_name, e.department_id, d.department_name
fromemployees e, departments d
wheree.department_id=d.department_id(+)
結果為:所有員工及對應部門的記錄,包括沒有對應部門編號department_id的員工記錄。
rightouter join:右外關聯
selecte.last_name, e.department_id, d.department_name
fromemployees e
rightouter join departments d
on(e.department_id = d.department_id);
等價於
selecte.last_name, e.department_id, d.department_name
fromemployees e, departments d
wheree.department_id(+)=d.department_id
結果為:所有員工及對應部門的記錄,包括沒有任何員工的部門記錄。
fullouter join:全外關聯
selecte.last_name, e.department_id, d.department_name
fromemployees e
fullouter join departments d
on(e.department_id = d.department_id);
結果為:所有員工及對應部門的記錄,包括沒有對應部門編號department_id的員工記錄和沒有任何員工的部門記錄。
oracle8i是不能在左右兩個表上同時加上(+),轉換成一個左聯接一個右連接
全外連接語法
綜合評價: ★★
selectt1.id,t2.id from table1 t1,table t2 where t1.id=t2.id(+)
union
selectt1.id,t2.id from table1 t1,table t2 where t1.id(+)=t2.id
綜合評價:★★★
關聯子查詢是一種包含子查詢的特殊類型的查詢。查詢裡包含的子查詢會真正請求外部查詢的值,從而形成一個類似於循環的狀況。
子查詢:
注:表名1:a 表名2:b
select a,b,c from a where a in (select dfrom b) 或者: select a,b,c froma where a in (1,2,3)
關聯子查詢:
顯示文章、提交人和最後回復時間
select a.title,a.username,b.adddate fromtable a, (selectmax(adddate) adddate from table where table.title=a.title) b where b.adddate = a.adddate;——需要顯示B表中的字段
scott模式中,找出每個部門中最高工資的人
select a.deptno, a.* from emp a
where a.sal = (select max(b.sal)from emp b where b.deptno = a.deptno) ;——不需要顯示B表中的字段
綜合評價:★★
between 使用方法
between的用法,between限制查詢數據范圍時包括了邊界值,not between不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 數值1 and 數值2
in 的使用方法
select * from table1 where a [not] in (‘值1’,’值2’,’值4’,’值6’)
exists 的使用方法
注:存在兩張表,table1 table2
select * from table1 t1 where [not] exists(select * from table2 t2 where t1.id = t2.id)
in、exists使用區別:如果兩個表中一個較小,一個是大表,則子查詢表大的用exists,子查詢表小的用in
綜合評價:★★
insert into select語句
語句形式為:insert into table2(field1,field2,...) select value1,value2,... from table1
注意:
(1)要求目標表table2必須存在,並且字段field,field2...也必須存在
(2)注意table2的主鍵約束,如果table2有主鍵而且不為空,則 field1, field2...中必須包括主鍵
select into from語句
語句形式為:select vale1, value2 into table2 from table1;
對比:create table tab_new as select col1,col2…from tab_old;
要求目標表table2不存在,因為在插入時會自動創建表table2,並將table1中指定字段數據復制到table2中
SQL 優化的實質:在保證結果正確的前提下,充份利用索引,減少表掃描的 I/O 次數,盡量少訪問數據塊,盡量避免全表掃描和其他額外開銷。
oracle 常用的兩種優化器:RBO(rule-based-optimizer)和CBO(cost-based-optimizer)。 目前更多地采用CBO(cost-based-optimizer)基於開銷的優化器。在 CBO 方式下,Oracle 會根據表及索引的狀態信息來選擇計劃;在 RBO 方 式下 ,Oracle 會根據自己內部設置的一些 規則來決定選擇計劃。
基本上所有的 IN 操作符都可以用EXISTS 代替。IN 和EXISTS 操作的選擇要根據主子表數據量大小來具體考慮。
因為 NOT IN 不能應用表的索引
綜合評價:★★
不等於操作符是通過全表掃描處理,大於或者小於會使用標的索引。如:a<>0改為 a>0 or a<0
判斷字段否為空是不會應用索引,因為 B 樹索引不會索引空值的。
當通配符“%”或者“_”作為查詢字符串的第一個字符時,索引不會被使用 。比如用 T 表中 Column1LIKE ‘%5400%’ 這個條件會產生全表掃描,如果改成 Column1 LIKE ’X5400%’ OR Column1 LIKE ’B5400%’ 則會利用 Column1 的索引進行兩個范圍的查詢。
如果索引不是基於函數的,那麼當在 Where 子句中對索引列使用函數時索引不再起作用。比如:substr(no,1,4)=’5400’,優化處理:no like ‘5400%’
trunc(hiredate)=trunc(sysdate) ,優化處理:hiredate >=trunc(sysdate) and hiredate<trunc(sysdate+1)
綜合評價:★★
大於或小於操作符一般情況下是不用調整的,因為它有索引就會采用索引查找,但有的情況下可以對它進行優化,如一個表有 100 萬記錄,一個數值型字段 A, 30 萬記 錄的 A=0,30 萬記錄的 A=1,39 萬記錄的 A=2,1 萬記錄的 A=3。那麼執行 A>2 與 A>=3 的效果就有很大的區別了,因為 A>2時 ORACLE 會先找出為 2 的記錄索引再進行比較,而 A>=3 時 ORACLE 則直接找到=3 的記錄索引
同一功能同一性能不同寫法 SQL的影響。 如一個 SQL 在
A 程序員寫的為:
Select * from zl_yhjbqk;
B 程序員寫的為:
Select * from dlyx.zl_yhjbqk(帶表所有者的前綴);
C 程序員寫的為:
Select * from DLYX.ZLYHJBQK(大寫表名);
D 程序員寫的為:
Select * from DLYX.ZLYHJBQK(中間多了空格)。
以上四個 SQL 在 ORACLE 分析整理之後產生的結果及執行的時間是一樣的,但是從ORACLE 共享內存 SGA 的原理,可以得出 ORACLE 對每個 SQL 都會對其進行一次分析,並且占用共享內存,如果將 SQL 的字符串及格式寫得完全相同則 ORACLE 只會分析一次,共享內存也只會留下一次的分析結果,這不僅可以減少分析 SQL 的時間,而且可以減少共享內存重復的信息,ORACLE 也可以准確統計 SQL 的執行頻率。
不同區域出現的相同的 SQL 語句要保證查詢字符完全相同,建議經常使用變量來代替常量,以盡量使用重復 SQL 代碼,以利用 SGA 共享池,避開 parse 階段,防止相同的 SQL 語句被多次分析,提高執行速度。因此使用存儲過程,是一種很有效的提高 share pool 共享率,跳過 parse 階段,提高效率的辦法。
綜合評價:★★
WHERE 後面的條件,表連接語句寫在最前,可以過濾掉最大數量記錄的條件最後。ORACLE采用自下而上的順序解析WHERE子句,根據這個原理,表之間的連接必須寫在其他WHERE條件之前, 那些可以過濾掉最大數量記錄的條件必須寫在WHERE子句的末尾。
當在 SQL 語句中連接多個表時,使用表的別名,並將之作為每列的前綴。這樣可以減少解析時間
綜合評價:★★
比如:
ss_df+20>50,優化處理:ss_df>30
‘X’||hbs_bh>’X5400021452’,優化處理:hbs_bh>’5400021542’
sk_rq+5=sysdate,優化處理:sk_rq=sysdate-5
hbs_bh=5401002554,優化處理:hbs_bh=’ 5401002554’,注:此條件對hbs_bh 進行隱式的 to_number 轉換,因為 hbs_bh 字段是字符型。
UNION 是最常用的集操作,使多個記錄集聯結成為單個集,對返回的數據行有唯一性要求, 所以 oracle 就需要進行 SORTUNIQUE 操作(與使用 distinct 時操作類似),如果結果集又比較大,則操作會比較慢;
UNION ALL 操作不排除重復記錄行,所以會快很多,如果數據本身重復行存在可能性較小時,用 union all 會比用 union 效率高很多!
綜合評價:★★
盡量使用 packages: Packages 在第一次調用時能將整個包 load 進內存,對提高性能有幫助。s
盡量使用 cached sequences來生成 primary key :提高主鍵生成速度和使用性能。很好地利用空間:如用 VARCHAR2 數據類型代替 CHAR 等
使用 SQL 優化工具:SQLexpert;toad;explain-table;PL/SQL;OEM
綜合評價:★★★
SGA:數據庫的系統全局區。
SGA 主要由三部分構成:共享池、數據緩沖區、日志緩沖區
1、 共享池又由兩部分構成:共享 SQL 區和數據字典緩沖區。共享SQL 區專門存放用戶 SQL 命令,oracle 使用最近最少使用等優先級算法來更新覆蓋;數據字典緩沖區(library cache)存放數據庫運行的動態信息。數據庫運行一段時間後, DBA 需要查看這些內存區域的命中率以從數據庫角度對數據庫性能調優。通過執行下述語句查看:
select (sum(pins - reloads)) / sum(pins)"Lib Cache" from v$librarycache;
--查看共享 SQL 區的重用率,最好在 90%以上,否則需要增加共享池的大小。 select (sum(gets - getmisses - usage - fixED)) / sum(gets) "Row Cache" fromv$rowcache;
--查看數據字典緩沖區的命中率,最好在 90%以上,否則需要增加共享池的大小。
2、 數據緩沖區:存放 SQL 運行結果抓取到的 datablock;
SELECT name, value FROM v$sysstat WHERE name IN ('db block gets',
'consistent gets','physical reads');
--查看數據庫數據緩沖區的使用情況。查詢出來的結果可以計算出來數據緩沖區 的使用命中率=1 - (physical reads / (db block gets + consistent gets) )。命中率應該 在 90%以上,否則需要增加數據緩沖區的大小。
3、 日志緩沖區:存放數據庫運行生成的日志。
select name,value from v$sysstat where name in ('redo entries','redo log space requests');
--查看日志緩沖區的使用情況。查詢出的結果可以計算出日志緩沖區的申請失敗
率:申請失敗率=requests/entries,申請失敗率應該接近於 0,否則說明日志緩沖區開設太小,需要增加 ORACLE 數據庫的日志緩沖區。
檢查系統的i/o問題
sar-d能檢查整個系統的iostat(iostatistics)
查看該SQL的response time(db block gets/consistentgets/physical reads/sorts (disk))
ORACLE的優化器共有3種:a. RULE (基於規則) b. COST(基於成本) c. CHOOSE (選擇性)
設置缺省的優化器,可以通過對init.ora文件中OPTIMIZER_MODE參數的各種聲明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS. 你當然也在SQL句級或是會話(session)級對其進行覆蓋.
為了使用基於成本的優化器(CBO, Cost-Based Optimizer) , 你必須經常運行analyze 命令,以增加數據庫中的對象統計信息(object statistics)的准確性.
如果數據庫的優化器模式設置為選擇性(CHOOSE),那麼實際的優化器模式將和是否運行過analyze命令有關. 如果table已經被analyze過, 優化器模式將自動成為CBO , 反之,數據庫將采用RULE形式的優化器.
在缺省情況下,ORACLE采用CHOOSE優化器, 為了避免那些不必要的全表掃描(full table scan) , 你必須盡量避免使用CHOOSE優化器,而直接采用基於規則或者基於成本的優化器.
ORACLE 采用兩種訪問表中記錄的方式:
a. 全表掃描
全表掃描就是順序地訪問表中每條記錄.ORACLE采用一次讀入多個數據塊(database block)的方式優化全表掃描.
b. 通過ROWID訪問表
你可以采用基於ROWID的訪問方式情況,提高訪問表的效率, ,ROWID包含了表中記錄的物理位置信息..ORACLE采用索引(INDEX)實現了數據和存放數據的物理位置(ROWID)之間的聯系. 通常索引提供了快速訪問ROWID的方法,因此那些基於索引列的查詢就可以得到性能上的提高.
為了不重復解析相同的SQL語句,在第一次解析之後,ORACLE將SQL語句存放在內存中.這塊位於系統全局區域SGA(system global area)的共享池(shared bufferpool)中的內存可以被所有的數據庫用戶共享. 因此,當你執行一個SQL語句(有時被稱為一個游標)時,如果它和之前的執行過的語句完全相同,ORACLE就能很快獲得已經被解析的語句以及最好的執行路徑. ORACLE的這個功能大大地提高了SQL的執行性能並節省了內存的使用.可惜的是ORACLE只對簡單的表提供高速緩沖(cache buffering) ,這個功能並不適用於多表連接查詢.數據庫管理員必須在init.ora中為這個區域設置合適的參數,當這個內存區域越大,就可以保留更多的語句,當然被共享的可能性也就越大了.
當你向ORACLE 提交一個SQL語句,ORACLE會首先在這塊內存中查找相同的語句.這裡需要注明的是,ORACLE對兩者采取的是一種嚴格匹配,要達成共享,SQL語句必須完全相同(包括空格,換行等).
共享的語句必須滿足三個條件:
A. 字符級的比較:當前被執行的語句和共享池中的語句必須完全相同.
B. 兩個語句所指的對象必須完全相同:
C. 兩個SQL語句中必須使用相同的名字的綁定變量(bind variables)
ORACLE的解析器按照從右到左的順序處理FROM子句中的表名,因此FROM子句中寫在最後的表(基礎表 driving table)將被最先處理. 在FROM子句中包含多個表的情況下,你必須選擇記錄條數最少的表作為基礎表.當ORACLE處理多個表時, 會運用排序及合並的方式連接它們.首先,掃描第一個表(FROM子句中最後的那個表)並對記錄進行派序,然後掃描第二個表(FROM子句中最後第二個表),最後將所有從第二個表中檢索出的記錄與第一個表中合適記錄進行合並.
例如:
表 TAB1 16,384 條記錄
表 TAB2 1 條記錄
選擇TAB2作為基礎表 (最好的方法)
select count(*) from tab1,tab2 執行時間0.96秒
選擇TAB2作為基礎表 (不佳的方法)
select count(*) from tab2,tab1 執行時間26.09秒
如果有3個以上的表連接查詢, 那就需要選擇交叉表(intersection table)作為基礎表, 交叉表是指那個被其他表所引用的表.
例如:
EMP表描述了LOCATION表和CATEGORY表的交集.
SELECT *
FROM LOCATION L ,
CATEGORY C,
EMP E
WHERE E.EMP_NO BETWEEN 1000 AND 2000
AND E.CAT_NO = C.CAT_NO
AND E.LOCN = L.LOCN
將比下列SQL更有效率
SELECT *
FROM EMP E ,
LOCATION L ,
CATEGORY C
WHERE E.CAT_NO = C.CAT_NO
AND E.LOCN = L.LOCN
AND E.EMP_NO BETWEEN 1000 AND 2000
5. WHERE子句中的連接順序.
ORACLE采用自下而上的順序解析WHERE子句,根據這個原理,表之間的連接必須寫在其他WHERE條件之前, 那些可以過濾掉最大數量記錄的條件必須寫在WHERE子句的末尾.
例如:
(低效,執行時間156.3秒)
SELECT …
FROM EMP E
WHERE SAL > 50000
AND JOB = ‘MANAGER’
AND 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO);
(高效,執行時間10.6秒)
SELECT …
FROM EMP E
WHERE 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO)
AND SAL > 50000
AND JOB = ‘MANAGER’;
6. SELECT子句中避免使用 ‘ * ‘
當你想在SELECT子句中列出所有的COLUMN時,使用動態SQL列引用 ‘*’ 是一個方便的方法.不幸的是,這是一個非常低效的方法. 實際上,ORACLE在解析的過程中, 會將’*’ 依次轉換成所有的列名, 這個工作是通過查詢數據字典完成的, 這意味著將耗費更多的時間.
7. 減少訪問數據庫的次數
當執行每條SQL語句時, ORACLE在內部執行了許多工作: 解析SQL語句, 估算索引的利用率, 綁定變量 , 讀數據塊等等. 由此可見, 減少訪問數據庫的次數 , 就能實際上減少ORACLE的工作量.
