操作環境:AIX +11g+PLSQL
包含以下內容:
1. SQL語句執行過程
2. 優化器及執行計劃
3. 合理應用Hints
4. 索引及應用實例
5. 其他優化技術及應用
1)語法分析,分析語句的語法是否符合規范,衡量語句中各表達式的意義。
2)語義分析,檢查語句中涉及的所有數據庫對象是否存在,且用戶有相應的權限。
3)視圖轉換,將涉及視圖的查詢語句轉換為相應的對基表查詢語句。
4)表達式轉換, 將復雜的 SQL 表達式轉換為較簡單的等效連接表達式。
5)選擇優化器,不同的優化器一般產生不同的“執行計劃”
6)選擇連接方式, ORACLE 主要有三種連接方式,對多表連接ORACLE會選擇適當的連接方式。
7)選擇連接順序, 對多表連接 ORACLE 選擇哪一對表先連接,選擇這兩表中哪張表做為基礎數據表。
8)選擇數據的搜索路徑,根據以上條件選擇合適的數據搜索路徑,比如,是選用全表搜索還是利用索引或是其他的方式。
9)運行“執行計劃”
我們可以通過如下語句來查詢緩存中的執行計劃:
SELECT t1.*,
't2-->',
t2.*
FROM v$sql_plan t1
JOIN v$sql t2
ON t1.address = t2.address
AND t1.hash_value = t2.hash_value
AND t1.child_number = t2.child_number;--緩存中的執行計劃。
1)from子句組裝來自不同數據源的數據;
2)where子句基於指定的條件對記錄行進行篩選;
3)group by子句將數據劃分為多個分組;
4)使用聚集函數進行計算;
5)使用having子句篩選分組;
6)計算所有的表達式;
7)計算select的字段;
8)使用order by對結果集進行排序。
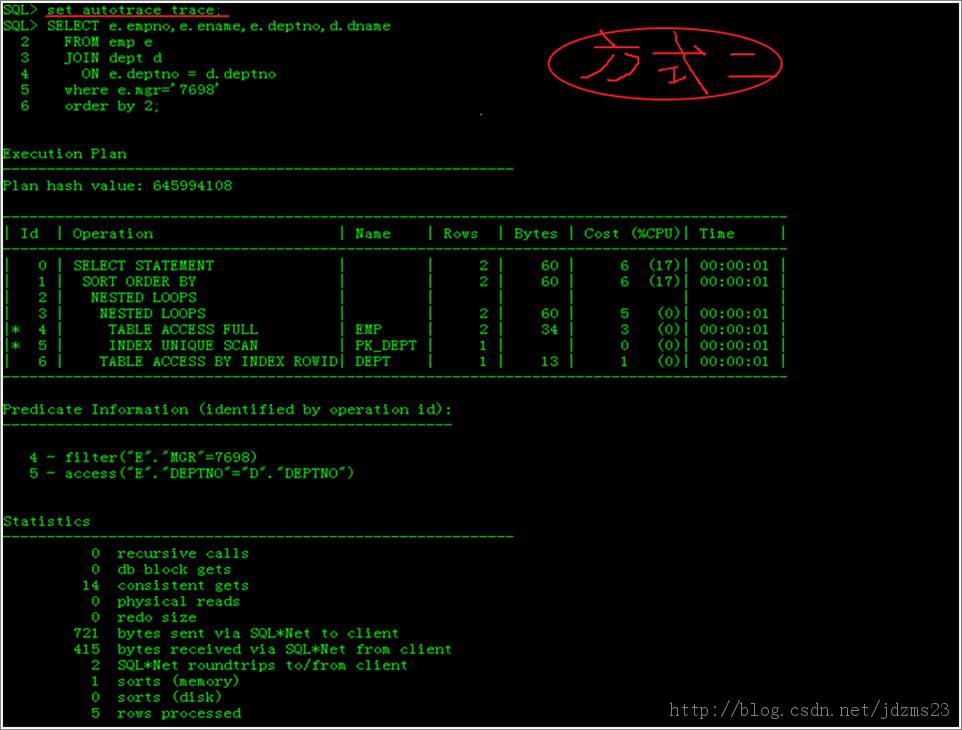
