索引的使用對於一些龐大的sql語句來說,大多數的調優場景中有種雪中送炭的感覺,如果幾百萬,幾千萬的數據篩查,全表掃描將會是一個極度消耗資源的過程,但是如果走了索引掃描,可能性能會提升成百上千倍。索引的訪問模式有以下幾種,其實有些時候對有些細節還是不太注意。對不同的使用場景可以有一定的針對性,效率也許更高。
可以創建如下的測試表來簡單歸納一些。
SQL> create table a as select object_id,object_name,object_type from dba_objects;
Table created.
SQL> desc a
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
OBJECT_ID NUMBER
OBJECT_NAME VARCHAR2(128)
OBJECT_TYPE VARCHAR2(19)
SQL> analyze table a compute statistics;
Table analyzed.
SQL> create unique index ind_a on a(object_id); --我們創建了唯一性索引
Index created.
SQL> set autot traceonly exp
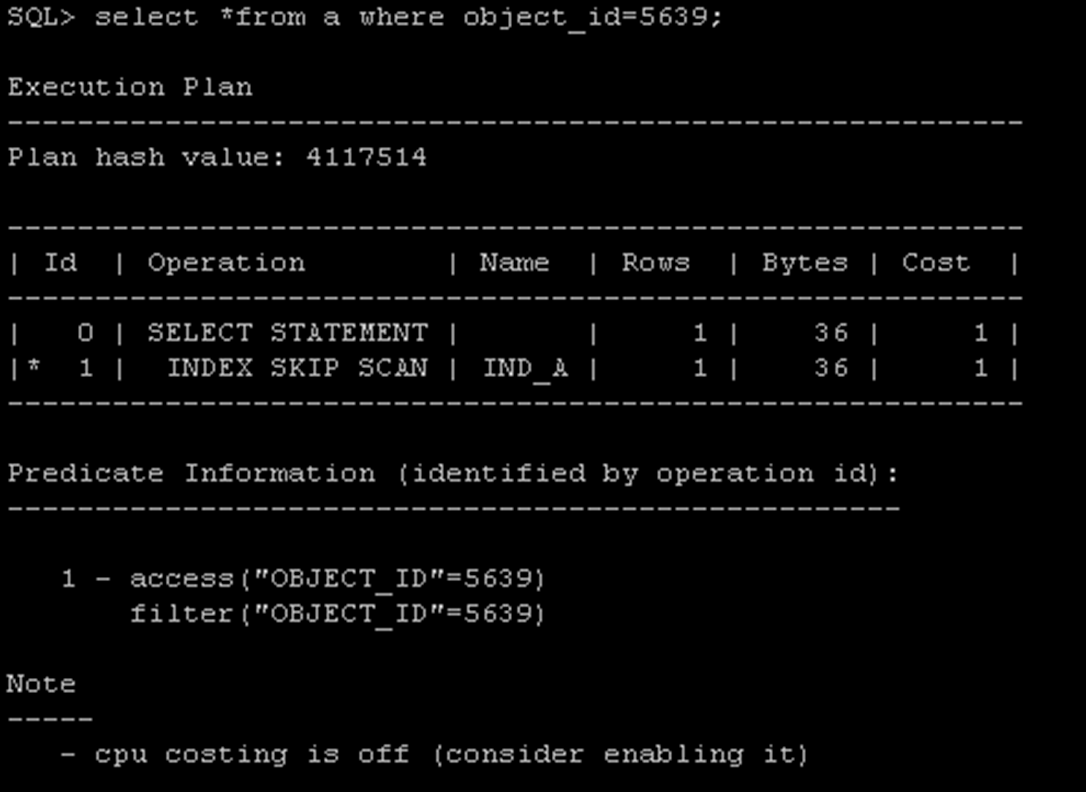
查看執行計劃,使用了index uniqe scan,這種方式是最快的索引訪問模式。
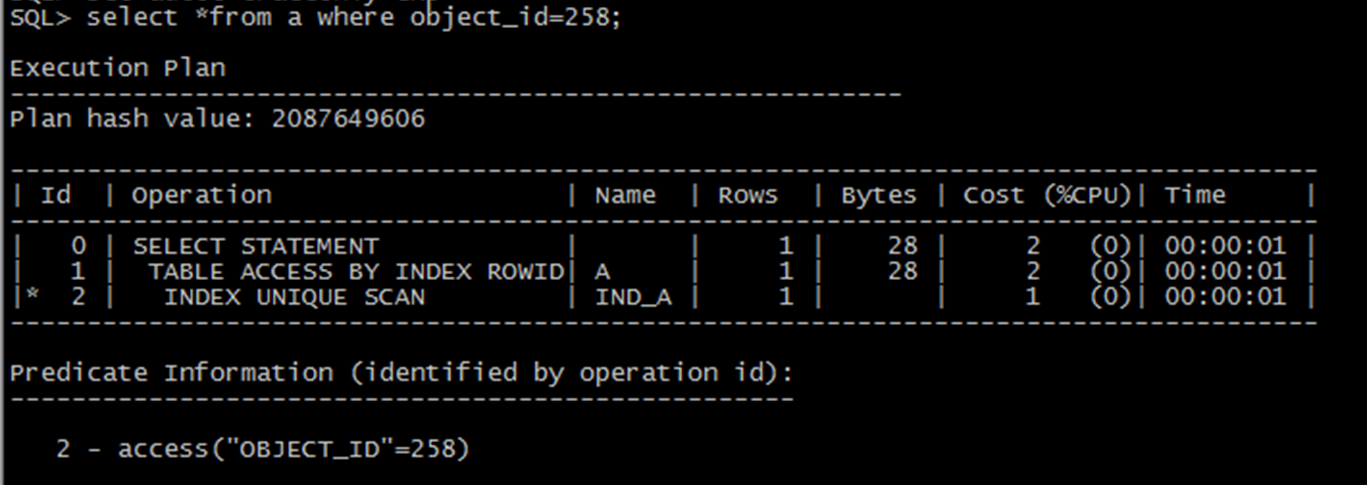
我們只輸出索引列的值,結果預想可以走索引掃描,但是結果走了全表掃描,來看看為什麼。
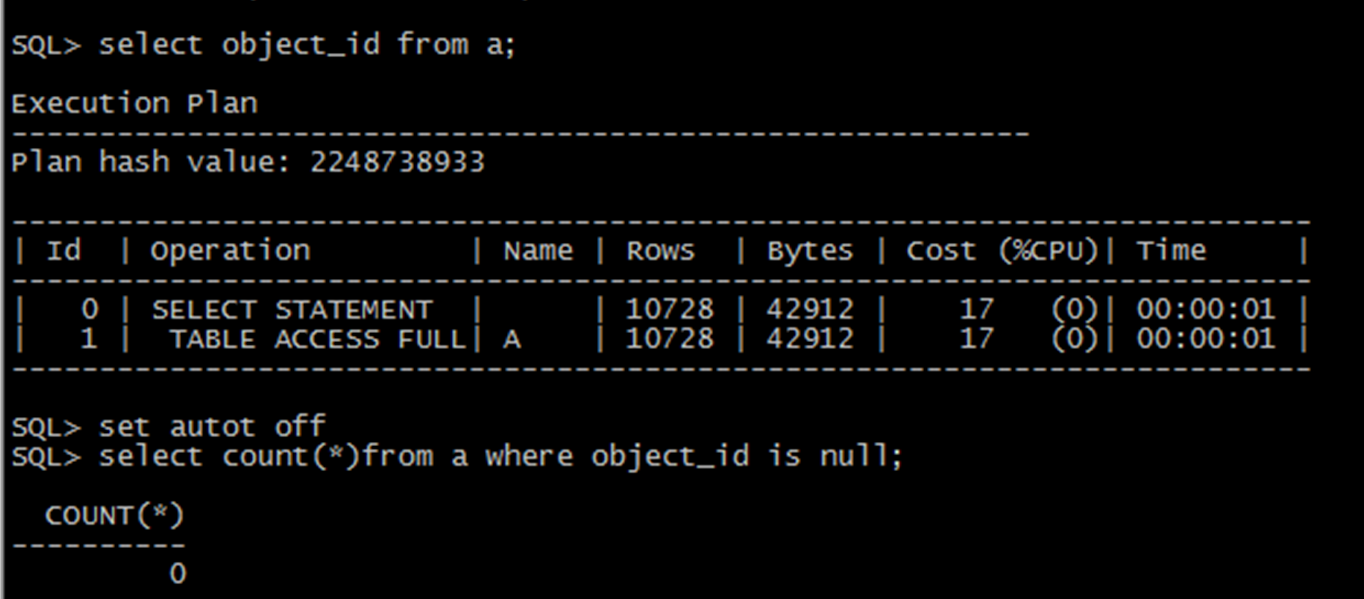