例如,
以下有三種方法可以檢索出雇員號等於0342或0291的職員.
方法1 (最低效)
SELECT EMP_NAME , SALARY , GRADE
FROM EMP
WHERE EMP_NO = 342;
SELECT EMP_NAME , SALARY , GRADE
FROM EMP
WHERE EMP_NO = 291;
方法2 (次低效)
DECLARE
CURSOR C1 (E_NO NUMBER) IS
SELECT EMP_NAME,SALARY,GRADE
FROM EMP
WHERE EMP_NO = E_NO;
BEGIN
OPEN C1(342);
FETCH C1 INTO …,..,.. ;
…..
OPEN C1(291);
FETCH C1 INTO …,..,.. ;
CLOSE C1;
END;
方法3 (高效)
SELECT A.EMP_NAME , A.SALARY ,A.GRADE,
B.EMP_NAME , B.SALARY , B.GRADE
FROM EMP A,EMP B
WHERE A.EMP_NO = 342
AND B.EMP_NO = 291;
注意:
在SQL*Plus , SQL*Forms和Pro*C中重新設置ARRAYSIZE參數, 可以增加每次數據庫訪問的檢索數據量 ,建議值為200
ORACLE SQL性能優化系列 (三)
8. 使用DECODE函數來減少處理時間
使用DECODE函數可以避免重復掃描相同記錄或重復連接相同的表.
例如:
SELECT COUNT(*),SUM(SAL)
FROM EMP
WHERE DEPT_NO = 0020
AND ENAME LIKE ‘SMITH%’;
SELECT COUNT(*),SUM(SAL)
FROM EMP
WHERE DEPT_NO = 0030
AND ENAME LIKE ‘SMITH%’;
你可以用DECODE函數高效地得到相同結果
SELECT COUNT(DECODE(DEPT_NO,0020,’X’,NULL)) D0020_COUNT,
COUNT(DECODE(DEPT_NO,0030,’X’,NULL)) D0030_COUNT,
SUM(DECODE(DEPT_NO,0020,SAL,NULL))D0020_SAL,
SUM(DECODE(DEPT_NO,0030,SAL,NULL))D0030_SAL
FROM EMP WHERE ENAME LIKE ‘SMITH%’;
類似的,DECODE函數也可以運用於GROUP BY 和ORDER BY子句中.
9. 整合簡單,無關聯的數據庫訪問
如果你有幾個簡單的數據庫查詢語句,你可以把它們整合到一個查詢中(即使它們之間沒有關系)
例如:
SELECT NAME
FROM EMP
WHERE EMP_NO = 1234;
SELECT NAME
FROM DPT
WHERE DPT_NO = 10 ;
SELECT NAME
FROM CAT
WHERE CAT_TYPE = ‘RD’;
上面的3個查詢可以被合並成一個:
SELECT E.NAME , D.NAME , C.NAME
FROM CAT C , DPT D , EMP E,DUAL X
WHERE NVL(‘X’,X.DUMMY) = NVL(‘X’,E.ROWID(+))
AND NVL(‘X’,X.DUMMY) = NVL(‘X’,D.ROWID(+))
AND NVL(‘X’,X.DUMMY) = NVL(‘X’,C.ROWID(+))
AND E.EMP_NO(+) = 1234
AND D.DEPT_NO(+) = 10
AND C.CAT_TYPE(+) = ‘RD’;
(譯者按: 雖然采取這種方法,效率得到提高,但是程序的可讀性大大降低,所以讀者還是要權衡之間的利弊)
10. 刪除重復記錄
最高效的刪除重復記錄方法 ( 因為使用了ROWID)
DELETE FROM EMP E
WHERE E.ROWID > (SELECT MIN(X.ROWID)
FROM EMP X
WHERE X.EMP_NO = E.EMP_NO);
12. 盡量多使用COMMIT
只要有可能,在程序中盡量多使用COMMIT, 這樣程序的性能得到提高,需求也會因為COMMIT所釋放的資源而減少:
COMMIT所釋放的資源:
a. 回滾段上用於恢復數據的信息.
b. 被程序語句獲得的鎖
c. redo log buffer 中的空間
d. ORACLE為管理上述3種資源中的內部花費
(譯者按: 在使用COMMIT時必須要注意到事務的完整性,現實中效率和事務完整性往往是魚和熊掌不可得兼)
ORACLE SQL性能優化系列 (四)
13. 計算記錄條數
和一般的觀點相反, count(*) 比count(1)稍快 , 當然如果可以通過索引檢索,對索引列的計數仍舊是最快的. 例如 COUNT(EMPNO)
(譯者按: 在CSDN論壇中,曾經對此有過相當熱烈的討論, 作者的觀點並不十分准確,通過實際的測試,上述三種方法並沒有顯著的性能差別)
14. 用Where子句替換HAVING子句
避免使用HAVING子句, HAVING 只會在檢索出所有記錄之後才對結果集進行過濾. 這個處理需要排序,總計等操作.如果能通過WHERE子句限制記錄的數目,那就能減少這方面的開銷.
例如:
低效:
SELECT REGION,AVG(LOG_SIZE)
FROM LOCATION
GROUP BY REGION
HAVING REGION REGION != ‘SYDNEY’
AND REGION != ‘PERTH’
高效
SELECT REGION,AVG(LOG_SIZE)
FROM LOCATION
WHERE REGION REGION != ‘SYDNEY’
AND REGION != ‘PERTH’
GROUP BY REGION
(譯者按:HAVING 中的條件一般用於對一些集合函數的比較,如COUNT() 等等. 除此而外,一般的條件應該寫在WHERE子句中)
15. 減少對表的查詢
在含有子查詢的SQL語句中,要特別注意減少對表的查詢.
例如:
低效
SELECT TAB_NAME
FROM TABLES
WHERE TAB_NAME = ( SELECT TAB_NAME
FROM TAB_COLUMNS
WHERE VERSION = 604)
AND DB_VER=( SELECT DB_VER
FROM TAB_COLUMNS
WHERE VERSION = 604)
高效
SELECT TAB_NAME
FROM TABLES
WHERE (TAB_NAME,DB_VER)
= ( SELECT TAB_NAME,DB_VER)
FROM TAB_COLUMNS
WHERE VERSION = 604)
Update 多個Column 例子:
低效:
UPDATE EMP
SET EMP_CAT = (SELECT MAX(CATEGORY)FROM EMP_CATEGORIES),
SAL_RANGE = (SELECT MAX(SAL_RANGE) FROMEMP_CATEGORIES)
WHERE EMP_DEPT = 0020;
高效:
UPDATE EMP
SET (EMP_CAT, SAL_RANGE)
= (SELECT MAX(CATEGORY) ,MAX(SAL_RANGE)
FROM EMP_CATEGORIES)
WHERE EMP_DEPT = 0020;
16. 通過內部函數提高SQL效率.
SELECTH.EMPNO,E.ENAME,H.HIST_TYPE,T.TYPE_DESC,COUNT(*)
FROM HISTORY_TYPE T,EMP E,EMP_HISTORY H
WHERE H.EMPNO = E.EMPNO
AND H.HIST_TYPE = T.HIST_TYPE
GROUP BYH.EMPNO,E.ENAME,H.HIST_TYPE,T.TYPE_DESC;
通過調用下面的函數可以提高效率.
FUNCTION LOOKUP_HIST_TYPE(TYP INNUMBER) RETURN VARCHAR2
AS
TDESC VARCHAR2(30);
CURSOR C1 IS
SELECT TYPE_DESC
FROM HISTORY_TYPE
WHERE HIST_TYPE = TYP;
BEGIN
OPEN C1;
FETCH C1 INTO TDESC;
CLOSE C1;
RETURN (NVL(TDESC,’?’));
END;
FUNCTION LOOKUP_EMP(EMP IN NUMBER)RETURN VARCHAR2
AS
ENAME VARCHAR2(30);
CURSOR C1 IS
SELECT ENAME
FROM EMP
WHERE EMPNO=EMP;
BEGIN
OPEN C1;
FETCH C1 INTO ENAME;
CLOSE C1;
RETURN (NVL(ENAME,’?’));
END;
SELECT H.EMPNO,LOOKUP_EMP(H.EMPNO),
H.HIST_TYPE,LOOKUP_HIST_TYPE(H.HIST_TYPE),COUNT(*)
FROM EMP_HISTORY H
GROUP BY H.EMPNO , H.HIST_TYPE;
ORACLE SQL性能優化系列 (六)
20. 用表連接替換EXISTS
通常來說 , 采用表連接的方式比EXISTS更有效率
SELECT ENAME
FROM EMP E
WHERE EXISTS (SELECT ‘X’
FROM DEPT
WHERE DEPT_NO = E.DEPT_NO
AND DEPT_CAT = ‘A’);
(更高效)
SELECT ENAME
FROM DEPT D,EMP E
WHERE E.DEPT_NO = D.DEPT_NO
AND DEPT_CAT = ‘A’ ;
21. 用EXISTS替換DISTINCT
當提交一個包含一對多表信息(比如部門表和雇員表)的查詢時,避免在SELECT子句中使用DISTINCT. 一般可以考慮用EXIST替換
例如:
低效:
SELECT DISTINCT DEPT_NO,DEPT_NAME
FROM DEPT D,EMP E
WHERE D.DEPT_NO = E.DEPT_NO
高效:
SELECT DEPT_NO,DEPT_NAME
FROM DEPT D
WHERE EXISTS ( SELECT ‘X’
FROM EMP E
WHERE E.DEPT_NO = D.DEPT_NO);
EXISTS 使查詢更為迅速,因為RDBMS核心模塊將在子查詢的條件一旦滿足後,立刻返回結果.
22. 識別’低效執行’的SQL語句
用下列SQL工具找出低效SQL:
SELECT EXECUTIONS , DISK_READS,BUFFER_GETS,
ROUND((BUFFER_GETS-DISK_READS)/BUFFER_GETS,2)Hit_radio,
ROUND(DISK_READS/EXECUTIONS,2)Reads_per_run,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS>0
AND BUFFER_GETS > 0
AND(BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.8
ORDER BY 4 DESC;
(譯者按: 雖然目前各種關於SQL優化的圖形化工具層出不窮,但是寫出自己的SQL工具來解決問題始終是一個最好的方法)
23. 使用TKPROF 工具來查詢SQL性能狀態
SQL trace 工具收集正在執行的SQL的性能狀態數據並記錄到一個跟蹤文件中. 這個跟蹤文件提供了許多有用的信息,例如解析次數.執行次數,CPU使用時間等.這些數據將可以用來優化你的系統.
設置SQL TRACE在會話級別: 有效
ALTER SESSION SET SQL_TRACE TRUE
設置SQL TRACE 在整個數據庫有效仿, 你必須將SQL_TRACE參數在init.ora中設為TRUE, USER_DUMP_DEST參數說明了生成跟蹤文件的目錄
ORACLE SQL性能優化系列 (七 )
24. 用EXPLAIN PLAN 分析SQL語句
EXPLAIN PLAN 是一個很好的分析SQL語句的工具,它甚至可以在不執行SQL的情況下分析語句. 通過分析,我們就可以知道ORACLE是怎麼樣連接表,使用什麼方式掃描表(索引掃描或全表掃描)以及使用到的索引名稱.
你需要按照從裡到外,從上到下的次序解讀分析的結果. EXPLAIN PLAN分析的結果是用縮進的格式排列的, 最內部的操作將被最先解讀, 如果兩個操作處於同一層中,帶有最小操作號的將被首先執行.
NESTED LOOP是少數不按照上述規則處理的操作, 正確的執行路徑是檢查對NESTED LOOP提供數據的操作,其中操作號最小的將被最先處理.
譯者按:
通過實踐, 感到還是用SQLPLUS中的SET TRACE 功能比較方便.
舉例:
SQL> list
1 SELECT *
2 FROM dept, emp
3* WHERE emp.deptno = dept.deptno
SQL> set autotrace on exp;/*traceonly 可以不顯示執行結果*/
或者SQL> set autotrace traceonly exp;
SQL> /
14 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 NESTED LOOPS
2 1 TABLE ACCESS (FULL) OF 'EMP'
3 1 TABLE ACCESS (BY INDEX ROWID) OF'DEPT'
4 3 INDEX (UNIQUE SCAN) OF 'PK_DEPT'(UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
2 db block gets
30 consistent gets
0 physical reads
0 redo size
2598 bytes sent via SQL*Net to client
503 bytes received via SQL*Net fromclient
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed
通過以上分析,可以得出實際的執行步驟是:
1. TABLE ACCESS (FULL) OF 'EMP'
2. INDEX (UNIQUE SCAN) OF 'PK_DEPT'(UNIQUE)
3. TABLE ACCESS (BY INDEX ROWID) OF'DEPT'
4. NESTED LOOPS (JOINING 1 AND 3)
ORACLE SQL性能優化系列 (八)
25. 用索引提高效率
索引是表的一個概念部分,用來提高檢索數據的效率. 實際上,ORACLE使用了一個復雜的自平衡B-tree結構. 通常,通過索引查詢數據比全表掃描要快. 當ORACLE找出執行查詢和Update語句的最佳路徑時, ORACLE優化器將使用索引. 同樣在聯結多個表時使用索引也可以提高效率. 另一個使用索引的好處是,它提供了主鍵(primary key)的唯一性驗證.
除了那些LONG或LONG RAW數據類型, 你可以索引幾乎所有的列. 通常, 在大型表中使用索引特別有效. 當然,你也會發現, 在掃描小表時,使用索引同樣能提高效率.
雖然使用索引能得到查詢效率的提高,但是我們也必須注意到它的代價. 索引需要空間來
存儲,也需要定期維護, 每當有記錄在表中增減或索引列被修改時, 索引本身也會被修改. 這意味著每條記錄的INSERT , DELETE , UPDATE將為此多付出4 , 5 次的磁盤I/O . 因為索引需要額外的存儲空間和處理,那些不必要的索引反而會使查詢反應時間變慢.
譯者按:
定期的重構索引是有必要的.
ALTER INDEX <INDEXNAME> REBUILD<TABLESPACENAME>
26. 索引的操作
ORACLE對索引有兩種訪問模式.
索引唯一掃描 ( INDEX UNIQUE SCAN)
大多數情況下, 優化器通過WHERE子句訪問INDEX.
例如:
表LODGING有兩個索引 : 建立在LODGING列上的唯一性索引LODGING_PK和建立在MANAGER列上的非唯一性索引LODGING$MANAGER.
SELECT *
FROM LODGING
WHERE LODGING = ‘ROSE HILL’;
在內部 , 上述SQL將被分成兩步執行, 首先 , LODGING_PK 索引將通過索引唯一掃描的方式被訪問 , 獲得相對應的ROWID, 通過ROWID訪問表的方式執行下一步檢索.
如果被檢索返回的列包括在INDEX列中,ORACLE將不執行第二步的處理(通過ROWID訪問表). 因為檢索數據保存在索引中, 單單訪問索引就可以完全滿足查詢結果.
下面SQL只需要INDEXUNIQUE SCAN 操作.
SELECT LODGING
FROM LODGING
WHERE LODGING = ‘ROSE HILL’;
索引范圍查詢(INDEX RANGE SCAN)
適用於兩種情況:
1. 基於一個范圍的檢索
2. 基於非唯一性索引的檢索
例1:
SELECT LODGING
FROM LODGING
WHERE LODGING LIKE ‘M%’;
WHERE子句條件包括一系列值, ORACLE將通過索引范圍查詢的方式查詢LODGING_PK . 由於索引范圍查詢將返回一組值, 它的效率就要比索引唯一掃描低一些.