如下圖所示:
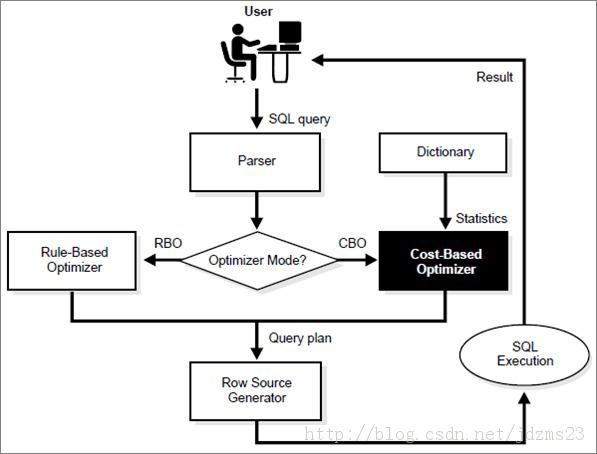
說明:
*這是一張SQL語句執行過程圖
*執行計劃是SQL語句執行過程中必然用到的
*執行計劃是優化器(Optimizer)的產物
*兩種不同的方式:CBO和RBO
查看優化器設置:
方法一:
SELECT VALUE FROM v$parameter t WHERE t.name = 'optimizer_mode';方法二(SQLPLUS下執行):
showparameter optimizer_mode
*CBO用到了字典中的Statistics,而RBO沒有
分析統計信息相關SQL:
analyze table tablename compute statistics;
analyze table tablename compute statistics for all indexes
analyze table tablename delete statistics
關於執行計劃的一些知識:
* Full Table Scans 全表掃描 * Rowid Scans rowid掃描 * Index Scans 索引掃描 * Index Unique Scans * Index Range Scans * Index Range Scans Descending * Index Skip Scans * Full Scans * Fast Full Index Scans(CBO) * Index Joins * Bitmap Joins * Cluster Scans 簇掃描 * Hash Scans 散列掃描 * Sample Table Scans 表取樣掃描可以查看參數:
