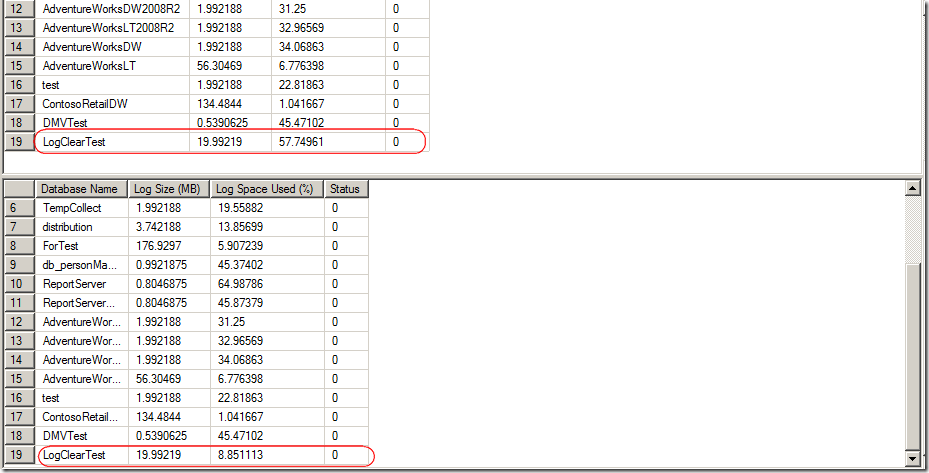
數據庫優化包含以下三部分,數據庫自身的優化,數據庫表優化,程序操作優化.此文為第三部分
概述:程序訪問優化也可以認為是訪問SQL語句的優化,一個好的SQL語句是可以減少非常多的程序性能的,下面列出常用錯誤習慣,並且提出相應的解決方案
一、操作符優化
1. IN、NOT IN 操作符
IN和EXISTS 性能有外表和內表區分的,但是在大數據量的表中推薦用EXISTS 代替IN 。
Not IN 不走索引的是絕對不能用的,可以用NOT EXISTS 代替
2. IS NULL 或IS NOT NULL操作
索引是不索引空值的,所以這樣的操作不能使用索引,可以用其他的辦法處理,例如:數字類型,判斷大於0,字符串類型設置一個默認值,判斷是否等於默認值即可
3. <> 操作符(不等於)
不等於操作符是永遠不會用到索引的,因此對它的處理只會產生全表掃描。 用其它相同功能的操作運算代替,如 a<>0 改為 a>0 or a<0a<>'' 改為 a>''
4. 用全文搜索搜索文本數據,取代like搜索
全文搜索始終優於like搜索:
(1)全文搜索讓你可以實現like不能完成的復雜搜索,如搜索一個單詞或一個短語,搜索一個與另一個單詞或短語相近的單詞或短語,或者是搜索同義詞;
(2)實現全文搜索比實現like搜索更容易(特別是復雜的搜索);
二、SQL語句優化
1、在查詢中不要使用select *
為什麼不能使用,地球人都知道,但是很多人都習慣這樣用,要明白能省就省,而且這樣查詢數據庫不能利用“覆蓋索引”了
2. 盡量寫WHERE子句
盡量不要寫沒有WHERE的SQL語句
3. 注意SELECT INTO後的WHERE子句
因為SELECT INTO把數據插入到臨時表,這個過程會鎖定一些系統表,如果這個WHERE子句返回的數據過多或者速度太慢,會造成系統表長期鎖定,諸塞其他進程。
4.對於聚合查詢,可以用HAVING子句進一步限定返回的行
5. 避免使用臨時表
(1)除非卻有需要,否則應盡量避免使用臨時表,相反,可以使用表變量代替;
(2)大多數時候(99%),表變量駐扎在內存中,因此速度比臨時表更快,臨時表駐扎在TempDb數據庫中,因此臨時表上的操作需要跨數據庫通信,速度自然慢。
6.減少訪問數據庫的次數:
程序設計中最好將一些常用的全局變量表放在內存中或者用其他的方式減少數據庫的訪問次數
7.盡量少做重復的工作
盡量減少無效工作,但是這一點的側重點在客戶端程序,需要注意的如下:
A、 控制同一語句的多次執行,特別是一些基礎數據的多次執行是很多程序員很少注意的
B、減少多次的數據轉換,也許需要數據轉換是設計的問題,但是減少次數是程序員可以做到的。
C、杜絕不必要的子查詢和連接表,子查詢在執行計劃一般解釋成外連接,多余的連接表帶來額外的開銷。
D、合並對同一表同一條件的多次UPDATE,比如
UPDATE EMPLOYEE SET FNAME='HAIWER' WHERE EMP_ID=' VPA30890F'
UPDATE EMPLOYEE SET LNAME='YANG' WHERE EMP_ID=' VPA30890F'
這兩個語句應該合並成以下一個語句
UPDATE EMPLOYEE SET FNAME='HAIWER',LNAME='YANG'
WHERE EMP_ID=' VPA30890F'
E、UPDATE操作不要拆成DELETE操作+INSERT操作的形式,雖然功能相同,但是性能差別是很大的。
F、不要寫一些沒有意義的查詢,比如
SELECT * FROM EMPLOYEE WHERE 1=2
三、where使用原則
1)在下面兩條select語句中:
select * from table1 where field1<=10000 and field1>=0;
select * from table1 where field1>=0 and field1<=10000;
如果數據表中的數據field1都>=0,則第一條select語句要比第二條select語句效率高的多,因為第二條select語句的第一個條件耗費了大量的系統資源。
第一個原則:在where子句中應把最具限制性的條件放在最前面。
2)在下面的select語句中:
select * from tab where a=… and b=… and c=…;
若有索引index(a,b,c),則where子句中字段的順序應和索引中字段順序一致。
第二個原則:where子句中字段的順序應和索引中字段順序一致。
以下假設在field1上有唯一索引I1,在field2上有非唯一索引I2。
3) select field3,field4 from tb where field1='sdf' 快
select * from tb where field1='sdf' 慢,
因為後者在索引掃描後要多一步ROWID表訪問。
select field3,field4 from tb where field1>='sdf' 快
select field3,field4 from tb where field1>'sdf' 慢
因為前者可以迅速定位索引。
select field3,field4 from tb where field2 like 'R%' 快
select field3,field4 from tb where field2 like '%R' 慢,
因為後者不使用索引。
4) 使用函數如:
select field3,field4 from tb where upper(field2)='RMN'不使用索引。
如果一個表有兩萬條記錄,建議不使用函數;如果一個表有五萬條以上記錄,嚴格禁止使用函數!兩萬條記錄以下沒有限制。