例2:
SELECT LODGING
FROM LODGING
WHERE MANAGER = ‘BILL GATES’;
這個SQL的執行分兩步,LODGING$MANAGER的索引范圍查詢(得到所有符合條件記錄的ROWID) 和下一步同過ROWID訪問表得到LODGING列的值. 由於LODGING$MANAGER是一個非唯一性的索引,數據庫不能對它執行索引唯一掃描.
由於SQL返回LODGING列,而它並不存在於LODGING$MANAGER索引中, 所以在索引范圍查詢後會執行一個通過ROWID訪問表的操作.
WHERE子句中, 如果索引列所對應的值的第一個字符由通配符(WILDCARD)開始, 索引將不被采用.
SELECT LODGING
FROM LODGING
WHERE MANAGER LIKE ‘%HANMAN’;
在這種情況下,ORACLE將使用全表掃描.
ORACLE SQL性能優化系列 (九)
27. 基礎表的選擇
基礎表(Driving Table)是指被最先訪問的表(通常以全表掃描的方式被訪問). 根據優化器的不同, SQL語句中基礎表的選擇是不一樣的.
如果你使用的是CBO (COST BASED OPTIMIZER),優化器會檢查SQL語句中的每個表的物理大小,索引的狀態,然後選用花費最低的執行路徑.
如果你用RBO (RULE BASED OPTIMIZER) , 並且所有的連接條件都有索引對應, 在這種情況下, 基礎表就是FROM 子句中列在最後的那個表.
舉例:
SELECT A.NAME , B.MANAGER
FROM WORKERA,
LODGING B
WHERE A.LODGING = B.LODING;
由於LODGING表的LODING列上有一個索引, 而且WORKER表中沒有相比較的索引, WORKER表將被作為查詢中的基礎表.
28. 多個平等的索引
當SQL語句的執行路徑可以使用分布在多個表上的多個索引時, ORACLE會同時使用多個索引並在運行時對它們的記錄進行合並, 檢索出僅對全部索引有效的記錄.
在ORACLE選擇執行路徑時,唯一性索引的等級高於非唯一性索引. 然而這個規則只有
當WHERE子句中索引列和常量比較才有效.如果索引列和其他表的索引類相比較. 這種子句在優化器中的等級是非常低的.
如果不同表中兩個想同等級的索引將被引用, FROM子句中表的順序將決定哪個會被率先使用. FROM子句中最後的表的索引將有最高的優先級.
如果相同表中兩個想同等級的索引將被引用, WHERE子句中最先被引用的索引將有最高的優先級.
舉例:
DEPTNO上有一個非唯一性索引,EMP_CAT也有一個非唯一性索引.
SELECT ENAME,
FROM EMP
WHERE DEPT_NO = 20
AND EMP_CAT = ‘A’;
這裡,DEPTNO索引將被最先檢索,然後同EMP_CAT索引檢索出的記錄進行合並. 執行路徑如下:
TABLE ACCESS BY ROWID ON EMP
AND-EQUAL
INDEX RANGE SCAN ON DEPT_IDX
INDEX RANGE SCAN ON CAT_IDX
29. 等式比較和范圍比較
當WHERE子句中有索引列,ORACLE不能合並它們,ORACLE將用范圍比較.
舉例:
DEPTNO上有一個非唯一性索引,EMP_CAT也有一個非唯一性索引.
SELECT ENAME
FROM EMP
WHERE DEPTNO > 20
AND EMP_CAT = ‘A’;
這裡只有EMP_CAT索引被用到,然後所有的記錄將逐條與DEPTNO條件進行比較. 執行路徑如下:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON CAT_IDX
30. 不明確的索引等級
當ORACLE無法判斷索引的等級高低差別,優化器將只使用一個索引,它就是在WHERE子句中被列在最前面的.
舉例:
DEPTNO上有一個非唯一性索引,EMP_CAT也有一個非唯一性索引.
SELECT ENAME
FROM EMP
WHERE DEPTNO > 20
AND EMP_CAT > ‘A’;
這裡, ORACLE只用到了DEPT_NO索引. 執行路徑如下:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON DEPT_IDX
譯者按:
我們來試一下以下這種情況:
SQL> select index_name, uniquenessfrom user_indexes where table_name = 'EMP';
INDEX_NAME UNIQUENES
---------------------------------------
EMPNO UNIQUE
EMPTYPE NONUNIQUE
SQL> select * from emp where empno>= 2 and emp_type = 'A' ;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPTYPE'(NON-UNIQUE)
雖然EMPNO是唯一性索引,但是由於它所做的是范圍比較, 等級要比非唯一性索引的等式比較低!
ORACLE SQL性能優化系列 (十)
31. 強制索引失效
如果兩個或以上索引具有相同的等級,你可以強制命令ORACLE優化器使用其中的一個(通過它,檢索出的記錄數量少) .
舉例:
SELECT ENAME
FROM EMP
WHERE EMPNO = 7935
AND DEPTNO + 0 = 10 /*DEPTNO上的索引將失效*/
AND EMP_TYPE || ‘’ = ‘A’ /*EMP_TYPE上的索引將失效*/
這是一種相當直接的提高查詢效率的辦法. 但是你必須謹慎考慮這種策略,一般來說,只有在你希望單獨優化幾個SQL時才能采用它.
這裡有一個例子關於何時采用這種策略,
假設在EMP表的EMP_TYPE列上有一個非唯一性的索引而EMP_CLASS上沒有索引.
SELECT ENAME
FROM EMP
WHERE EMP_TYPE = ‘A’
AND EMP_CLASS = ‘X’;
優化器會注意到EMP_TYPE上的索引並使用它. 這是目前唯一的選擇. 如果,一段時間以後, 另一個非唯一性建立在EMP_CLASS上,優化器必須對兩個索引進行選擇,在通常情況下,優化器將使用兩個索引並在他們的結果集合上執行排序及合並. 然而,如果其中一個索引(EMP_TYPE)接近於唯一性而另一個索引(EMP_CLASS)上有幾千個重復的值. 排序及合並就會成為一種不必要的負擔. 在這種情況下,你希望使優化器屏蔽掉EMP_CLASS索引.
用下面的方案就可以解決問題.
SELECT ENAME
FROM EMP
WHERE EMP_TYPE = ‘A’
AND EMP_CLASS||’’ = ‘X’;
32. 避免在索引列上使用計算.
WHERE子句中,如果索引列是函數的一部分.優化器將不使用索引而使用全表掃描.
舉例:
低效:
SELECT …
FROM DEPT
WHERE SAL * 12 > 25000;
高效:
SELECT …
FROM DEPT
WHERE SAL > 25000/12;
譯者按:
這是一個非常實用的規則,請務必牢記
33. 自動選擇索引
如果表中有兩個以上(包括兩個)索引,其中有一個唯一性索引,而其他是非唯一性.
在這種情況下,ORACLE將使用唯一性索引而完全忽略非唯一性索引.
舉例:
SELECT ENAME
FROM EMP
WHERE EMPNO = 2326
AND DEPTNO = 20 ;
這裡,只有EMPNO上的索引是唯一性的,所以EMPNO索引將用來檢索記錄.
TABLE ACCESS BY ROWID ON EMP
INDEX UNIQUE SCAN ON EMP_NO_IDX
34. 避免在索引列上使用NOT
通常, 我們要避免在索引列上使用NOT, NOT會產生在和在索引列上使用函數相同的
影響. 當ORACLE”遇到”NOT,他就會停止使用索引轉而執行全表掃描.
舉例:
低效: (這裡,不使用索引)
SELECT …
FROM DEPT
WHERE DEPT_CODE NOT = 0;
高效: (這裡,使用了索引)
SELECT …
FROM DEPT
WHERE DEPT_CODE > 0;
需要注意的是,在某些時候,ORACLE優化器會自動將NOT轉化成相對應的關系操作符.
NOT > to <=
NOT >= to <
NOT < to >=
NOT <= to >
譯者按:
在這個例子中,作者犯了一些錯誤. 例子中的低效率SQL是不能被執行的.
我做了一些測試:
SQL> select * from emp where NOTempno > 1;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPNO'(UNIQUE)
SQL> select * from emp where empno<= 1;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPNO'(UNIQUE)
兩者的效率完全一樣,也許這符合作者關於” 在某些時候, ORACLE優化器會自動將NOT轉化成相對應的關系操作符” 的觀點.
35. 用>=替代>
如果DEPTNO上有一個索引,
高效:
SELECT *
FROM EMP
WHERE DEPTNO >=4
低效:
SELECT *
FROM EMP
WHERE DEPTNO >3
兩者的區別在於, 前者DBMS將直接跳到第一個DEPT等於4的記錄而後者將首先定位到DEPTNO=3的記錄並且向前掃描到第一個DEPT大於3的記錄.
ORACLE SQL性能優化系列 (十一)
36. 用UNION替換OR (適用於索引列)
通常情況下, 用UNION替換WHERE子句中的OR將會起到較好的效果. 對索引列使用OR將造成全表掃描. 注意, 以上規則只針對多個索引列有效. 如果有column沒有被索引, 查詢效率可能會因為你沒有選擇OR而降低.
在下面的例子中, LOC_ID 和REGION上都建有索引.
高效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10
UNION
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE REGION = “MELBOURNE”
低效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10 OR REGION = “MELBOURNE”
如果你堅持要用OR, 那就需要返回記錄最少的索引列寫在最前面.
注意:
WHERE KEY1 = 10 (返回最少記錄)
OR KEY2 = 20 (返回最多記錄)
ORACLE 內部將以上轉換為
WHERE KEY1 = 10 AND
((NOT KEY1 = 10) AND KEY2 = 20)
譯者按:
下面的測試數據僅供參考: (a = 1003 返回一條記錄 , b = 1 返回1003條記錄)
SQL> select * from unionvsor /*1sttest*/
2 where a = 1003 or b = 1;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 CONCATENATION
2 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
3 2 INDEX (RANGE SCAN) OF 'UB'(NON-UNIQUE)
4 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
5 4 INDEX (RANGE SCAN) OF 'UA'(NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
144 consistent gets
0 physical reads
0 redo size
63749 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net fromclient
68 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1003 rows processed
SQL> select * from unionvsor /*2ndtest*/
2 where b = 1 or a = 1003 ;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 CONCATENATION
2 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
3 2 INDEX (RANGE SCAN) OF 'UA'(NON-UNIQUE)
4 1 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
5 4 INDEX (RANGE SCAN) OF 'UB'(NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
143 consistent gets
0 physical reads
0 redo size
63749 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net fromclient
68 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1003 rows processed
SQL> select * from unionvsor /*3rdtest*/
2 where a = 1003
3 union
4 select * from unionvsor
5 where b = 1;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (UNIQUE)
2 1 UNION-ALL
3 2 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
4 3 INDEX (RANGE SCAN) OF 'UA'(NON-UNIQUE)
5 2 TABLE ACCESS (BY INDEX ROWID) OF'UNIONVSOR'
6 5 INDEX (RANGE SCAN) OF 'UB'(NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
10 consistent gets
0 physical reads
0 redo size
63735 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net fromclient
68 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
1003 rows processed
用UNION的效果可以從consistentgets和 SQL*NET的數據交換量的減少看出
37. 用IN來替換OR
下面的查詢可以被更有效率的語句替換:
低效:
SELECT….
FROM LOCATION
WHERE LOC_ID = 10
OR LOC_ID = 20
OR LOC_ID = 30
高效
SELECT…
FROM LOCATION
WHERE LOC_IN IN (10,20,30);
譯者按:
這是一條簡單易記的規則,但是實際的執行效果還須檢驗,在ORACLE8i下,兩者的執行路徑似乎是相同的.
38. 避免在索引列上使用IS NULL和IS NOT NULL
避免在索引中使用任何可以為空的列,ORACLE將無法使用該索引.對於單列索引,如果列包含空值,索引中將不存在此記錄. 對於復合索引,如果每個列都為空,索引中同樣不存在此記錄. 如果至少有一個列不為空,則記錄存在於索引中.
舉例:
如果唯一性索引建立在表的A列和B列上, 並且表中存在一條記錄的A,B值為(123,null) , ORACLE將不接受下一條具有相同A,B值(123,null)的記錄(插入). 然而如果
所有的索引列都為空,ORACLE將認為整個鍵值為空而空不等於空. 因此你可以插入1000
條具有相同鍵值的記錄,當然它們都是空!
因為空值不存在於索引列中,所以WHERE子句中對索引列進行空值比較將使ORACLE停用該索引.
舉例:
低效: (索引失效)
SELECT …
FROM DEPARTMENT
WHERE DEPT_CODE IS NOT NULL;
高效: (索引有效)
SELECT …
FROM DEPARTMENT
WHERE DEPT_CODE >=0;
ORACLE SQL性能優化系列 (十二)
39. 總是使用索引的第一個列
如果索引是建立在多個列上, 只有在它的第一個列(leading column)被where子句引用時,優化器才會選擇使用該索引.
譯者按:
這也是一條簡單而重要的規則. 見以下實例.
SQL> create table multiindexusage (inda number , indb number , descr varchar2(10));
Table created.
SQL> create index multindex on multiindexusage(inda,indb);
Index created.
SQL> set autotrace traceonly
SQL> select * from multiindexusagewhere inda = 1;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'MULTIINDEXUSAGE'
2 1 INDEX (RANGE SCAN) OF 'MULTINDEX'(NON-UNIQUE)
SQL> select * from multiindexusagewhere indb = 1;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (FULL) OF'MULTIINDEXUSAGE'
很明顯, 當僅引用索引的第二個列時,優化器使用了全表掃描而忽略了索引
40. ORACLE內部操作
當執行查詢時,ORACLE采用了內部的操作. 下表顯示了幾種重要的內部操作.
ORACLE Clause
內部操作
ORDER BY
SORT ORDER BY
UNION
UNION-ALL
MINUS
MINUS
INTERSECT
INTERSECT
DISTINCT,MINUS,INTERSECT,UNION
SORT UNIQUE
MIN,MAX,COUNT
SORT AGGREGATE
GROUP BY
SORT GROUP BY
ROWNUM
COUNT or COUNT STOPKEY
Queries involving Joins
SORT JOIN,MERGE JOIN,NESTED LOOPS
CONNECT BY
CONNECT BY
41. 用UNION-ALL 替換UNION ( 如果有可能的話)
當SQL語句需要UNION兩個查詢結果集合時,這兩個結果集合會以UNION-ALL的方式被合並, 然後在輸出最終結果前進行排序.
如果用UNION ALL替代UNION, 這樣排序就不是必要了. 效率就會因此得到提高.
舉例:
低效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
UNION
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
高效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
UNION ALL
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = ’31-DEC-95’
譯者按:
需要注意的是,UNION ALL 將重復輸出兩個結果集合中相同記錄. 因此各位還是
要從業務需求分析使用UNION ALL的可行性.
UNION 將對結果集合排序,這個操作會使用到SORT_AREA_SIZE這塊內存. 對於這
塊內存的優化也是相當重要的. 下面的SQL可以用來查詢排序的消耗量
Select substr(name,1,25) "SortArea Name",
substr(value,1,15) "Value"
from v$sysstat
where name like 'sort%'
42. 使用提示(Hints)
對於表的訪問,可以使用兩種Hints.
FULL 和 ROWID
FULL hint 告訴ORACLE使用全表掃描的方式訪問指定表.
例如:
SELECT /*+ FULL(EMP) */ *
FROM EMP
WHERE EMPNO = 7893;
ROWID hint 告訴ORACLE使用TABLE ACCESS BY ROWID的操作訪問表.
通常, 你需要采用TABLEACCESS BY ROWID的方式特別是當訪問大表的時候, 使用這種方式, 你需要知道ROIWD的值或者使用索引.
如果一個大表沒有被設定為緩存(CACHED)表而你希望它的數據在查詢結束是仍然停留
在SGA中,你就可以使用CACHE hint 來告訴優化器把數據保留在SGA中. 通常CACHE hint 和 FULL hint 一起使用.