show parameter STATISTICS_LEVEL2問題:CBO執行計劃依賴的statistic不准確(缺失或者太舊),導致在計算執行成本時就會出現偏差,很可能會產生錯誤的執行計劃,怎麼辦呢?
慎用hint,可能會產生嚴重的後果,比如append會產生鎖塊,導致並發資源等待等
Hints的分類: *Hints forOptimization Approaches and Goals(4)
create table t_1(owner varchar2(30),table_name varchar2(30));
create table t_2(owner varchar2(30),table_name varchar2(30));
insert into t_1 SELECT owner,table_name FROM dba_tables;
insert into t_2 SELECT owner,view_name FROM dba_views t;
create index idx_t_1 on t_1(table_name);
create index idx_t_2 on t_2(table_name);
analyze table t_1 compute statistics;
analyze table t_2 compute statistics;
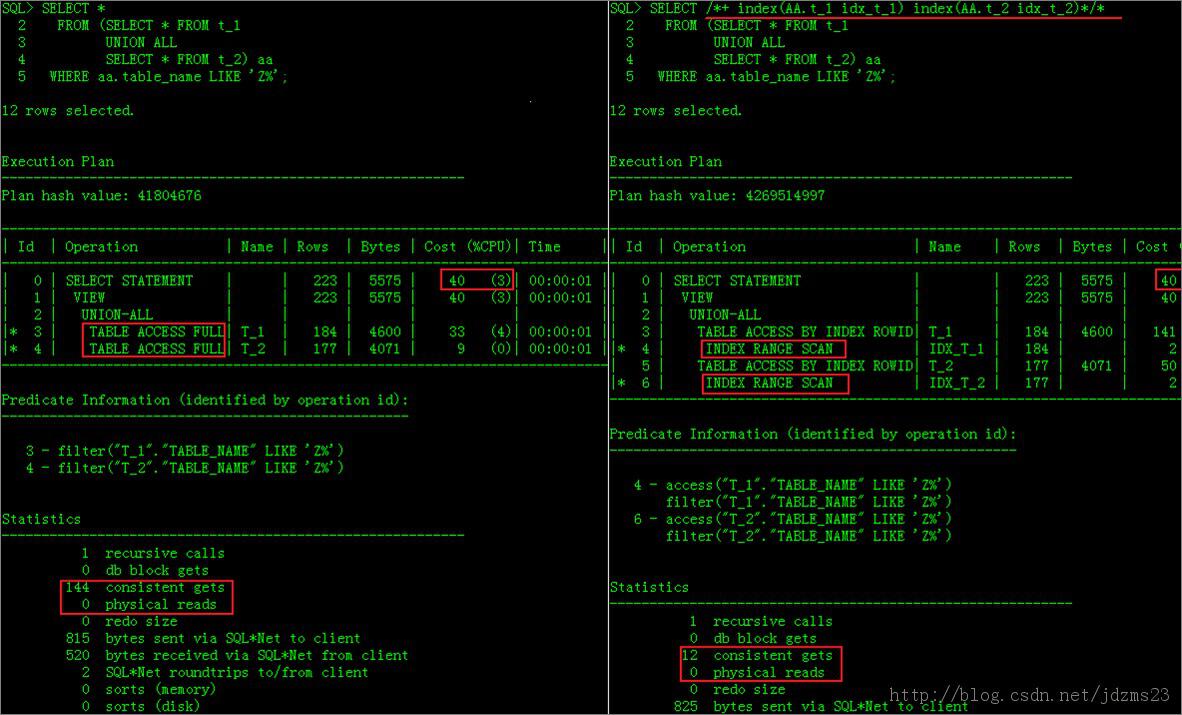
SELECT *
FROM (SELECT * FROM t_1
UNION ALL
SELECT * FROM t_2) aa
WHERE aa.table_name LIKE 'Z%'; ---- Full Table Scans
SELECT /*+ index(AA.t_1 idx_t_1) index(AA.t_2 idx_t_2)*/ *
FROM (SELECT * FROM t_1
