首先構造兩個基本表 emp(員工表) 與 dept(部門表):
SQL> create table emp as select * from scott.emp;
Table created.
SQL> create table dept as select * from scott.dept;
Table created.
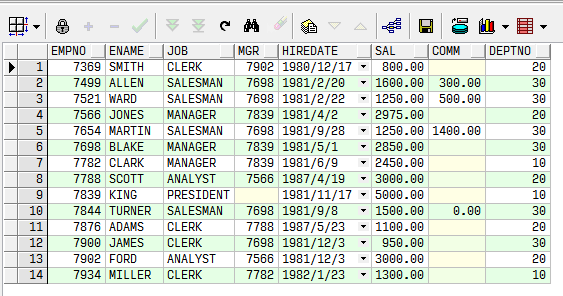
SQL> select * from emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- --------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30
7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30
7566 JONES MANAGER 7839 02-APR-81 2975 20
7654 MARTIN SALESMAN 7698 28-SEP-81 1250 1400 30
7698 BLAKE MANAGER 7839 01-MAY-81 2850 30
7782 CLARK MANAGER 7839 09-JUN-81 2450 10
7788 SCOTT ANALYST 7566 19-APR-87 3000 20
7839 KING PRESIDENT 17-NOV-81 5000 10
7844 TURNER SALESMAN 7698 08-SEP-81 1500 0 30
7876 ADAMS CLERK 7788 23-MAY-87 1100 20
7900 JAMES CLERK 7698 03-DEC-81 950 30
7902 FORD ANALYST 7566 03-DEC-81 3000 20
7934 MILLER CLERK 7782 23-JAN-82 1300 10
14 rows selected.
SQL> select * from dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
如果想統計每個部門每個職位的總薪水,sql 語句如下:
SQL> select b.dname, a.job, sum(a.sal) 2 from emp a, dept b 3 where a.deptno = b.deptno 4 group by b.dname, a.job; DNAME JOB SUM(A.SAL) -------------- --------- ---------- SALES MANAGER 2850 SALES CLERK 950 ACCOUNTING MANAGER 2450 ACCOUNTING PRESIDENT 5000 ACCOUNTING CLERK 1300 SALES SALESMAN 5600 RESEARCH MANAGER 2975 RESEARCH ANALYST 6000 RESEARCH CLERK 1900 9 rows selected.
SQL> select b.dname, a.job, sum(a.sal)
2 from emp a, dept b
3 where a.deptno = b.deptno
4 group by rollup(b.dname, a.job);
DNAME JOB SUM(A.SAL)
-------------- --------- ----------
SALES CLERK 950
SALES MANAGER 2850
SALES SALESMAN 5600
SALES 9400
RESEARCH CLERK 1900
RESEARCH ANALYST 6000
RESEARCH MANAGER 2975
RESEARCH 10875
ACCOUNTING CLERK 1300
ACCOUNTING MANAGER 2450
ACCOUNTING PRESIDENT 5000
ACCOUNTING 8750
29025
從上面的結果中可以看出,rollup 子句會為每個部門增加一行小計以及為所有部門增加一行總計,即統計了每個部門的總薪水以及所有部門的總薪水。
通常來說,rollup 往往同 group by 語句一起使用,它是 group by 語句的一種擴展。
如果語句為 group by rollup(a, b),oracle 將會從右到左先對字段 a 和 b 先進行 group by,然後對字段 A 進行 group by,最後對全表進行 group by。如果語句為 group by rollup(a, b, c), oracle 將從右到左先會對字段 a 和 b 和 c 先進行 group by, 然後對字段 a 和 b 進行 group by,然後對字段 a 進行 group by,最後對全表進行 group by。
下面我們將演示一個 rollup 三個字段的例子:
SQL> select b.dname, a.job, to_char(hiredate, 'yyyy'), sum(sal)
2 from emp a, dept b
3 where a.deptno = b.deptno
4 group by b.dname, a.job, to_char(hiredate, 'yyyy')
5 order by 1, 2, 3;
DNAME JOB TO_C SUM(SAL)
-------------- --------- ---- ----------
ACCOUNTING CLERK 1982 1300
ACCOUNTING MANAGER 1981 2450
ACCOUNTING PRESIDENT 1981 5000
RESEARCH ANALYST 1981 3000
RESEARCH ANALYST 1987 3000
RESEARCH CLERK 1980 800
RESEARCH CLERK 1987 1100
RESEARCH MANAGER 1981 2975
SALES CLERK 1981 950
SALES MANAGER 1981 2850
SALES SALESMAN 1981 5600
11 rows selected.