例如:
SELECT /*+ FULL(WORKER) CACHE(WORKER)*/*
FROM WORK;
索引hint 告訴ORACLE使用基於索引的掃描方式. 你不必說明具體的索引名稱
例如:
SELECT /*+ INDEX(LODGING) */ LODGING
FROM LODGING
WHERE MANAGER = ‘BILL GATES’;
在不使用hint的情況下, 以上的查詢應該也會使用索引,然而,如果該索引的重復值過多而你的優化器是CBO, 優化器就可能忽略索引. 在這種情況下, 你可以用INDEX hint強制ORACLE使用該索引.
ORACLE hints 還包括ALL_ROWS, FIRST_ROWS, RULE,USE_NL, USE_MERGE, USE_HASH 等等.
譯者按:
使用hint , 表示我們對ORACLE優化器缺省的執行路徑不滿意,需要手工修改.
這是一個很有技巧性的工作. 我建議只針對特定的,少數的SQL進行hint的優化.
對ORACLE的優化器還是要有信心(特別是CBO)
ORACLE SQL性能優化系列 (十三)
43. 用WHERE替代ORDER BY
ORDER BY 子句只在兩種嚴格的條件下使用索引.
ORDER BY中所有的列必須包含在相同的索引中並保持在索引中的排列順序.
ORDER BY中所有的列必須定義為非空.
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能並列.
例如:
表DEPT包含以下列:
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
非唯一性的索引(DEPT_TYPE)
低效: (索引不被使用)
SELECT DEPT_CODE
FROM DEPT
ORDER BY DEPT_TYPE
EXPLAIN PLAN:
SORT ORDER BY
TABLE ACCESS FULL
高效: (使用索引)
SELECT DEPT_CODE
FROM DEPT
WHERE DEPT_TYPE > 0
EXPLAIN PLAN:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON DEPT_IDX
譯者按:
ORDER BY 也能使用索引! 這的確是個容易被忽視的知識點. 我們來驗證一下:
SQL> select * from emp order byempno;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF'EMP'
2 1 INDEX (FULL SCAN) OF 'EMPNO'(UNIQUE)
44. 避免改變索引列的類型.
當比較不同數據類型的數據時, ORACLE自動對列進行簡單的類型轉換.
假設 EMPNO是一個數值類型的索引列.
SELECT …
FROM EMP
WHERE EMPNO = ‘123’
實際上,經過ORACLE類型轉換, 語句轉化為:
SELECT …
FROM EMP
WHERE EMPNO = TO_NUMBER(‘123’)
幸運的是,類型轉換沒有發生在索引列上,索引的用途沒有被改變.
現在,假設EMP_TYPE是一個字符類型的索引列.
SELECT …
FROM EMP
WHERE EMP_TYPE = 123
這個語句被ORACLE轉換為:
SELECT …
FROM EMP
WHERE TO_NUMBER(EMP_TYPE)=123
因為內部發生的類型轉換, 這個索引將不會被用到!
譯者按:
為了避免ORACLE對你的SQL進行隱式的類型轉換, 最好把類型轉換用顯式表現出來. 注意當字符和數值比較時, ORACLE會優先轉換數值類型到字符類型.
45. 需要當心的WHERE子句
某些SELECT 語句中的WHERE子句不使用索引. 這裡有一些例子.
在下面的例子裡, ‘!=’ 將不使用索引. 記住, 索引只能告訴你什麼存在於表中, 而不能告訴你什麼不存在於表中.
不使用索引:
SELECT ACCOUNT_NAME
FROM TRANSACTION
WHERE AMOUNT !=0;
使用索引:
SELECT ACCOUNT_NAME
FROM TRANSACTION
WHERE AMOUNT >0;
下面的例子中, ‘||’是字符連接函數. 就象其他函數那樣, 停用了索引.
不使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME||ACCOUNT_TYPE=’AMEXA’;
使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME = ‘AMEX’
AND ACCOUNT_TYPE=’ A’;
下面的例子中, ‘+’是數學函數. 就象其他數學函數那樣, 停用了索引.
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE AMOUNT + 3000 >5000;
使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE AMOUNT > 2000 ;
下面的例子中,相同的索引列不能互相比較,這將會啟用全表掃描.
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME =NVL(:ACC_NAME,ACCOUNT_NAME);
使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME LIKE NVL(:ACC_NAME,’%’);
譯者按:
如果一定要對使用函數的列啟用索引, ORACLE新的功能: 基於函數的索引(Function-Based Index) 也許是一個較好的方案.
CREATE INDEX EMP_I ON EMP(UPPER(ename)); /*建立基於函數的索引*/
SELECT * FROM emp WHERE UPPER(ename) = ‘BLACKSNAIL’; /*將使用索引*/
ORACLE SQL性能優化系列 (十四) 完結篇
46. 連接多個掃描
如果你對一個列和一組有限的值進行比較, 優化器可能執行多次掃描並對結果進行合並連接.
舉例:
SELECT *
FROM LODGING
WHERE MANAGER IN (‘BILL GATES’,’KENMULLER’);
優化器可能將它轉換成以下形式
SELECT *
FROM LODGING
WHERE MANAGER = ‘BILL GATES’
OR MANAGER = ’KEN MULLER’;
當選擇執行路徑時, 優化器可能對每個條件采用LODGING$MANAGER上的索引范圍掃描. 返回的ROWID用來訪問LODGING表的記錄 (通過TABLE ACCESS BY ROWID 的方式). 最後兩組記錄以連接(CONCATENATION)的形式被組合成一個單一的集合.
Explain Plan :
SELECT STATEMENT Optimizer=CHOOSE
CONCATENATION
TABLE ACCESS (BY INDEX ROWID) OFLODGING
INDEX (RANGE SCAN ) OF LODGING$MANAGER(NON-UNIQUE)
TABLE ACCESS (BY INDEX ROWID) OFLODGING
INDEX (RANGE SCAN ) OF LODGING$MANAGER(NON-UNIQUE)
譯者按:
本節和第37節似乎有矛盾之處.
47. CBO下使用更具選擇性的索引
基於成本的優化器(CBO, Cost-Based Optimizer)對索引的選擇性進行判斷來決定索引的使用是否能提高效率.
如果索引有很高的選擇性, 那就是說對於每個不重復的索引鍵值,只對應數量很少的記錄.
比如, 表中共有100條記錄而其中有80個不重復的索引鍵值. 這個索引的選擇性就是80/100 = 0.8 . 選擇性越高,通過索引鍵值檢索出的記錄就越少.
如果索引的選擇性很低, 檢索數據就需要大量的索引范圍查詢操作和ROWID 訪問表的
操作. 也許會比全表掃描的效率更低.
譯者按:
下列經驗請參閱:
a. 如果檢索數據量超過30%的表中記錄數.使用索引將沒有顯著的效率提高.
b. 在特定情況下, 使用索引也許會比全表掃描慢, 但這是同一個數量級上的
區別. 而通常情況下,使用索引比全表掃描要塊幾倍乃至幾千倍!
48. 避免使用耗費資源的操作
帶有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL語句會啟動SQL引擎
執行耗費資源的排序(SORT)功能.DISTINCT需要一次排序操作, 而其他的至少需要執行兩次排序.
例如,一個UNION查詢,其中每個查詢都帶有GROUP BY子句,GROUP BY會觸發嵌入排序(NESTED SORT) ; 這樣, 每個查詢需要執行一次排序, 然後在執行UNION時, 又一個唯一排序(SORTUNIQUE)操作被執行而且它只能在前面的嵌入排序結束後才能開始執行. 嵌入的排序的深度會大大影響查詢的效率.
通常, 帶有UNION,MINUS , INTERSECT的SQL語句都可以用其他方式重寫.
譯者按:
如果你的數據庫的SORT_AREA_SIZE調配得好, 使用UNION , MINUS, INTERSECT也是可以考慮的, 畢竟它們的可讀性很強
49. 優化GROUP BY
提高GROUP BY 語句的效率, 可以通過將不需要的記錄在GROUP BY 之前過濾掉.下面兩個查詢返回相同結果但第二個明顯就快了許多.
低效:
SELECT JOB , AVG(SAL)
FROM EMP
GROUP JOB
HAVING JOB = ‘PRESIDENT’
OR JOB = ‘MANAGER’
高效:
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB = ‘PRESIDENT’
OR JOB = ‘MANAGER’
GROUP JOB
譯者按:
本節和14節相同. 可略過.
50. 使用日期
當使用日期是,需要注意如果有超過5位小數加到日期上, 這個日期會進到下一天!
例如:
1.
SELECT TO_DATE(‘01-JAN-93’+.99999)
FROM DUAL;
Returns:
’01-JAN-93 23:59:59’
2.
SELECT TO_DATE(‘01-JAN-93’+.999999)
FROM DUAL;
Returns:
’02-JAN-93 00:00:00’
譯者按:
雖然本節和SQL性能優化沒有關系, 但是作者的功力可見一斑
51. 使用顯式的游標(CURSORs)
使用隱式的游標,將會執行兩次操作. 第一次檢索記錄, 第二次檢查TOO MANY ROWS 這個exception . 而顯式游標不執行第二次操作.
52. 優化EXPORT和IMPORT
使用較大的BUFFER(比如10MB, 10,240,000)可以提高EXPORT和IMPORT的速度.
ORACLE將盡可能地獲取你所指定的內存大小,即使在內存不滿足,也不會報錯.這個值至少要和表中最大的列相當,否則列值會被截斷.
譯者按:
可以肯定的是, 增加BUFFER會大大提高EXPORT , IMPORT的效率. (曾經碰到過一個CASE, 增加BUFFER後,IMPORT/EXPORT快了10倍!)
作者可能犯了一個錯誤: “這個值至少要和表中最大的列相當,否則列值會被截斷. “
其中最大的列也許是指最大的記錄大小.
關於EXPORT/IMPORT的優化,CSDN論壇中有一些總結性的貼子,比如關於BUFFER參數,COMMIT參數等等, 詳情請查.
53. 分離表和索引
總是將你的表和索引建立在不同的表空間內(TABLESPACES). 決不要將不屬於ORACLE內部系統的對象存放到SYSTEM表空間裡. 同時,確保數據表空間和索引表空間置於不同的硬盤上.
譯者按:
“同時,確保數據表空間和索引表空間置與不同的硬盤上.”可能改為如下更為准確 “同時,確保數據表空間和索引表空間置與不同的硬盤控制卡控制的硬盤上.”
列出數據庫裡所有的表名
select table_name from user_tables; --當前用戶的表
select table_name from all_tables; --所有用戶的表
select table_name from dba_tables; --包括系統表
列出表裡的所有的列
desc table_name
綜合評價:★★
下面的例子會制作 "persons" 表的備份復件:
select * into persons_backup from persons
in 子句可用於向另一個數據庫中拷貝表:
select * into persons in 'backup.mdb' from persons
事務:作為一個邏輯單元執行的一系列操作,一個邏輯工作單元必須有四個屬性,稱為 acid(原子性、一致性、隔離性和持久性)屬性。
原子性:事務必須是原子工作單元;對於其數據修改,要麼全都執行,要麼全都不執行。
一致性:事務在完成時,必須使所有的數據都保持一致狀態。在相關數據庫中,所有規則都必須應用於事務的修改,以保持所有數據的完整性。事務結束時,所有的內部數據結構(如 b 樹索引或雙向鏈表)都必須是正確的。
隔離性:由並發事務所作的修改必須與任何其它並發事務所作的修改隔離。事務查看數據時所處的狀態,要麼是另一並發事務修改它之前的狀態,要麼是另一事務修改它之後的狀態,事務不會查看中間狀態的數據。這稱為可串行性,因為它能夠重新裝載起始數據,並且重播一系列事務,以使數據結束時的狀態與原始事務執行的狀態相同。
持久性:事務完成之後,它對於系統的影響是永久性的。該修改即使出現系統故障也將一直保持。
共享鎖:如果事務t對數據a加上共享鎖後,則其他事務只能對a再加共享鎖,不能加排他鎖,直到已釋放所有共享鎖。獲准共享鎖的事務只能讀數據,不能修改數據。
排他鎖:如果事務t對數據a加上排他鎖後,則其他事務不能再對a加任任何類型的鎖,直到在事務的末尾將資源上的鎖釋放為止。獲准排他鎖的事務既能讀數據,又能修改數據。
兩段鎖協議:階段1:加鎖階段階段2:解鎖階段
觸發器: 當滿足觸發器條件,則系統自動執行觸發器的觸發體。
觸發時間:有before,after.觸發事件:有insert,update,delete三種。觸發類型:有行觸發、語句觸發
觸發器的作用:觸發器是一中特殊的存儲過程,主要是通過事件來觸發而被執行的。它可以強化約束,來維護數據的完整性和一致性,可以跟蹤數據庫內的操作從而不允許未經許可的更新和變化。可以聯級運算。如,某表上的觸發器上包含對另一個表的數據操作,而該操作又會導致該表觸發器被觸發。
事前觸發器運行於觸發事件發生之前,而事後觸發器運行於觸發事件發生之後。通常事前觸發器可以獲取事件之前和新的字段值。
語句級觸發器可以在語句執行前或後執行,而行級觸發在觸發器所影響的每一行觸發一次。
綜合評價:★★★
視圖是一種虛擬的表,具有和物理表相同的功能。可以對視圖進行增,改,查,操作,視圖通常是有一個表或者多個表的行或列的子集。對視圖的修改不影響基本表。它使得我們獲取數據更容易,相比多表查詢。
游標:一個游標(cursor)可以被看作指向結果集(a set of rows)中一行的指針(pointer)。游標每個時間點只能指向一行,但是可以根據需要指向結果集中其他的行。
例如:SELECT * FROM employees WHERE sex='M'會返回所有性別為男的雇員,在初始的時候,游標被放置在結果集中第一行的前面。使游標指向第一行,要執行FETCH。當游標指向結果集中一行的時候,可以對這行數據進行加工處理,要想得到下一行數據,要繼續執行FETCH。FETCH操作可以重復執行,直到完成結果集中的所有行
在存儲過程中使用游標:
聲明游標、打開游標、根據需要一次一行,講游標指向的數據取到本地變量(local variables)中、結束時關閉游標。
顯式游標:當查詢返回結果超過一行時,就需要一個顯式游標,此時用戶不能使用select into語句。PL/SQL管理隱式游標,當查詢開始時隱式游標打開,查詢結束時隱式游標自動關閉。顯式游標在PL/SQL塊的聲明部分聲明,在執行部分 或異常處理部分打開,取出數據,關閉。
使用游標:我們所說的游標通常是指 顯式游標
CURSOR cursor_name IS select_statement;
在PL/SQL中游標名是一個未聲明變量,不能給游標名賦值或用於表達式中。例:
DELCARE
CURSOR C_EMP IS SELECT empno,ename,salary
FROM emp
WHERE salary>2000
ORDER BY ename;
........
BEGIN
打開關閉游標:使用游標中的值之前應該首先打開游標初始化查詢處理。
OPEN cursor_name; CLOSE cursor_name
從游標提取數據:從游標得到一行數據使用FETCH命令。每一次提取數據後,游標都指向結果集的下一行。語法如下:FETCHcursor_name INTO variable [, variable...]