UNION ALL
SELECT * FROM t_2) AA
WHERE AA.table_name LIKE 'Z%'; ---- Index Scans
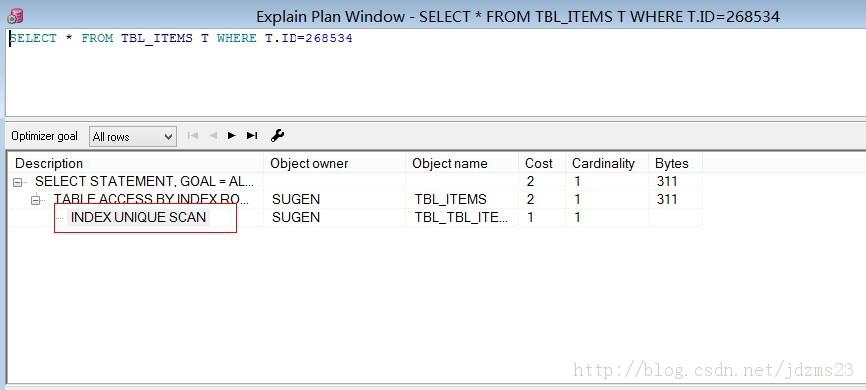
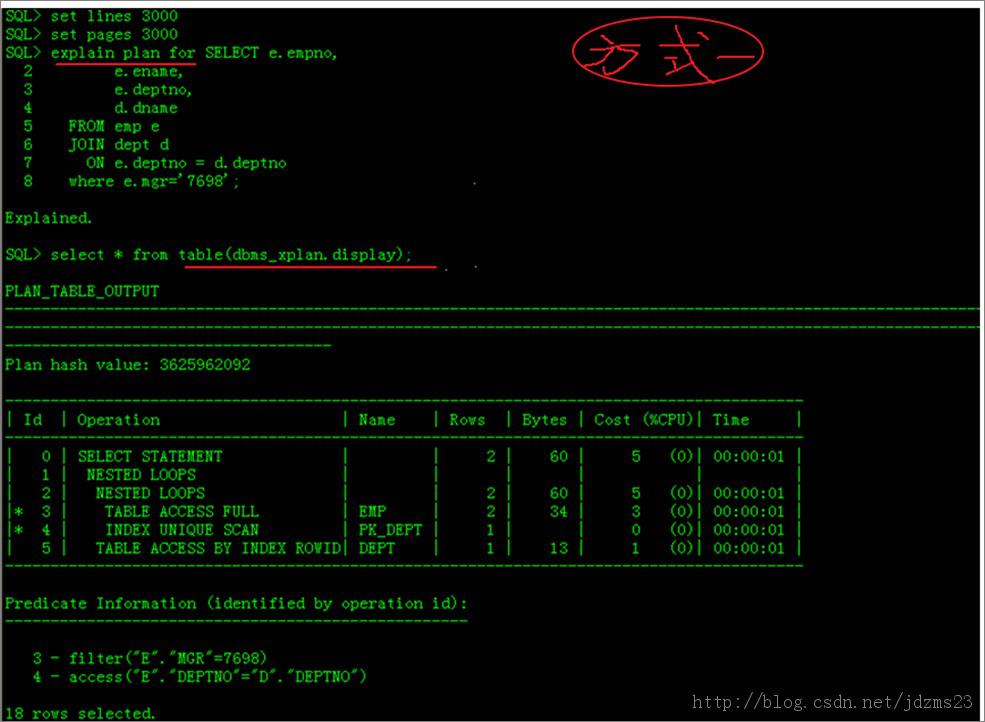
貼上執行圖:
4.索引及應用實例
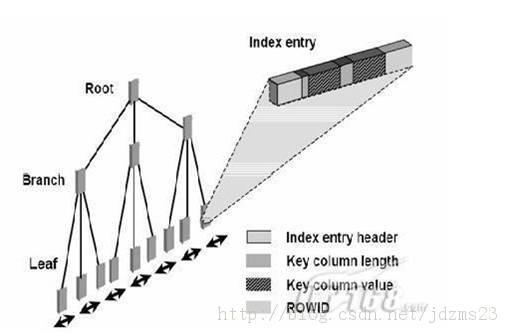
邏輯上:
Single column 單列索引
Concatenated 多列索引
Unique 唯一索引
Non-Unique 非唯一索引
Function-based函數索引
Domain 域索引
*普通索引列 a is not null 按邏輯改為a>0或a>''
*like操作改寫
*能用union all絕不用union,除非要去重
*in操作雖然簡單易懂,但oracle內部會轉換為表連接查詢,使用in會多一步轉換操作,所以建議使用表關聯查詢 *not in 強烈建議使用not exists或(外連接+判斷為空) *<>(不等於)操作不走索引,推薦a<>0改為(a>0 ora<0) a<>’’改為a>’’ *提防隱式類型轉換, oracle內部處理a=0與a=‘0’是完全不同的,甚至會導致不走索引例1.用合適的索引來避免不必要的全表掃
如果要在索引列查詢is not null條件,建議列加上is not null約束,默認值約束,
然而確實由於某種原因索引列設計為null,還想通過is null條件走索引,該如何是好呢?請看
drop table t_tab1;
create table t_tab1 as
SELECT t.owner,
t.object_name,
t.object_type,
t.created,