SQL> select b.dname, a.job, to_char(hiredate, 'yyyy'), sum(sal)
2 from emp a, dept b
3 where a.deptno = b.deptno
4 group by rollup(b.dname, a.job, to_char(hiredate, 'yyyy'));
DNAME JOB TO_C SUM(SAL)
-------------- --------- ---- ----------
SALES CLERK 1981 950
SALES CLERK 950
SALES MANAGER 1981 2850
SALES MANAGER 2850
SALES SALESMAN 1981 5600
SALES SALESMAN 5600
SALES 9400
RESEARCH CLERK 1980 800
RESEARCH CLERK 1987 1100
RESEARCH CLERK 1900
RESEARCH ANALYST 1981 3000
RESEARCH ANALYST 1987 3000
RESEARCH ANALYST 6000
RESEARCH MANAGER 1981 2975
RESEARCH MANAGER 2975
RESEARCH 10875
ACCOUNTING CLERK 1982 1300
ACCOUNTING CLERK 1300
ACCOUNTING MANAGER 1981 2450
ACCOUNTING MANAGER 2450
ACCOUNTING PRESIDENT 1981 5000
ACCOUNTING PRESIDENT 5000
ACCOUNTING 8750
29025
24 rows selected.
1.3 部分 rollup(Partial rollup)
當你只想統計部分字段時, 可以使用部分 rollup. 例如, group by a, rollup(b, c), 這條語句將創建三個(2 + 1)級別的小計. 分別為級別 (a, b, c), 級別 (a, b) 以及級別 (a).
SQL> select b.dname, a.job, to_char(hiredate, 'yyyy'), sum(sal) 2 from emp a, dept b 3 where a.deptno = b.deptno 4 group by b.dname, rollup(a.job, to_char(hiredate, 'yyyy')); DNAME JOB TO_C SUM(SAL) -------------- --------- ---- ---------- SALES CLERK 1981 950 SALES CLERK 950 SALES MANAGER 1981 2850 SALES MANAGER 2850 SALES SALESMAN 1981 5600 SALES SALESMAN 5600 SALES 9400 RESEARCH CLERK 1980 800 RESEARCH CLERK 1987 1100 RESEARCH CLERK 1900 RESEARCH ANALYST 1981 3000 RESEARCH ANALYST 1987 3000 RESEARCH ANALYST 6000 RESEARCH MANAGER 1981 2975 RESEARCH MANAGER 2975 RESEARCH 10875 ACCOUNTING CLERK 1982 1300 ACCOUNTING CLERK 1300 ACCOUNTING MANAGER 1981 2450 ACCOUNTING MANAGER 2450 ACCOUNTING PRESIDENT 1981 5000 ACCOUNTING PRESIDENT 5000 ACCOUNTING 8750 23 rows selected.
從上面的結果中可以看出,部分 rollup 產生的結果:
普通的匯總行是由 group by 產生而不是 rollup不會產生總計
2. cube
cube 可以為指定的列創建各種不同組合的小計. 如果指定的列的數量為 n, group by cube 將創建 2 * n 個層次的小計. cube 是一種比 rollup 更細粒度的分組統計語句。先看看 cube 語句的結果:
2.1 什麼時候使用 cube
當需求中有類似 cross-tabular report (交叉報表)時對於數據倉庫中的統計匯總表, rollup 能夠簡化統計匯總表並且提高查詢統計匯總表的速度
2.2 cube 例子
SQL> select b.dname, a.job, sum(a.sal)
2 from emp a, dept b
3 where a.deptno = b.deptno
4 group by cube(b.dname, a.job);
DNAME JOB SUM(A.SAL)
-------------- --------- ----------
29025
CLERK 4150
ANALYST 6000
MANAGER 8275
SALESMAN 5600
PRESIDENT 5000
SALES 9400
SALES CLERK 950
SALES MANAGER 2850
SALES SALESMAN 5600
RESEARCH 10875
RESEARCH CLERK 1900
RESEARCH ANALYST 6000
RESEARCH MANAGER 2975
ACCOUNTING 8750
ACCOUNTING CLERK 1300
ACCOUNTING MANAGER 2450
ACCOUNTING PRESIDENT 5000
18 rows selected.