對於SELECT定義的游標的每一列,FETCH變量列表都應該有一個變量與之相對應,變量的類型也要相同。返回結果集不止一條就要使用循環。例:
SET SERVERIUTPUT ON
DECLARE
v_ename EMP.ENAME%TYPE;
v_salary EMP.SALARY%TYPE;
CURSOR c_emp IS SELECT ename,salary FROM emp;
BEGIN
OPEN c_emp;
LOOP
FETCH c_emp INTO v_ename,v_salary;
EXIT WHEN c_emp%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(/'Salary of Employee/'|| v_ename ||/'is/'|| v_salary);
END LOOP;
CLOSE c_emp;
END;
記錄變量:定義一個記錄變量使用TYPE命令和%ROWTYPE。
記錄變量用於從游標中提取數據行,當游標選擇很多列的時候,那麼使用記錄比為每列聲明一個變量要方便得多。
關 鍵 詞:當在表上使用%ROWTYPE並將從游標中取出的值放入記錄中時,如果要選擇表中所有列,那麼在SELECT子句中使用*比將所有列名列出來要得多。例:
SET SERVERIUTPUT ON
DECLARE
R_emp EMP%ROWTYPE;
CURSOR c_emp IS SELECT * FROM emp;
BEGIN
OPEN c_emp;
LOOP
FETCH c_emp INTO r_emp;
EXIT WHEN c_emp%NOTFOUND;
DBMS_OUT.PUT.PUT_LINE(/'Salary of Employee/'||r_emp.ename||/'is/'|| r_emp.salary);
END LOOP;
CLOSE c_emp;
END;
%ROWTYPE也可以用游標名來定義,這樣的話就必須要首先聲明游標:
SET SERVERIUTPUT ON
DECLARE
CURSOR c_emp IS SELECT ename,salary FROM emp;
R_emp c_emp%ROWTYPE;
BEGIN
OPEN c_emp;
LOOP
FETCH c_emp INTO r_emp;
EXIT WHEN c_emp%NOTFOUND;
DBMS_OUT.PUT.PUT_LINE(/'Salary of Employee/'
||r_emp.ename||/'is/'|| r_emp.salary);
END LOOP;
CLOSE c_emp;
END;
帶參數的游標:與存儲過程和函數相似,可以將參數傳遞給游標並在查詢中使用。語法如下:
CURSOR cursor_name[(parameter[,parameter],...)] IS select_statement;
定義參數的:
Parameter_name [IN] data_type[{:=|DEFAULT} value]
游標只能接受傳遞的值,不能返回值。參數只定義數據類型,沒有大小。另外可以給參數設定一個缺省值,當沒有參數值傳遞給游標時,就使用缺省值。
打開游標時給參數賦值:
OPEN cursor_name [value [, value]....];
參數值可以是文字或變量。例:
DECALRE
CURSOR c_dept IS SELECT * FROM dept ORDER BY deptno;
CURSOR c_emp (p_dept VARACHAR2) IS
SELECT ename,salary
FROM emp
WHERE deptno=p_dept
ORDER BY ename
r_dept DEPT%ROWTYPE;
v_ename EMP.ENAME%TYPE;
v_salary EMP.SALARY%TYPE;
v_tot_salary EMP.SALARY%TYPE;
BEGIN
OPEN c_dept;
LOOP
FETCH c_dept INTO r_dept;
EXIT WHEN c_dept%NOTFOUND;
DBMS_OUTPUT.PUT_LINE
(/'Department:/'|| r_dept.deptno||/'-/'||r_dept.dname);
v_tot_salary:=0;
OPEN c_emp(r_dept.deptno);
LOOP
FETCH c_emp INTO v_ename,v_salary;
EXIT WHEN c_emp%NOTFOUND;
DBMS_OUTPUT.PUT_LINE
(/'Name:/'|| v_ename||/' salary:/'||v_salary);
v_tot_salary:=v_tot_salary+v_salary;
END LOOP;
CLOSE c_emp;
DBMS_OUTPUT.PUT_LINE
(/'Toltal Salary for dept:/'|| v_tot_salary);
END LOOP;
CLOSE c_dept;
END;
游標FOR循環
在大多數時候我們在設計程序的時候都遵循下面的步驟:
1、打開游標。
2、開始循環。
3、從游標中取值。
4、那一行被返回。
5、處理。
6、關閉循環。
7、關閉游標。
可以簡單的把這一類代碼稱為游標用於循環。但還有一種循環與這種類型不相同,這就是FOR循環,用於FOR循環的游標按照正常的聲明方式聲明,它的優點在於不需要顯式的打開、關閉、取數據,測試數據的存在、定義存放數據的變量等等。游標FOR循環的語法如下:
FOR record_name IN
(corsor_name[(parameter[,parameter]...)]
| (query_difinition)
LOOP
statements
END LOOP;
用for循環重寫上面的例子:
DECALRE
CURSOR c_dept IS SELECT deptno,dname FROM dept ORDER BY deptno;
CURSOR c_emp (p_dept VARACHAR2) IS
SELECT ename,salary
FROM emp
WHERE deptno=p_dept
ORDER BY ename
v_tot_salary EMP.SALARY%TYPE;
BEGIN
FOR r_dept IN c_dept LOOP
DBMS_OUTPUT.PUT_LINE
(/'Department:/'|| r_dept.deptno||/'-/'||r_dept.dname);
v_tot_salary:=0;
FOR r_emp IN c_emp(r_dept.deptno) LOOP
DBMS_OUTPUT.PUT_LINE
(/'Name:/' || v_ename || /'salary:/' || v_salary);
v_tot_salary:=v_tot_salary+v_salary;
END LOOP;
DBMS_OUTPUT.PUT_LINE
(/'Toltal Salary for dept:/'|| v_tot_salary);
END LOOP;
END;
在游標FOR循環中使用查詢
在游標FOR循環中可以定義查詢,由於沒有顯式聲明所以游標沒有名字,記錄名通過游標查詢來定義。
DECALRE
v_tot_salary EMP.SALARY%TYPE;
BEGIN
FOR r_dept IN (SELECT deptno,dname FROM dept ORDER BY deptno) LOOP
DBMS_OUTPUT.PUT_LINE(/'Department:/'|| r_dept.deptno||/'-/'||r_dept.dname);
v_tot_salary:=0;
FOR r_emp IN (SELECT ename,salary
FROM emp
WHERE deptno=p_dept
ORDER BY ename) LOOP
DBMS_OUTPUT.PUT_LINE(/'Name:/'|| v_ename||/' salary:/'||v_salary);
v_tot_salary:=v_tot_salary+v_salary;
END LOOP;
DBMS_OUTPUT.PUT_LINE(/'Toltal Salary for dept:/'|| v_tot_salary);
END LOOP;
END;
游標中的子查詢
CURSOR C1 IS SELECT * FROM emp
WHERE deptno NOT IN (SELECT deptno
FROM dept
WHERE dname!=/'ACCOUNTING/');
游標中的更新和刪除(沒學)
在PL/SQL中依然可以使用UPDATE和DELETE語句更新或刪除數據行。顯式游標只有在需要獲得多行數據的情況下使用。PL/SQL提供了僅僅使用游標就可以執行刪除或更新記錄的方法。
UPDATE或DELETE語句中的WHERECURRENT OF子串專門處理要執行UPDATE或DELETE操作的表中取出的最近的數據。要使用這個方法,在聲明游標時必須使用FOR UPDATE子串,當對話使用FOR UPDATE子串打開一個游標時,所有返回集中的數據行都將處於行級(ROW-LEVEL)獨占式鎖定,其他對象只能查詢這些數據行,不能進行 UPDATE、DELETE或SELECT...FOR UPDATE操作。
語法:
FOR UPDATE [OF [schema.]table.column[,[schema.]table.column]..
[nowait]
在多表查詢中,使用OF子句來鎖定特定的表,如果忽略了OF子句,那麼所有表中選擇的數據行都將被鎖定。如果這些數據行已經被其他會話鎖定,那麼正常情況下ORACLE將等待,直到數據行解鎖。
在UPDATE和DELETE中使用WHERECURRENT OF子串的語法如下:
WHERE{CURRENT OF cursor_name|search_condition}
DELCARE
CURSOR c1 IS SELECT empno,salary
FROM emp
WHERE comm IS NULL
FOR UPDATE OF comm;
v_comm NUMBER(10,2);
BEGIN
FOR r1 IN c1 LOOP
IF r1.salary<500 THEN
v_comm:=r1.salary*0.25;
ELSEIF r1.salary<1000 THEN
v_comm:=r1.salary*0.20;
ELSEIF r1.salary<3000 THEN
v_comm:=r1.salary*0.15;
ELSE
v_comm:=r1.salary*0.12;
END IF;
UPDATE emp;
SET comm=v_comm
WHERE CURRENT OF c1l;
END LOOP;
END
綜合評價:★★★★
存儲過程:一組為了完成特定功能的SQL語句集,經編譯後存儲在數據庫中。
存儲過程的創建需要CREATE PROCEDURE 系統權限,如果需要被其他用戶Schema使用需要CREATE ANY PROCEDURE 權限。存儲過程的執行需要 EXECUTE權限或者 EXECUTE ANY PROCEDURE 權限。
單獨賦予權限:grant execute on MY_PROCEDURE to Jelly;
調用存儲過程: executeMY_PROCEDURE( 'ONE PARAMETER');
存儲過程(PROCEDURE)和函數(FUNCTION)的區別:
A: 函數有限制只能返回一個標量,而存儲過程可以返回多個;
B: 函數可以嵌入到SQL語句中執行. 而存儲過程不行。存儲過程執行必須調用EXECUTE
包(PACKAGE)是function,procedure,variables 和SQL 語句的組合。package允許多個procedure使用同一個變量和游標。
存儲過程的特點:
1.存儲過程運行的速度比較快。
2. 可保證數據的安全性和完整性。
3.可以降低網絡的通信量。
4:存儲過程可以接受參數、輸出參數、返回單個或多個結果集以及返回值。
5:存儲過程可以包含程序流、邏輯以及對數據庫的查詢。
CREATE [ OR REPLACE ] PROCEDURE [ schema.]procedure
[(argument [IN | OUT | IN OUT ] [NO COPY] datatype
[, argument [IN | OUT | IN OUT ] [NO COPY] datatype]...
)]
[ authid { current_user | definer }]
{ is | as } { pl/sql_subprogram_body |
language { java name 'String' | c [ name, name] library lib_name
}]
Sql 代碼:
CREATE PROCEDURE sam.credit (acc_no IN NUMBER, amount IN NUMBER) AS
BEGIN
UPDATE accounts
SET balance = balance + amount
WHERE account_id = acc_no;
END;
IN, OUT, IN OUT用來修飾參數。
IN 表示這個變量必須被調用者賦值然後傳入到PROCEDURE進行處理。
OUT 表示PRCEDURE 通過這個變量將值傳回給調用者。
IN OUT 則是這兩種的組合。
authid代表兩種權限:
定義者權限(difiner right 默認),執行者權限(invoker right)。
定義者權限說明這個procedure中涉及的表、視圖等對象所需要的權限只要定義者擁有權限的話就可以訪問。
執行者權限則需要調用這個 procedure的用戶擁有相關表和對象的權限。
1. 基本結構
CREATE OR REPLACE PROCEDURE 存儲過程名字
(
參數1 IN NUMBER,
參數2 IN NUMBER
) AS
變量1 INTEGER :=0;
變量2 DATE;
BEGIN
END 存儲過程名字
2. SELECT INTO STATEMENT
將select查詢的結果存入到變量中,可以同時將多個列存儲多個變量中,必須有一條記錄,否則拋出異常(如果沒有記錄拋出NO_DATA_FOUND)
例子:
BEGIN
SELECT col1,col2 into 變量1,變量2 FROM typestruct where xxx;
EXCEPTION
WHEN NO_DATA_FOUND THEN
xxxx;
WHEN OTHERS THEN
xxxx;
END;
...
3. IF 判斷
IF V_TEST=1 THEN
BEGIN
do something
END;
END IF;
4. while 循環
WHILE V_TEST=1 LOOP
BEGIN
XXXX
END;
END LOOP;
5. 變量賦值
V_TEST := 123;
6. 用for in 使用cursor
...
IS
CURSOR cur IS SELECT * FROM xxx;
BEGIN
FOR cur_result in cur LOOP
BEGIN
V_SUM :=cur_result.列名1+cur_result.列名2
END;
END LOOP;
END;
7. 帶參數的cursor
CURSOR C_USER(C_ID NUMBER) IS SELECT NAME FROM USER WHERE TYPEID=C_ID;
OPEN C_USER(變量值);
LOOP
FETCH C_USER INTO V_NAME;
EXIT FETCH C_USER%NOTFOUND;
do something
END LOOP;
CLOSE C_USER;
8. 用pl/sql developer debug
連接數據庫後建立一個Test WINDOW
在窗口輸入調用SP的代碼,F9開始debug,CTRL+N單步調試
9. Pl/Sql中執行存儲過程
在sql*plus中:
declare
--必要的變量聲明,視你的過程而定
begin
execute yourprocudure(parameter1,parameter2,...);
end
/
在SQL/PLUS中調用存儲過程,顯示結果:
SQL>set serveoutput on --打開輸出
SQL>var info1 number; --輸出1
SQL>var info2 number; --輸出2
SQL>declare
var1 varchar2(20); --輸入1
var2 varchar2(20); --輸入2
var3 varchar2(20); --輸入2
BEGIN
pro(var1,var2,var3,:info1,:info2);
END;
/
SQL>print info1;
SQL>print info2;
注:在EXECUTE IMMEDIATE STR語句是SQLPLUS中動態執行語句,它在執行中會自動提交,類似於DP中FORMS_DDL語句,在此語句中STR是不能換行的,只能通過連接字符"||",或者在換行時加上"-"連接字符。
綁定變量是指在SQL語句中使用變量,改變變量的值來改變SQL語句的執行結果。
優點:使用綁定變量,可以減少SQL語句的解析,能減少數據庫引擎消耗在SQL語句解析上的資源。提高了編程效率和可靠性。減少訪問數據庫的次數, 就能實際上減少oracle的工作量。
缺點:經常需要使用動態SQL的寫法,由於參數的不同,可能SQL的執行效率不同;綁定變量是相對文本變量來講的,所謂文本變量是指在SQL直接書寫查詢條件,這樣的SQL在不同條件下需要反復解析,綁定變量是指使用變量來代替直接書寫條件,查詢bind value在運行時傳遞,然後綁定執行。優點是減少硬解析,降低cpu的爭用,節省shared_pool缺點是不能使用histogram,SQL優化比較困難
綜合評價:★★★
select *from user_indexes 查詢現有的索引
select *from user_ind_columns 可獲知索引建立在那些字段上
1、 什麼是索引?、
一種用於提升查詢效率的數據庫對象;通過快速定位數據的方法,減少磁盤I/O操作;索引信息與表獨立存放;Oracle數據庫自動使用和維護索引。
2、 索引分類?
唯一索引和非唯一索引
3、 創建索引的兩種方式?