t.last_ddl_time
FROM dba_objects t;
analyze table t_tab1 compute statistics;
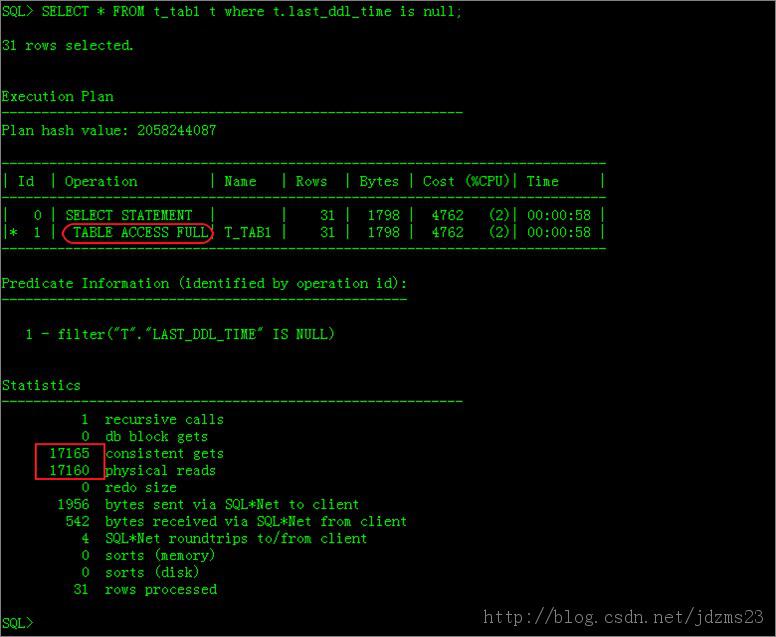
create index idx01_t_tab1 on t_tab1(last_ddl_time);--普通索引
set autotrace trace;
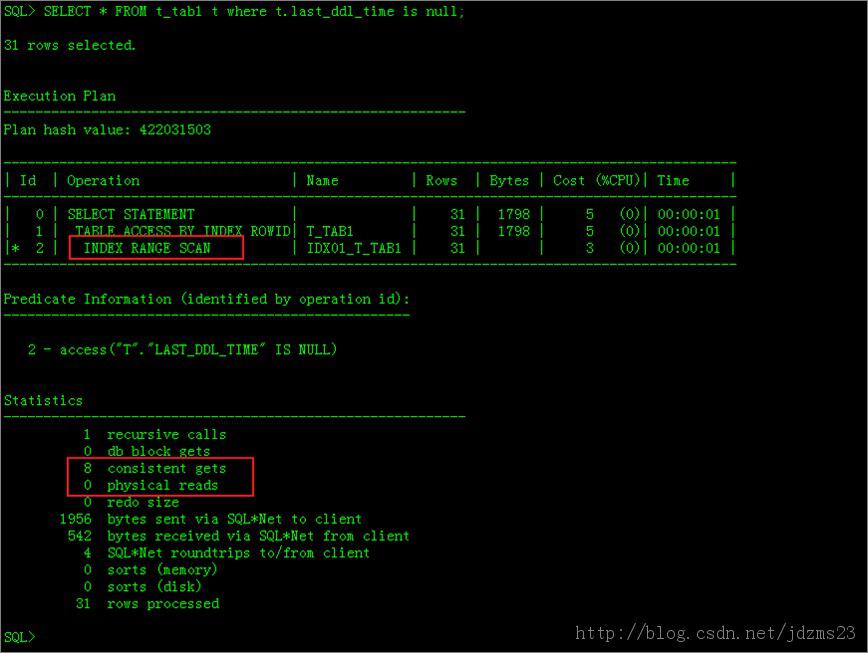
SELECT * FROM t_tab1 t where t.last_ddl_time is null;
執行計劃如下圖:
如上情況調整為復合索引
drop index idx01_t_tab1; create index idx01_t_tab1 on t_tab1(last_ddl_time,1);--加了個常量 set autotrace trace; SELECT * FROM t_tab1 t where t.last_ddl_time is null;執行計劃如下圖:
drop table t_tab1 purge;
create table t_tab1 as
SELECT t.owner,
t.object_name,
t.object_type,
t.OBJECT_ID,
t.created,
t.last_ddl_time
FROM dba_objects t;
CREATE INDEX IDX01_T_TAB1 ON T_TAB1(object_name);
analyze table t_tab1 compute statistics;
set autot trace
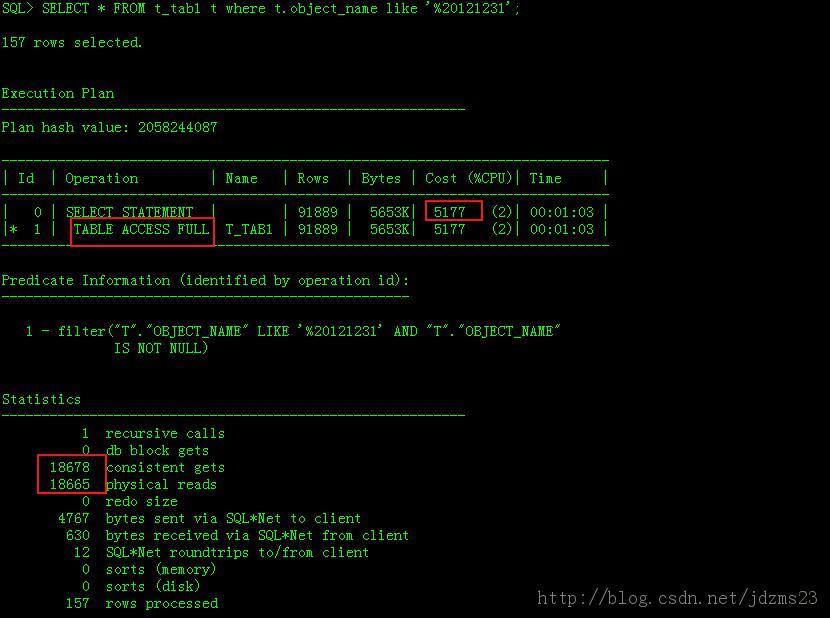