我們只需要簡單的修改一些列的屬性,就可以排除null的干擾,走索引掃描,這個時候走的是快速索引全掃描。這種索引掃描因為不會涉及到排序,所以掃描要快一些。
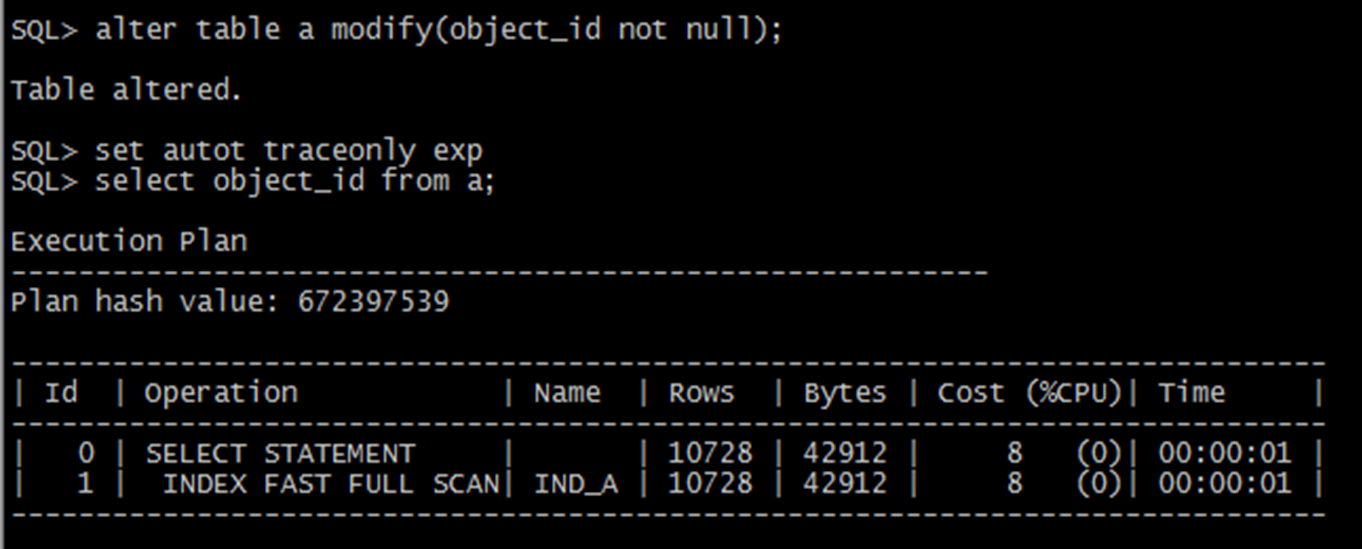
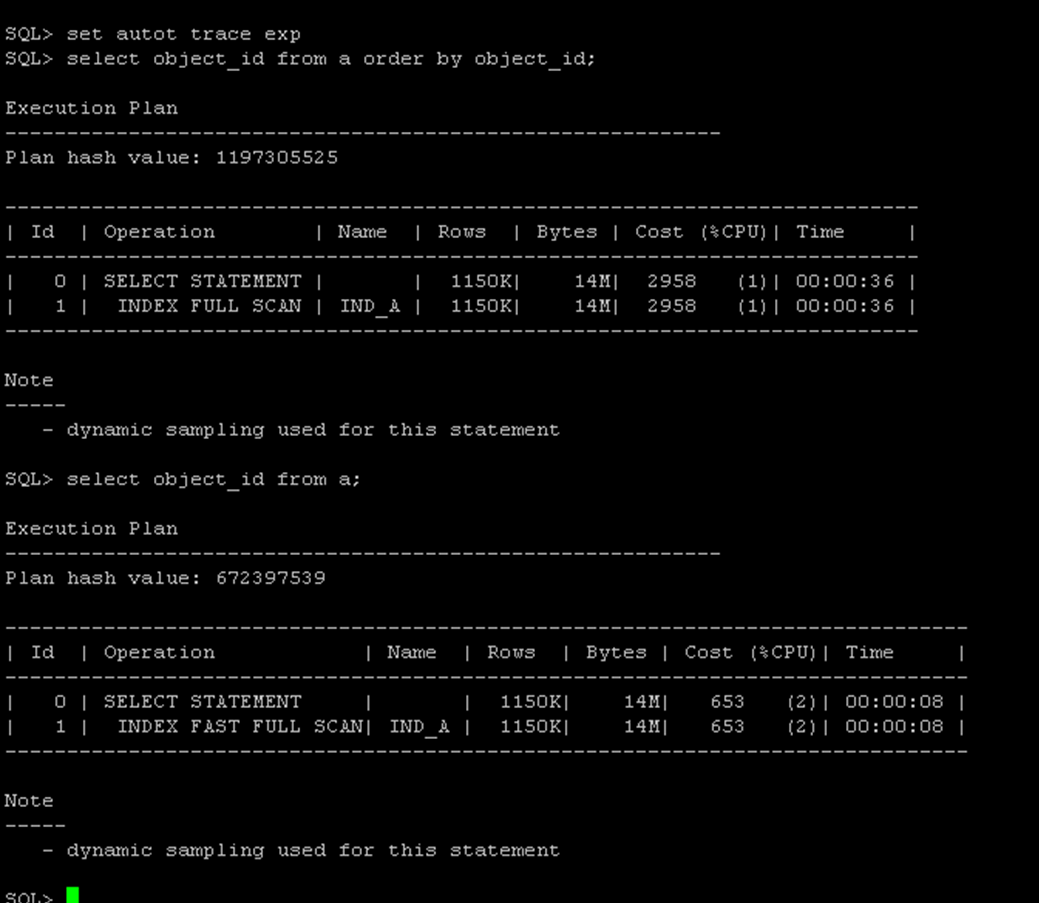
如果要對索引列作排序,這個時候可以使用索引全掃描,通過下面的執行計劃可以看到快速掃描和全掃描的差別。
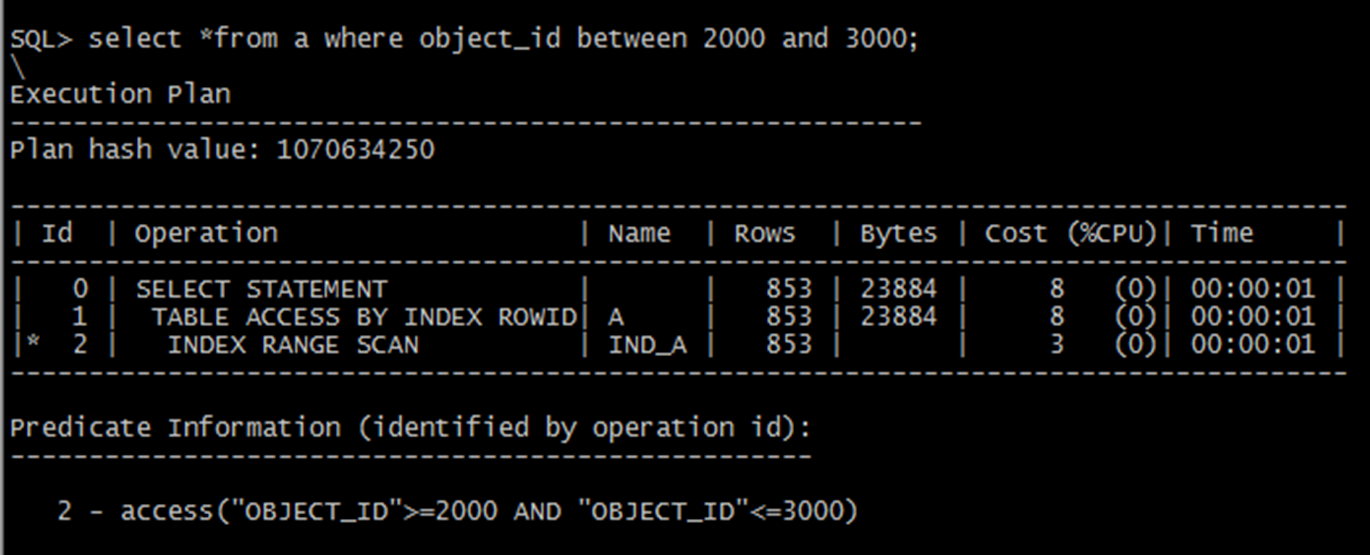
如果涉及到索引列的區間值,可以使用區間掃描,比如我們常用的between條件就會走區間掃描。
對於跳躍索引掃描,可能會略微難懂一些。
可以舉一個簡單的例子來模擬一下。我們創建一個表a,然後讓一些字段的數據分布傾斜。
SQL> drop index ind_a;
Index dropped.
SQL> create index ind_a on a(object_type,object_id,object_name);