自動創建,在定義主鍵或唯一鍵約束是系統會自動在相應的字段上創建唯一性索引。
手動創建,用戶可以在其他列上創建非唯一索引,加速查詢。
4、 索引優缺點
索引的優點
1.大大加快數據的檢索速度;
2.創建唯一性索引,保證數據庫表中每一行數據的唯一性;
3.加速表和表之間的連接;
4.在使用分組和排序子句進行數據檢索時,可以顯著減少查詢中分組和排序的時間。
有索引且查詢條件能使用索引時,數據庫會先選取索引,根據索引內容和查詢條件,查詢出rowid,再根據rowid取出需要的數據。由於索引內容通常比全表內容要少很多,因此通過先讀索引,能減少i/o,提高查詢性能。
索引的缺點
1.索引需要占物理空間。
2.當對表中的數據進行增加、刪除和修改的時候,索引也要動態的維護,降低了數據的維護速度。
5、 創建索引的原則
創建索引:創建索引一般有以下兩個目的:維護被索引列的唯一性和提供快速訪問表中數據
的策略。
--在select 操作占大部分的表上創建索引;
--在where 子句中出現最頻繁的列上創建索引;
--在選擇性高的列上創建索引(補充索引選擇性,最高是1,eg:primary key)
--復合索引的主列應該是最有選擇性的和where 限定條件最常用的列,並以此類推第二列……。
--小於5M 的表,最好不要使用索引來查詢,表越小,越適合用全表掃描。
6、 使用索引的原則
--查詢結果是所有數據行的5%以下時,使用index 查詢效果最好;
--where 條件中經常用到表的多列時,使用復合索引效果會好於幾個單列索引。因為當sql
語句所查詢的列,全部都出現在復合索引中時,此時由於Oracle 只需要查詢索引塊即可獲
得所有數據,當然比使用多個單列索引要快得多;
--索引利於select,但對經常insert,delte尤其update 的表,會降低效率。
eg:試比較下面兩條SQL 語句(emp 表的deptno 列上建有ununique index):
語句A:SELECT dname, deptno FROM dept WHEREdeptno NOT IN
(SELECTdeptno FROM emp);
語句B:SELECT dname, deptno FROM dept WHERE NOTEXISTS
(SELECTdeptno FROM emp WHERE dept.deptno = emp.deptno);
注意:這兩條查詢語句實現的結果是相同的,但是執行語句A 的時候,ORACLE 會對整個emp 表進行掃描,沒有使用建立在emp 表上的deptno 索引,執行語句B 的時候,由於在子查詢中使用了聯合查詢,ORACLE 只是對emp 表進行的部分數據掃描,並利用了deptno 列的索引,
所以語句B 的效率要比語句A 的效率高。
----where子句中的這個字段,必須是復合索引的第一個字段;
eg:一個索引是按f1, f2, f3 的次序建立的,若where 子句是f2 = : var2, 則因為f2 不是索引的第1 個字段,無法使用該索引。
---- where 子句中的這個字段,不應該參與任何形式的計算:任何對列的操作都將導致表掃描,它包括數據庫函數、計算表達式等等,查詢時要盡可能將操作移至等號右邊。
---- 應盡量熟悉各種操作符對Oracle 是否使用索引的影響:以下這些操作會顯式( explicitly )地阻止Oracle 使用索引: is null ; is not null; not in; !=; like ;
numeric_col+0;date_col+0;char_col||' '; to_char; to_number,to_date 等。
Eg:select jobid from mytabs where isReq='0' and to_date (updatedate)>= to_Date ( '2001-7-18','YYYY-MM-DD');--updatedate 列的索引也不會生效。
7、 創建索引
createindex abc on student(sid,sname);
createindex abc1 on student(sname,sid);
這兩種索引方式是不一樣的,索引abc 對Select * from student where sid=1; 這樣的查詢語句更有效索引abc1 對Select * from student where sname=’louis’; 這樣的查詢語句更有效因此建立索引的時候,字段的組合順序是非常重要的。一般情況下,需要經常訪問的字段放在組合字段的前面
8、 索引的存儲
索引和表都是獨立存在的。在為索引指定表空間的時候,不要將被索引的表和索引指向同
一個表空間,這樣可以避免產生IO 沖突。使Oracle 能夠並行訪問存放在不同硬盤中的索引數據和表數據,更好的提高查詢速度。
9、 刪除索引
dropindex PK_DEPT1;
10、 索引類型
索引有b-tree、bit、cluster等類型。oracle使用了一個復雜的自平衡b-tree結構;
B 樹索引(B-Tree Index)
創建索引的默認類型,結構是一顆樹,采用的是平衡B 樹算法:
右子樹節點的鍵值大於等於父節點的鍵值;左子樹節點的鍵值小於等於父節點的鍵值
比如有數據:100,101,102,103,104,105,106
位圖索引(BitMap Index)
如果表中的某些字段取值范圍比較小,比如職員性別、分數列ABC 級等。只有兩個值。
這樣的字段如果建B 樹索引沒有意義,不能提高檢索速度。這時我們推薦用位圖索引
CreateBitMap Index student on(sex);
11、 管理索引
1)先插入數據後創建索引
2)設置合理的索引列順序
3)限制每個表索引的數量
4)刪除不必要的索引
5)為每個索引指定表空間
6)經常做insert,delete 尤其是update的表最好定期exp/imp 表數據,整理數據,降低碎片(缺點:要停應用,以保持數據一致性,不實用);有索引的最好定期rebuild 索引(rebuild期間只允許表的select 操作,可在數據庫較空閒時間提交),以降低索引碎片,提高效率
綜合評價:★★★
1)命令行備份,如:
a)將數據庫test完全導出,用戶名system 密碼manager 導出到d:\daochu.dmp中,
exp system/manager@test file=d:\daochu.dmp full=y
b)將數據庫中system用戶與sys用戶的表導出 ,
expsystem/manager@test file=d:\daochu.dmp owner=(system,sys)
c)將數據庫中的表inner_notify、notify_staff_relat導出
expaichannel/aichannel@testdb2 file= d:\data\newsmgnt.dmp
tables=(inner_notify,notify_staff_relat)
詳細內容請查閱oracle相關資料
2)dmp文件導入
將d:\daochu.dmp中的數據導入 test數據庫中,
imp system/manager@test file=d:\daochu.dmp,如果已經存在需要導入的表,則使用如下命令imp system/manager@test file=d:\daochu.dmp ignore=y
將d:\daochu.dmp中的表table1 導入
imp system/manager@test file=d:\daochu.dmp tables=(table1)
i) 使用explain plan,查詢plan_table;
explainplan
setstatement_id='query1'
for
select *
from a
whereaa=1;
selectoperation, options, object_name, object_type, id, parent_id
fromplan_table
wherestatement_id = 'query1'
order byid;
ii)SQLplus中的set trace 即可看到execution plan statistics
setautotrace on;
if 初始化參數 optimizer_mode = choose then --(8i default)
if 做過表分析
then 優化器 optimizer=cbo(cost); /*高效*/
else
優化器 optimizer=rbo(rule); /*高效*/
end if;
end if;
區別:
rule根據規則選擇最佳執行路徑來運行查詢。
cbo根據表統計找到最低成本的訪問數據的方法確定執行計劃。
使用cbo需要注意:
i) 需要經常對表進行analyze命令進行分析統計;
ii) 需要穩定執行計劃;
iii)需要使用提示(hint);
使用rule需要注意:
i) 選擇最有效率的表名順序
ii) 優化SQL的寫法;
在optimizer_mode=choose時,如果表有統計信息(分區表外),優化器將選擇cbo,否則選rbo。
rbo遵循簡單的分級方法學,使用15種級別要點,當接收到查詢,優化器將評估使用到的要點數目,然後選擇最佳級別(最
少的數量)的執行路徑來運行查詢。
cbo嘗試找到最低成本的訪問數據的方法,為了最大的吞吐量或最快的初始響應時間,計算使用不同的執行計劃的成本,並
選擇成本最低的一個,關於表的數據內容的統計被用於確定執行計劃。
使用cpu多的用戶session
selecta.sid, spid, status, substr (a.program, 1, 40) prog, a.terminal,a.SQL_text,osuser, value / 60 /
100value
fromv$session a, v$process b, v$sesstat c
wherec.statistic# = 12 and c.sid = a.sid and a.paddr = b.addr
order byvalue desc;
select SQL_textfrom v$SQL
wheredisk_reads > 1000 or (executions > 0 and buffer_gets/executions> 30000);
利用trace 跟蹤
altersession set SQLtrace on;
column SQLformat a200;
selectmachine, SQL_text SQL
from v$SQLtexta, v$session b
whereaddress = SQL_address
andmachine = '&a'
order byhash_value, piece;
execdbms_system.set_SQL_trace_in_session(sid,serial#,&SQL_trace);
selectsid,serial# from v$session where sid = (select sid from v$mystat where rownum =1);
execdbms_system.set_ev(&sid,&serial#,&event_10046,&level_12,'');
可以在SQL語句中指定執行計劃。使用hints;
query_rewrite_enabled= true
star_transformation_enabled= true
optimizer_features_enable= 9.2.0
創建並使用stored outline
pctused與pctfree控制數據塊是否出現在freelist中, pctfree控制數據塊中保留用於update的空間,當數據塊中的
freespace小於pctfree設置的空間時,該數據塊從freelist中去掉,當塊由於dml操作free space大於pct_used設置的空
間時,該數據庫塊將被添加在freelist鏈表中。
tablespace:一個數據庫劃分為一個或多個邏輯單位,該邏輯單位成為表空間;每一個表空間可能包含一個或多個
segment;
segments:segment指在tablespace中為特定邏輯存儲結構分配的空間。每一個段是由一個或多個extent組成。包括數據
段、索引段、回滾段和臨時段。
extents:一個 extent 由一系列連續的 oracle blocks組成.oracle為通過extent 來給segment分配空間。
datablocks:oracle 數據庫最小的i/o存儲單位,一個data block對應一個或多個分配給data file的操作系統塊。
table創建時,默認創建了一個data segment,每個data segment含有min extents指定的extents數,每個extent據據表空
間的存儲參數分配一定數量的blocks
一個表空間可包含一個或多個數據文件。表空間利用增加或擴展數據文件擴大表空間,表空間的大小為組成該表空間的
數據文件大小的和。一個datafile只能屬於一個表空間;
一個tablespace可以有一個或多個datafile,每個datafile只能在一個tablespace內, table中的數據,通過hash算法分布
在tablespace中的各個datafile中,tablespace是邏輯上的概念,datafile則在物理上儲存了數據庫的種種對象。
本地管理表空間:(9i默認)空閒塊列表存儲在表空間的數據文件頭。
特點:減少數據字典表的競爭,當分配和收縮空間時會產生回滾,不需要合並。
字典管理表空間:(8i默認)空閒塊列表存儲在數據庫中的字典表裡.
特點:片由數據字典管理,可能造成字典表的爭用。存儲在表空間的每一個段都會有不同的存儲字句,需要合並相鄰的
塊;
本地管理表空間(locally managed tablespace簡稱lmt)
8i以後出現的一種新的表空間的管理模式,通過位圖來管理表空間的空間使用。字典管理表空間(dictionary-managed
tablespace簡稱dmt)
8i以前包括以後都還可以使用的一種表空間管理模式,通過數據字典管理表空間的空間使用。動段空間管理(assm),
它首次出現在oracle920裡有了assm,鏈接列表freelist被位圖所取代,它是一個二進制的數組,
能夠迅速有效地管理存儲擴展和剩余區塊(free block),因此能夠改善分段存儲本質,assm表空間上創建的段還有另
外一個稱呼叫bitmap managed segments(bmb 段)。
回滾段用於保存數據修改前的映象,這些信息用於生成讀一致性數據庫信息、在數據庫恢復和rollback時使用。一個事
務只能使用一個回滾段。
事務回滾:當事務修改表中數據的時候,該數據修改前的值(即前影像)會存放在回滾段中,當用戶回滾事務(
rollback)時,oracle將會利用回滾段中的數據前影像來將修改的數據恢復到原來的值。
事務恢復:當事務正在處理的時候,例程失敗,回滾段的信息保存在undo表空間中,oracle將在下次打開數據庫時利用
回滾來恢復未提交的數據。
讀一致性:當一個會話正在修改數據時,其他的會話將看不到該會話未提交的修改。當一個語句正在執行時,該語句將
看不到從該語句開始執行後的未提交的修改(語句級讀一致性)
當oracle執行select語句時,oracle依照當前的系統改變號(system change number-scn) 來保證任何前於當前scn的
未提交的改變不被該語句處理。可以想象:當一個長時間的查詢正在執行時,若其他會話改變了該查詢要查詢的某個數
據塊,oracle將利用回滾段的數據前影像來構造一個讀一致性視圖
日志文件(log file)記錄所有對數據庫數據的修改,主要是保護數據庫以防止故障,以及恢復數據時使用。其特點如
下:
a)每一個數據庫至少包含兩個日志文件組。每個日志文件組至少包含兩個日志文件成員。
b)日志文件組以循環方式進行寫操作。
c)每一個日志文件成員對應一個物理文件。
記錄數據庫事務,最大限度地保證數據的一致性與安全性
重做日志文件:含對數據庫所做的更改記錄,這樣萬一出現故障可以啟用數據恢復,一個數據庫至少需要兩個重做日志文
件
歸檔日志文件:是重做日志文件的脫機副本,這些副本可能對於從介質失敗中進行恢復很必要。
系統全局區(sga):是oracle為實例分配的一組共享緩沖存儲區,用於存放數據庫數據和控制信息,以實現對數據庫數
據的管理和操作。
sga主要包括:
a)共享池(shared pool) :用來存儲最近執行的SQL語句和最近使用的數據字典的數據。
b)數據緩沖區 (database buffer cache):用來存儲最近從數據文件中讀寫過的數據。
c)重作日志緩沖區(redo log buffer):用來記錄服務或後台進程對數據庫的操作。
另外在sga中還有兩個可選的內存結構:
d)javapool: 用來存儲java代碼。
e)largepool: 用來存儲不與SQL直接相關的大型內存結構。備份、恢復使用。
ga:db_cache/shared_pool/large_pool/java_pool
db_cache:數據庫緩存(block buffer)對於oracle數據庫的運轉和性能起著非常關鍵的作用,它占據oracle數據庫sga
(系統共享內存區)的主要部分。oracle數據庫通過使用lru算法,將最近訪問的數據塊存放到緩存中,從而優化對磁盤
數據的訪問.
shared_pool:共享池的大小對於oracle 性能來說都是很重要的。共享池中保存數據字典高速緩沖和完全解析或編譯的
的pl/SQL 塊和SQL 語句及控制結構
large_pool:使用mts配置時,因為要在sga中分配uga來保持用戶的會話,就是用large_pool來保持這個會話內存使用
rman做備份的時候,要使用large_pool這個內存結構來做磁盤i/o緩存器
java_pool:為java procedure預備的內存區域,如果沒有使用java proc,java_pool不是必須的
數據寫進程(dbwr):負責將更改的數據從數據庫緩沖區高速緩存寫入數據文件
日志寫進程(lgwr):將重做日志緩沖區中的更改寫入在線重做日志文件
系統監控 (smon): 檢查數據庫的一致性如有必要還會在數據庫打開時啟動數據庫的恢復
進程監控 (pmon): 負責在一個oracle 進程失敗時清理資源
檢查點進程(ckpt):負責在每當緩沖區高速緩存中的更改永久地記錄在數據庫中時,更新控制文件和數據文件中的數據庫
狀態信息。
歸檔進程 (arch):在每次日志切換時把已滿的日志組進行備份或歸檔
恢復進程 (reco): 保證分布式事務的一致性,在分布式事務中,要麼同時commit,要麼同時rollback;
作業調度器(cjq ): 負責將調度與執行系統中已定義好的job,完成一些預定義的工作.