SELECT * FROM t_tab1 t where t.object_name like '%20121231';
執行計劃如下:
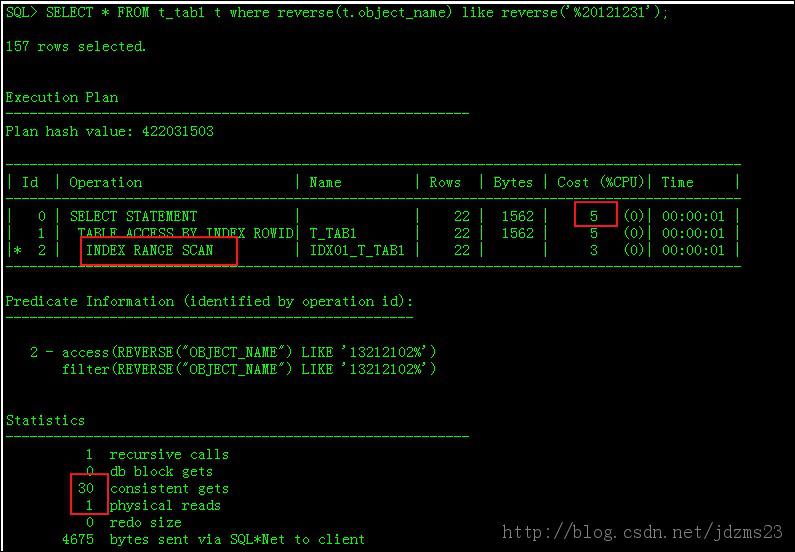
改進索引,此處使用反轉函數索引,此外經常用到的函數索引還有,instr(),substr()等
drop index IDX01_T_TAB1;
CREATE INDEX IDX02_T_TAB1 ON T_TAB1(reverse(object_name));
analyze table t_tab1 compute statistics;
SELECT * FROM t_tab1 t where reverse(t.object_name) like reverse('%20121231');
執行計劃如下:
並行技術,並行執行目標SQL語句,這實際上是以額外的資源消耗來換取執行時間的縮短,很多情況下使用並行是針對某些SQL的唯一優化手段。
使用shell調度或其他調度工具。
SQL語句級別的並行:/*+parallel*/
/*+ parallel(table_name 4)*/
表壓縮技術
compress
NOLOGGING
減少日志
Partition技術
分而治之
中間表/臨時表事務分解思路
‘大事化小’
求平衡
CPU,Memory很強大,IO存在瓶頸(最普遍的情況)
使用新特性
insertall 啦 使用listagg()比wm_concat()快大概50倍、row_number()等分析函數
軟硬件資源合理搭配
黔驢技窮,要求加硬件資源? Boss會對你說,找會計去吧,提前給你開工資 ……
SQL的優化的手段是五花八門、不一而足的,包括但不限於如下措施:
*如果是統計信息不准或是因為CBO計算某些SQL的執行路徑(Access Path)的成本所用公式的先天不足而導致的SQL性能問題,