Index created.
SQL> analyze table a compute statistics for all indexed columns;
Table analyzed.
SQL> select object_id from a where object_type='INDEX PARTITION' and rownum<2; --我們隨便抽取出一條記錄來做測試。Object_id為5639
OBJECT_ID
----------
5639
可以看到數據的分布情況如下。
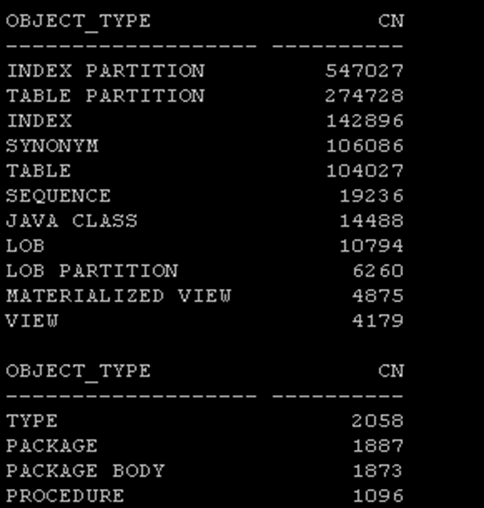
這個時候使用object_id來做查詢,就會走跳躍索引掃描。盡管索引列是(object_type,object_id,object_name),但是通過object_id能夠篩查出很小比例的數據。