邏輯備份:exp/imp 指定表的邏輯備份
物理備份:
熱備份:alter tablespace begin/end backup;
冷備份:脫機備份(database shutdown)
rman備份
fullbackup/incremental backup(累積/差異)
物理備份
物理備份是最主要的備份方式。用於保證數據庫在最小的數據庫丟失或沒有數據丟失的情況下得到恢復。
冷物理
冷物理備份提供了最簡單和最直接的方法保護數據庫因物理損壞丟失。建議在以下幾種情況中使用。
對一個已經存在大最數據量的數據庫,在晚間數據庫可以關閉,此時應用冷物理備份。
對需對數據庫服務器進行升級,(如更換硬盤),此時需要備份數據庫信息,並在新的硬盤中恢復這些數據信息,建議
采用冷物理備份。
熱物理
主要是指備份過程在數據庫打開並且用戶可以使用的情況下進行。需要執行熱物理備份的情況有:
由於數據庫性質要求不間斷工作,因而此時只能采用熱物理備份。
由於備份的要求的時間過長,而數據庫只能短時間關閉時。
邏輯備份 (exp/imp)
邏輯備份用於實現數據庫對象的恢復。但不是基於時間點可完全恢復的備份策略。只能作為聯機備份和脫機備份的一種
補充。
完全邏輯備份
完全邏輯備份是將整個數據庫導出到一個數據庫的格式文件中,該文件可以在不同的數據庫版本、操作系統和硬件平台
之間進行移植。
指定表的邏輯備份
通過備份工具,可以將指定的數據庫表備份出來,這可以避免完全邏輯備份所帶來的時間和財力上的浪費。
關於歸檔日志:oracle要將填滿的在線日志文件組歸檔時,則要建立歸檔日志(archived redo log)。其對數據庫備份
和恢復有下列用處:
數據庫後備以及在線和歸檔日志文件,在操作系統和磁盤故障中可保證全部提交的事物可被恢復。
在數據庫打開和正常系統使用下,如果歸檔日志是永久保存,在線後備可以進行和使用。
數據庫可運行在兩種不同方式下:noarchivelog方式或archivelog 方式
數據庫在noarchivelog方式下使用時,不能進行在線日志的歸檔,
數據庫在archivelog方式下運行,可實施在線日志的歸檔
歸檔是歸檔當前的聯機redo日志文件。
svrmgr>alter system archive log current;
數據庫只有運行在archivelog模式下,並且能夠進行自動歸檔,才可以進行聯機備份。有了聯機備份才有可能進行完全
恢復。
9i 新增的flash back 應該可以;
logminer應該可以找出dml。
有完善的歸檔和備份,先歸檔當前數據,然後可以先恢復到刪除的時間點之前,把drop 的表導出來,然後再恢復到最後
歸檔時間;
手工拷貝回所有備份的數據文件
SQL〉startup mount;
SQL〉alter database recover automatic until time '2004-08-04:10:30:00';
SQL〉alter database open resetlogs;
rman(recoverymanager)是dba的一個重要工具,用於備份、還原和恢復oracle數據庫, rman 可以用來備份和恢復數據
庫文件、歸檔日志、控制文件、系統參數文件,也可以用來執行完全或不完全的數據庫恢復。
rman有三種不同的用戶接口:command line方式、gui 方式(集成在oem 中的備份管理器)、api 方式(用於集成到第
三方的備份軟件中)。
具有如下特點:
1)功能類似物理備份,但比物理備份強大n倍;
2)可以壓縮空塊;
3)可以在塊水平上實現增量;
4)可以把備份的輸出打包成備份集,也可以按固定大小分割備份集;
5)備份與恢復的過程可以自動管理;
6)可以使用腳本(存在recovery catalog 中)
7)可以做壞塊監測
select * from table_name where id in (select id from table_name groupby id having count(*)>1)
select distinct * from table_name
或 select t.col1,t.col2 from table_name t group by t.col1,t.col2
單表記錄重復
1)delete from table_namewhere id not in (select max(id)from table_name group by col1,col2,...);
2)delete from table_namet where exists(select 1 from table_name where col1=t.col1 and col2=t. col2 and col3=t. col3 and id>t.id);
多表無效記錄
一、兩張關聯表,刪除主表中已經在副表中沒有的信息
delete from table1 where not exists ( select 1 from table2 wheretable1.field1=table2.field1)
二、包括所有在 tablea 中但不在 tableb和tablec 中的行並消除所有重復行而派生出一個結果表(minus、intersect)
select a from tablea minus(select afrom tableb union select a from tablec)
注:查詢表a中存在id重復3次以上的記錄
select *from a t where exists (select 1 from a t1 where t.id = t1.idgroup by id having count(id) > 3);
create table emp(
idint not null primary key,
name varchar (25),
age int
);
insert into empvalues(test_sequence.nextval,'zhang1',26);
insert into empvalues(test_sequence.nextval,'zhang2',27);
insert into empvalues(test_sequence.nextval,'zhang3',28);
insert into emp values(test_sequence.nextval,'zhang1',26);
insert into empvalues(test_sequence.nextval,'zhang2',27);
insert into empvalues(test_sequence.nextval,'zhang3',29);
insert into empvalues(test_sequence.nextval,'wang2',26);
insert into emp values(test_sequence.nextval,'wang1',22);
--解法一:查詢重復記錄的一個方法就是分組統計:
select * from emp where name in (select name from emp group by name having count(*)>1);使用in 或者exists
--查詢出重復的名稱及重復次數
方法一、select sum(1)as sig, name from emp group by name having sum(1) > 1;
方法二、select name, count(*) from empgroup by name having count(*)>1;
count(*)的效率比sum(1)要高
--解法二:如果對每個名字都和原表進行比較,大於2個人名字與這條記錄相同的就是合格的,就有:
select * from emp where ( select count(*)from emp e where e.name = emp.name )>1;
--解法三:如果有另外一個名字相同的人工號不與他相同那麼這條記錄符合要求:
select * from emp where exists (select *from emp e where e.name = emp.name and
e.id<>emp.id);
解法四:思路同解法三
select distinct emp.* from emp inner join emp e onemp.name=e.name and emp.id<>e.id;
--解法一:通過distinct、group by過濾重復
select distinct name,age from emp;
或
select name,age from emp group by name,age;
--解法二:使用臨時表
--不推薦
select distinct * into #tmp from emp;
delete from emp;
insert into emp select * from #tmp;
--解法三:使用rowid
--高效,name列使用了索引。
select * from emp a where a.rowid = (selectmin(b.rowid) from emp b where a.name = b.name);
--普通
select a.* from emp a,(select min(b.rowid)row_id from emp b group by b.name) b where a.rowid = b.row_id;
注:除id值不一樣外其它字段都一樣,每兩行記錄重復
delete from emp t where exists(select 1from emp where name = t.name and age = t.age and t.id < id)
綜合評價:★★★
(1).在oracle中,每一條記錄都有一個rowid,rowid在整個數據庫中是唯一的,rowid確定了每條記錄是在oracle中的哪一個數據文件、塊、行上。
(2).在重復的記錄中,可能所有列的內容都相同,但rowid不會相同,所以只要確定出重復記錄中那些具有最大rowid的就可以了,其余全部刪除。
重復記錄判斷的標准是:
c1,c10和c20這三列的值都相同才算是重復記錄,並且保存最新的記錄。
(1).適用於有大量重復記錄的情況(在c1,c10和c20列上建有索引的時候,用以下語句效率會很高):
方法一、delete from cz where(c1,c10,c20) in (select c1,c10,c20 from cz group by c1,c10,c20 havingcount(*)>1) and rowid not in selectmin(rowid) from cz group by c1,c10,c20 having count(*)>1);
方法二、delete from cz where rowid not in(select min(rowid) fromcz group by c1,c10,c20);
(2).適用於有少量重復記錄的情況(注意,對於有大量重復記錄的情況,用以下語句效率會很低):
方法一、delete from cz a where a.rowid!=(select max(rowid) from cz b wherea.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);
方法二、delete from cz a where a.rowid<(select max(rowid) from cz b wherea.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);
方法三、delete from cz a where rowid <(select max(rowid) from cz wherec1=a.c1 and c10=a.c10 and c20=a.c20);
詳細教程:http://www.csdn.net/article/2010-08-17/278287
注:隨機取出n條數據
1)select * from (select * from tablename order bysys_guid()) where rownum < n;
2)select * from (select * from tablename order by dbms_random.value)where rownum< n
3) select * from (select *from tablename sample(n) order by trunc(dbms_random.value(0,1000))) where rownum < n;
說明: sample(n)含義為檢索表中的n%數據,sample值應該在[0.000001,99.999999]之間。
其中 sys_guid() 和 dbms_random.value都是內部函數。
oracle中一般獲取隨機數的方法是
select trunc(dbms_random.value(0,1000)) from dual; (0-1000的整數)
select dbms_random.value(0, 1000) fromdual; (0-1000的浮點數)
case expression
when value then statement
[when value then statement ]...
[else statement [, statement ]... ]
end case;
case
when (boolean_condition1) then action1;
when (boolean_condition2) then action2;
when (boolean_condition3) then action3;
……
else action;
end case;
有一張表,裡面有3個字段:語文,數學,英語。其中有3條記錄分別表示語文70分,數學80分,英語58分,請用一條SQL語句查詢出這三條記錄並按以下條件顯示出來。大於或等於80表示優秀,大於或等於60表示及格,小於60分表示不及格。
顯示格式:
語文 數學 英語
及格 優秀 不及格
------------------------------------------
select
(case when 語文>=80 then '優秀'
when 語文>=60 then '及格'
else '不及格') as 語文,
(case when 數學>=80 then'優秀'
when 數學>=60 then '及格'
else '不及格') as 數學,
(case when 英語>=80 then'優秀'
when 英語>=60 then '及格'
else '不及格') as 英語
from table
一、日程安排提前五分鐘提醒(oracle 日期函數)
select * from 日程安排 where datediff(‘minute’,開始時間,getdate())>5
二、請取出tb_send表中日期(sendtime字段)為當天的所有記錄?(sendtime字段為date型,包含日期與時間)
select * from tb_send t where to_char(t.sendtime,’yyyy-mm-dd’) = to_char(sysdate,’yyyy-mm-dd’)
綜合評價:★★
1.select trunc(sysdate) from dual --2011-3-18 今天的日期為2011-3-18
2.select trunc(sysdate, 'mm') from dual --2011-3-1 返回當月第一天.
3.select trunc(sysdate,'yy') from dual --2011-1-1 返回當年第一天
4.select trunc(sysdate,'dd') from dual --2011-3-18 返回當前年月日
5.select trunc(sysdate,'yyyy') from dual --2011-1-1 返回當年第一天
6.select trunc(sysdate,'d') from dual --2011-3-13 (星期天)返回當前星期的第一天
7.select trunc(sysdate, 'hh') from dual --2011-3-18 14:00:00 當前時間為14:41
8.select trunc(sysdate, 'mi') from dual --2011-3-18 14:41:00 trunc()函數沒有秒的精確
注:trunc(number,num_digits) number 需要截尾取整的數字。 num_digits 用於指定取整精度的數字。num_digits 的默認值為 0。trunc()函數截取時不進行四捨五入
9.select trunc(123.458) from dual --123
10.select trunc(123.458,0) from dual --123
11.select trunc(123.458,1) from dual --123.4
12.select trunc(123.458,-1) from dual --120
13.select trunc(123.458,-4) from dual --0
14.select trunc(123.458,4) from dual --123.458
15.select trunc(123) from dual --123
16.select trunc(123,1) from dual --123
17.select trunc(123,-1) from dual –120
綜合評價:★★
select datepart(dd,dateadd(dd,-1,dateadd(mm,1,cast(cast(year(getdate()) as varchar)+'-'+cast(month(getdate()) as varchar)+'-01' as datetime))))
selectadd_months(trunc(sysdate, 'yyyy'), 12) - trunc(sysdate, 'yyyy') days from dual
selectto_number(to_char(last_day(trunc(sysdate)),'dd')) from dual
select to_number(add_months(trunc(to_date('2013-06-1710:09:02',
'yyyy-fmmm-ddhh24:mi:ss'), 'mm'), 1) - trunc(to_date('2013-06-17 10:09:02',
'yyyy-fmmm-ddhh24:mi:ss'), 'mm')) from dual;
只用一條SQL語句,要求從左表查詢出右表
lefttable: righttable:
id name id name
---------- ------------------
1 a5 1 a5,a8,af....
2 a8 2 b5,b3,bd....
3 af 3 c3,ck,ci....
4 b5
5 b3
6 bd
7 c3
8 ck
9 ci
解答:
select replace(wmsys.wm_concat(t.name),',',',')from lefttable t group by substr(t.name,0,1);
oracle 常用函數,nvl、遞歸、字符串操作、日期操作、數字操作
case when、正則表達式操作
參照表:test_tb_grade
題目:查詢6到10條數據。
解法一、注:采用rownum關鍵字(三層嵌套)
select * from (
select t.*,rownum rn from
(select * from test_tb_grade order by user_id) t where rownum <= 10)
where rn >=6;
解法二、注:采用row_number解析函數進行分頁(效率更高)
select * from (
select t.*, row_number() over(order by t.user_id) rn from test_tb_grade t)
where rn between 6 and 10;
create table test_tb_grade -- 學生語文、數學、英語成績統計
(
user_id number(10) not nullprimary key,
user_name varchar2(20),
course varchar2(20),
score float
);
create sequence test_sequence;
insert into test_tb_gradevalues(test_sequence.nextval,'m','c',78);
insert into test_tb_gradevalues(test_sequence.nextval,'m','m',95);
insert into test_tb_gradevalues(test_sequence.nextval,'m','e',81);
insert into test_tb_gradevalues(test_sequence.nextval,'z','c',97);
insert into test_tb_gradevalues(test_sequence.nextval,'z','m',78);
insert into test_tb_gradevalues(test_sequence.nextval,'z','e',91);
insert into test_tb_gradevalues(test_sequence.nextval,'l','c',80);
insert into test_tb_grade values(test_sequence.nextval,'l','m',55);
insert into test_tb_gradevalues(test_sequence.nextval,'l','e',75);
insert into test_tb_gradevalues(test_sequence.nextval,'v','c',49);
insert into test_tb_gradevalues(test_sequence.nextval,'v','m',63);
insert into test_tb_grade values(test_sequence.nextval,'v','e',70);
insert into test_tb_gradevalues(test_sequence.nextval,'k','e',53);
insert into test_tb_gradevalues(test_sequence.nextval,'k','m',58);
insert into test_tb_gradevalues(test_sequence.nextval,'k','c',59);
insert into test_tb_gradevalues(test_sequence.nextval,'k','c',59);
commit;
列出不同科目下學生對應的成績,如圖
注:sum聚集函數也可以用max、min、avg等其他聚集函數替代。不同聚合函數得到結果根據數據會有稍微的差異
select user_name,
sum(decode(course,'c',score,null)) aschinese,
sum(decode(course,'m',score,null)) as math,
sum(decode(course,'e',score,null)) as english
from test_tb_grade
group by user_name
order by 1;
create table test_tb_grade2 (
gidnumber(10) primary key,
sname varchar2(20),
cn_score float,
math_score float,
en_score float
);
insert into test_tb_grade2 values(test_sequence.nextval,'m',70,65,60);
insert into test_tb_grade2 values(test_sequence.nextval,'l',74,83,76);
insert into test_tb_grade2 values(test_sequence.nextval,'v',80,68,89);
insert into test_tb_grade2 values (test_sequence.nextval,'k',80,83,82);
insert into test_tb_grade2 values(test_sequence.nextval,'z',58,86,80);
commit;
查詢結果如圖:
需要實現到如下效果:
方法一、union all
select t2.sname,'chinese' as course,t2.cn_score as score from test_tb_grade2 t2 -- 語文
union all
select t2.sname,'math' as course,t2.math_score as score from test_tb_grade2 t2 -- 數學
union all
select t2.sname,'english' as course,t2.en_score as score from test_tb_grade2 t2 -- 英語
方法二、model (復雜)
方法三、collection(涉及到數組、集合、對象)
實現對各門功課的不同分數段的學生進行統計(0-60,60-70,70-80..)
方法一、select t2.course,count(t2.course),'0-60'as ts from (
select t.course,t.score from test_tb_gradet group by t.course,t.score having t.score<60 ) t2 group by t2.course
union all
select t2.course,count(t2.course),'60-70'asts from (
select t.course,t.score from test_tb_gradet group by t.course,t.score having t.score>60 and t.score<=70 ) t2 groupby t2.course….