如果語句為 group by cube(a, b),oracle 首先對字段 a 和 b 進行 group by,然後對字段 a 進行 group by,然後對字段 b 進行 group by,最後對全表進行 group by。如果語句為 group by cube(a, b, c),oracle 進行分組的字段分別為 (a, b, c),(a, b),(a, c),(b, c),(a),(b),(c),最後對全表的總計
SQL> select b.dname, a.job, to_char(hiredate, 'yyyy'), sum(sal)
2 from emp a, dept b
3 where a.deptno = b.deptno
4 group by cube(b.dname, a.job, to_char(hiredate, 'yyyy'));
DNAME JOB TO_C SUM(SAL)
-------------- --------- ---- ----------
29025
1980 800
1981 22825
1982 1300
1987 4100
CLERK 4150
CLERK 1980 800
CLERK 1981 950
CLERK 1982 1300
CLERK 1987 1100
ANALYST 6000
ANALYST 1981 3000
ANALYST 1987 3000
MANAGER 8275
MANAGER 1981 8275
SALESMAN 5600
SALESMAN 1981 5600
PRESIDENT 5000
PRESIDENT 1981 5000
SALES 9400
SALES 1981 9400
SALES CLERK 950
SALES CLERK 1981 950
SALES MANAGER 2850
SALES MANAGER 1981 2850
SALES SALESMAN 5600
SALES SALESMAN 1981 5600
RESEARCH 10875
RESEARCH 1980 800
RESEARCH 1981 5975
RESEARCH 1987 4100
RESEARCH CLERK 1900
RESEARCH CLERK 1980 800
RESEARCH CLERK 1987 1100
RESEARCH ANALYST 6000
RESEARCH ANALYST 1981 3000
RESEARCH ANALYST 1987 3000
RESEARCH MANAGER 2975
RESEARCH MANAGER 1981 2975
ACCOUNTING 8750
ACCOUNTING 1981 7450
ACCOUNTING 1982 1300
ACCOUNTING CLERK 1300
ACCOUNTING CLERK 1982 1300
ACCOUNTING MANAGER 2450
ACCOUNTING MANAGER 1981 2450
ACCOUNTING PRESIDENT 5000
ACCOUNTING PRESIDENT 1981 5000
48 rows selected.
SQL> select b.dname, a.job, to_char(hiredate, 'yyyy'), sum(sal) 2 from emp a, dept b 3 where a.deptno = b.deptno 4 group by b.dname, cube(a.job, to_char(hiredate, 'yyyy')); DNAME JOB TO_C SUM(SAL) -------------- --------- ---- ---------- SALES 9400 SALES 1981 9400 SALES CLERK 950 SALES CLERK 1981 950 SALES MANAGER 2850 SALES MANAGER 1981 2850 SALES SALESMAN 5600 SALES SALESMAN 1981 5600 RESEARCH 10875 RESEARCH 1980 800 RESEARCH 1981 5975 RESEARCH 1987 4100 RESEARCH CLERK 1900 RESEARCH CLERK 1980 800 RESEARCH CLERK 1987 1100 RESEARCH ANALYST 6000 RESEARCH ANALYST 1981 3000 RESEARCH ANALYST 1987 3000 RESEARCH MANAGER 2975 RESEARCH MANAGER 1981 2975 ACCOUNTING 8750 ACCOUNTING 1981 7450 ACCOUNTING 1982 1300 ACCOUNTING CLERK 1300 ACCOUNTING CLERK 1982 1300 ACCOUNTING MANAGER 2450 ACCOUNTING MANAGER 1981 2450 ACCOUNTING PRESIDENT 5000 ACCOUNTING PRESIDENT 1981 5000 29 rows selected.