方法二、select t.course,
case
when t.score<= 60 then '0-60'
when 60< t.score and t.score <=70 then '60-70'
when 70< t.score and t.score <=80 then '70-80'
when 80< t.score then '80-100'
else 'error' end as score_cp,
count(t.course)
fromtest_tb_grade t group by t.course
得到如下視圖
參照表:test_tb_grade
題目:查詢出每個學生分數最高的兩門課(允許並列第二)
解法一、注:使用左聯接和分組函數
select t1.user_id,t1.user_name,t1.course,t1.score from test_tb_grade t1 left
join test_tb_grade t2 on t1.user_name =t2.user_name and t1.score < t2.score
group by t1.user_id,t1.user_name,t1.course,t1.score
having count(t2.user_id) < 2;
解法二、注:oracle分析函數(不出現並列)
select * from (
select user_id, user_name, course, score, row_number()over(partition by user_nameorder by score desc) rn from test_tb_grade) where rn <= 2;
解法三、注:使用關聯子查詢
select * from test_tb_grade t where 2 > (
select count(*) from test_tb_grade where user_name= t.user_name and t.score < score);
參照表:test_tb_grade
題目:查詢每個單科分數最高的信息
解法一、注:分組函數不能放到where後面
select * from test_tb_grade t where t.score=
( select max(score) from test_tb_gradewhere course = t.course) order by t.user_name;
解法二、注:使用notexists 關鍵字
select * from test_tb_grade t where not exists
(select 1 from test_tb_grade where course = t. course andt.score < score);
解法三、注:使用內連接查詢
select t.* from test_tb_grade t,
(select course,max(score) score fromtest_tb_grade group by course) t1
where t. course = t1. course and t.score =t1.score;
解法四、注:使用關聯子查詢
select t.* from test_tb_grade t where 1> (select count(*) from test_tb_grade where user_name = t.user_name andt.score < score);
一、s(s#,sn,sd,sa) s#,sn,sd,sa分別代表學號,學員姓名,所屬單位,學員年齡
c(c#,cn) c#,cn分別代表課程編號,課程名稱
sc(s#,c#,g) s#,c#,g分別代表學號,所選的課程編號,學習成績
(1)使用標准SQL嵌套語句查詢選修課程名稱為’稅收基礎’的學員學號和姓名?
答案:select s# ,sn from s where s# in(select s# from c,sc wherec.c#=sc.c# and cn=’稅收基礎’)
selects.s#, s.sn from sc,s,c where c.c# = sc.c# and sc.s# = s.s# and c.cn = ‘稅收基礎’;
selects#, sn from s where exists (select 1 from c,sc where c.c# = sc.c# and c.cn = ‘稅收基礎’ andsc.s# = s.s#);
(2) 使用標准SQL嵌套語句查詢選修課程編號為’c2’的學員姓名和所屬單位?
答:select sn,sd from s,sc where s.s#=sc.s# and sc.c#=’c2’;
(3) 使用標准SQL嵌套語句查詢不選修課程編號為’c5’的學員姓名和所屬單位?
答:select sn,sd from s where s# not in(select s# from sc where c#=’c5’)
(4)查詢選修了課程的學員人數
selectcount(distinct s#) 學員人數 from sc;
(5) 查詢選修課程超過5門的學員學號和所屬單位
selectsn,sd from s where s# in(select s# from sc group by s# having count(distinctc#)>5)
selects#, sd from s t where exists (select 1 from sc where t.s# = s# group by #having count(distinct c#)>5);
(6)查詢a(id,name)表中第31至40條記錄,id作為主鍵可能是不是連續增長的列
SQLserver:
select top 10 * from (select top 40 * from a order by id)order by id desc;
mySQL:
select * from a limit 31,40;
oracle:rownum 始終從下一個整數開始,第一值是1,如果前9個值可以確定,那下一個值就10(rownum 是偽列)
select * from (select t.*, rownum rn from at where rownum <= 40 order by id) t1 where t1.rn => 31;
(7)查詢表a中存在id重復三次以上的記錄
select *from a t where exists (select 1 from a t1 where t1.id = t.id group by id havingcount(id) > 3);
(8)游標使用
-- 聲明游標;CURSOR cursor_name IS select_statement
--For 循環游標
--(1)定義游標
--(2)定義游標變量
--(3)使用for循環來使用這個游標
declare
--類型定義
cursor c_job
is
select empno,ename,job,sal
from emp
where job='MANAGER';
--定義一個游標變量v_cinfoc_emp%ROWTYPE ,該類型為游標c_emp中的一行數據類型
c_row c_job%rowtype;
begin
for c_row in c_job loop
dbms_output.put_line(c_row.empno||'-'||c_row.ename||'-'||c_row.job||'-'||c_row.sal);
end loop;
end;
--Fetch游標
--使用的時候必須要明確的打開和關閉
declare
--類型定義
cursor c_job
is
select empno,ename,job,sal
from emp
where job='MANAGER';
--定義一個游標變量
c_row c_job%rowtype;
begin
open c_job;
loop
--提取一行數據到c_row
fetch c_job into c_row;
--判讀是否提取到值,沒取到值就退出
--取到值c_job%notfound 是false
--取不到值c_job%notfound 是true
exit when c_job%notfound;
dbms_output.put_line(c_row.empno||'-'||c_row.ename||'-'||c_row.job||'-'||c_row.sal);
end loop;
--關閉游標
close c_job;
end;
--1:任意執行一個update操作,用隱式游標sql的屬性%found,%notfound,%rowcount,%isopen觀察update語句的執行情況。
begin
update emp set ENAME='ALEARK' WHEREEMPNO=7469;
if sql%isopen then
dbms_output.put_line('Openging');
else
dbms_output.put_line('closing');
end if;
if sql%found then
dbms_output.put_line('游標指向了有效行');--判斷游標是否指向有效行
else
dbms_output.put_line('Sorry');
end if;
if sql%notfound then
dbms_output.put_line('Also Sorry');
else
dbms_output.put_line('Haha');
end if;
dbms_output.put_line(sql%rowcount);
exception
when no_data_found then
dbms_output.put_line('Sorry No data');
when too_many_rows then
dbms_output.put_line('Too Many rows');
end;
declare
empNumber emp.EMPNO%TYPE;
empName emp.ENAME%TYPE;
begin
if sql%isopen then
dbms_output.put_line('Cursor is opinging');
else
dbms_output.put_line('Cursor is Close');
end if;
if sql%notfound then
dbms_output.put_line('No Value');
else
dbms_output.put_line(empNumber);
end if;
dbms_output.put_line(sql%rowcount);
dbms_output.put_line('-------------');
select EMPNO,ENAME into empNumber,empName fromemp where EMPNO=7499;
dbms_output.put_line(sql%rowcount);
if sql%isopen then
dbms_output.put_line('Cursor is opinging');
else
dbms_output.put_line('Cursor is Closing');
end if;
if sql%notfound then
dbms_output.put_line('No Value');
else
dbms_output.put_line(empNumber);
end if;
exception
when no_data_found then
dbms_output.put_line('No Value');
when too_many_rows then
dbms_output.put_line('too many rows');
end;
--2,使用游標和loop循環來顯示所有部門的名稱
--游標聲明
declare
cursor csr_dept
is
--select語句
select DNAME
from Depth;
--指定行指針,這句話應該是指定和csr_dept行類型相同的變量
row_dept csr_dept%rowtype;
begin
--for循環
for row_dept in csr_dept loop
dbms_output.put_line('部門名稱:'||row_dept.DNAME);
end loop;
end;
--3,使用游標和while循環來顯示所有部門的的地理位置(用%found屬性)
declare
--游標聲明
cursor csr_TestWhile
is
--select語句
select LOC
from Depth;
--指定行指針
row_loc csr_TestWhile%rowtype;
begin
--打開游標
open csr_TestWhile;
--給第一行喂數據
fetch csr_TestWhile into row_loc;
--測試是否有數據,並執行循環
while csr_TestWhile%found loop
dbms_output.put_line('部門地點:'||row_loc.LOC);
--給下一行喂數據
fetch csr_TestWhile into row_loc;
end loop;
close csr_TestWhile;
end;
select *from emp
--4,接收用戶輸入的部門編號,用for循環和游標,打印出此部門的所有雇員的所有信息(使用循環游標)
--CURSORcursor_name[(parameter[,parameter],...)] IS select_statement;
--定義參數的語法如下:Parameter_name [IN] data_type[{:=|DEFAULT} value]
declare
CURSOR
c_dept(p_deptNo number)
is
select * from emp where emp.depno=p_deptNo;
r_emp emp%rowtype;
begin
for r_emp in c_dept(20) loop
dbms_output.put_line('員工號:'||r_emp.EMPNO||'員工名:'||r_emp.ENAME||'工資:'||r_emp.SAL);
end loop;
end;
select *from emp
--5:向游標傳遞一個工種,顯示此工種的所有雇員的所有信息(使用參數游標)
declare
cursor
c_job(p_job nvarchar2)
is
select * from emp where JOB=p_job;
r_job emp%rowtype;
begin
for r_job in c_job('CLERK') loop
dbms_output.put_line('員工號'||r_job.EMPNO||' '||'員工姓名'||r_job.ENAME);
end loop;
end;
SELECT *FROM EMP
--6:用更新游標來為雇員加傭金:(用if實現,創建一個與emp表一摸一樣的emp1表,對emp1表進行修改操作),並將更新前後的數據輸出出來
create table emp1 as select * from emp;
declare
cursor
csr_Update
is
select * from emp1 for update OF SAL;
empInfo csr_Update%rowtype;
saleInfo emp1.SAL%TYPE;
begin
FOR empInfo IN csr_Update LOOP
IF empInfo.SAL<1500 THEN
saleInfo:=empInfo.SAL*1.2;
elsif empInfo.SAL<2000 THEN
saleInfo:=empInfo.SAL*1.5;
elsif empInfo.SAL<3000 THEN
saleInfo:=empInfo.SAL*2;
END IF;
UPDATE emp1 SET SAL=saleInfo WHERE CURRENT OFcsr_Update;
END LOOP;
END;
--7:編寫一個PL/SQL程序塊,對名字以‘A’或‘S’開始的所有雇員按他們的基本薪水(sal)的10%給他們加薪(對emp1表進行修改操作)
declare
cursor
csr_AddSal
is
select * from emp1 where ENAME LIKE 'A%' ORENAME LIKE 'S%' for update OF SAL;
r_AddSal csr_AddSal%rowtype;
saleInfo emp1.SAL%TYPE;
begin
for r_AddSal in csr_AddSal loop
dbms_output.put_line(r_AddSal.ENAME||'原來的工資:'||r_AddSal.SAL);
saleInfo:=r_AddSal.SAL*1.1;
UPDATE emp1 SET SAL=saleInfo WHERE CURRENT OFcsr_AddSal;
end loop;
end;
--8:編寫一個PL/SQL程序塊,對所有的salesman增加傭金(comm)500
declare
cursor
csr_AddComm(p_job nvarchar2)
is
select * from emp1 where JOB=p_job FOR UPDATEOF COMM;
r_AddComm emp1%rowtype;
commInfo emp1.comm%type;
begin
for r_AddComm in csr_AddComm('SALESMAN') LOOP
commInfo:=r_AddComm.COMM+500;
UPDATE EMP1 SET COMM=commInfo where CURRENT OFcsr_AddComm;
END LOOP;
END;
--9:編寫一個PL/SQL程序塊,以提升2個資格最老的職員為MANAGER(工作時間越長,資格越老)
--(提示:可以定義一個變量作為計數器控制游標只提取兩條數據;也可以在聲明游標的時候把雇員中資格最老的兩個人查出來放到游標中。)
declare
cursor crs_testComput
is
select * from emp1 order by HIREDATE asc;
--計數器
top_two number:=2;
r_testComput crs_testComput%rowtype;
begin
open crs_testComput;
FETCH crs_testComput INTO r_testComput;
while top_two>0 loop
dbms_output.put_line('員工姓名:'||r_testComput.ENAME||' 工作時間:'||r_testComput.HIREDATE);
--計速器減一
top_two:=top_two-1;
FETCH crs_testComput INTO r_testComput;
end loop;
close crs_testComput;
end;
--10:編寫一個PL/SQL程序塊,對所有雇員按他們的基本薪水(sal)的20%為他們加薪,
--如果增加的薪水大於300就取消加薪(對emp1表進行修改操作,並將更新前後的數據輸出出來)
declare
cursor
crs_UpadateSal
is
select * from emp1 for update of SAL;
r_UpdateSal crs_UpadateSal%rowtype;
salAdd emp1.sal%type;
salInfo emp1.sal%type;
begin
for r_UpdateSal in crs_UpadateSal loop
salAdd:= r_UpdateSal.SAL*0.2;
if salAdd>300 then
salInfo:=r_UpdateSal.SAL;
dbms_output.put_line(r_UpdateSal.ENAME||': 加薪失敗。'||'薪水維持在:'||r_UpdateSal.SAL);
else
salInfo:=r_UpdateSal.SAL+salAdd;
dbms_output.put_line(r_UpdateSal.ENAME||': 加薪成功.'||'薪水變為:'||salInfo);
end if;
update emp1 set SAL=salInfo where current ofcrs_UpadateSal;
end loop;
end;
--11:將每位員工工作了多少年零多少月零多少天輸出出來
--近似
--CEIL(n)函數:取大於等於數值n的最小整數
--FLOOR(n)函數:取小於等於數值n的最大整數
--truc的用法http://publish.it168.com/2005/1028/20051028034101.shtml
declare
cursor
crs_WorkDay
is
select ENAME,HIREDATE,trunc(months_between(sysdate, hiredate) / 12) AS SPANDYEARS,
trunc(mod(months_between(sysdate, hiredate),12)) AS months,
trunc(mod(mod(sysdate - hiredate, 365), 12))as days
from emp1;
r_WorkDay crs_WorkDay%rowtype;
begin
for r_WorkDay in crs_WorkDay loop
dbms_output.put_line(r_WorkDay.ENAME||'已經工作了'||r_WorkDay.SPANDYEARS||'年,零'||r_WorkDay.months||'月,零'||r_WorkDay.days||'天');
end loop;
end;
--12:輸入部門編號,按照下列加薪比例執行(用CASE實現,創建一個emp1表,修改emp1表的數據),並將更新前後的數據輸出出來
--deptno raise(%)
-- 10 5%
-- 2010%
-- 3015%
-- 4020%
-- 加薪比例以現有的sal為標准
--CASEexpr WHEN comparison_expr THEN return_expr
--[,WHEN comparison_expr THEN return_expr]... [ELSE else_expr] END
declare
cursor
crs_caseTest
is
select * from emp1 for update of SAL;
r_caseTest crs_caseTest%rowtype;
salInfo emp1.sal%type;
begin
for r_caseTest in crs_caseTest loop
case
when r_caseTest.DEPNO=10
THEN salInfo:=r_caseTest.SAL*1.05;
when r_caseTest.DEPNO=20
THEN salInfo:=r_caseTest.SAL*1.1;
when r_caseTest.DEPNO=30
THEN salInfo:=r_caseTest.SAL*1.15;
when r_caseTest.DEPNO=40
THEN salInfo:=r_caseTest.SAL*1.2;
end case;
update emp1 set SAL=salInfo where current ofcrs_caseTest;
end loop;
end;
--13:對每位員工的薪水進行判斷,如果該員工薪水高於其所在部門的平均薪水,則將其薪水減50元,輸出更新前後的薪水,員工姓名,所在部門編號。
--AVG([distinct|all]expr) over (analytic_clause)
---作用:
--按照analytic_clause中的規則求分組平均值。
--分析函數語法:
--FUNCTION_NAME(,...)
--OVER
--()
--PARTITION子句
--按照表達式分區(就是分組),如果省略了分區子句,則全部的結果集被看作是一個單一的組
select * from emp1
DECLARE
CURSOR
crs_testAvg
IS
select EMPNO,ENAME,JOB,SAL,DEPNO,AVG(SAL) OVER(PARTITION BY DEPNO ) AS DEP_AVG
FROM EMP1 for update of SAL;
r_testAvg crs_testAvg%rowtype;
salInfo emp1.sal%type;
begin
for r_testAvg in crs_testAvg loop
if r_testAvg.SAL>r_testAvg.DEP_AVG then
salInfo:=r_testAvg.SAL-50;
end if;
update emp1 set SAL=salInfo where current ofcrs_testAvg;
end loop;
end;
1) 存儲過程、游標使用
2) Oracle常用函數、分析函數、oracle 遞歸查詢
3) 基於oracle的SQL優化
4) 數據庫設計原則、設計規范學習
5) 教材:數據庫設計與開發、數據庫設計入門。。。。