聚集索引,數據實際上是按順序存儲的,數據頁就在索引頁上。就好像參考手冊將所有主題按順序編排一樣。一旦找到了所要搜索的數據,就完成了這次搜索,對於非聚集索引,索引是安全獨立於數據本身結構的,在索引中找到了尋找的數據,然後通過指針定位到實際的數據。
SQL Server中的索引使用標准的B-樹來存儲他們的信息,如下圖所示,B-樹通過查找索引中的一個關鍵之來提供對於數據的快速訪問,B-樹以相似的鍵記錄聚合在一起,B不代表二叉(binary),而是代表balanced(平衡的),而B-樹的一個核心作用就是保持樹的平衡。同伙向下遍歷這棵樹以找到一個數值並定位記錄。因為樹是平衡的,所以尋找任何記錄都只需要等量的資源,而且獲取的速度總是一致的—因為從根索引葉索引都具有相同的深度。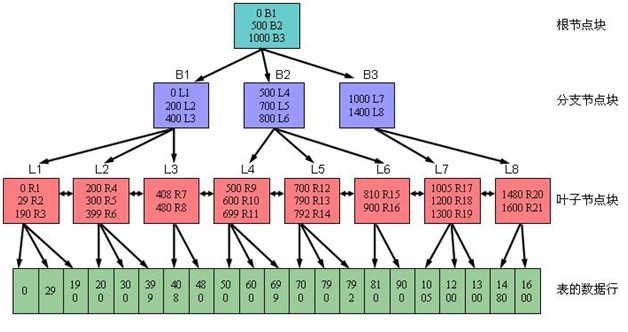
索引的中間層次是根據表的行數一級索引行的大小而變化的,如果使用一個較長的鍵(KEY)來創建索引,一個分頁上就只容納較少的條目,因而索引就需要更多分頁(或者說更多層),頁越多那麼查找就需要話費相對較長的時間來找到所需要的信息,索引就可能不太有用了。
聚集索引
聚集索引的葉級別不僅包含了索引鍵,還包含了數據頁。另一種說法數據本身也是聚集索引的一部分,聚集索引基於鍵值保持表中的數據有序,表中的數據頁是通過一個被稱作頁鏈(page chain)的雙向鏈接表來維護的,由於實際的數據頁的頁鏈只能按一種方式排序,因此一張表只能擁有一個聚集索引。
這裡可能有一個誤區,有很多介紹SQL Server索引的文檔會告訴讀者:聚集索引按照排序順序(sorted order)物理地存儲數據。如果以為物理存儲就是磁盤本身的話就會產生誤解。試想如果聚集索引需要按照特定順序在實際的磁盤上維護數據的話,那麼任何修改操作都將會產生相當高昂的代價。當一個頁變滿了需要一分為二的時候,所有後續頁面上的數據都必須向後移動。聚集索引中的排序順序(sorted order)僅僅表示數據頁鏈在邏輯上是有序的。
大多數表都應該需要一個聚集索引。優化器非常傾向於采用聚集索引,因為聚集索引能夠直接在葉級別找到數據。由於定義了數據的邏輯順序,聚集索引能夠特別快的訪問針對范圍值的查詢,查詢優化器能夠發現只有某一段范圍的數據頁需要掃描。
非聚集索引
對於非聚集索引,葉級別不包含全部的數據。除了鍵值之外,每個葉級別(樹的最底層)中的索引行包含了一個書簽(bookmark),告訴SQL Server可以在那裡找到與索引鍵相應的數據行。一個書簽可能有兩種形式。如果表上存在聚集索引,書簽就是相應的數據行的聚集索引鍵。如果彪是堆(heap)結構,書簽就是一個行表示(row identifier,RID),以“文件號:頁號:槽號”的格式來定位實際的行。
主鍵(PRIMARY KEY)與聚集索引(CLUSTER INDEX)
嚴格來說,主鍵與聚集索引沒有任何關系,如果要說有話,那就是表中沒有聚集索引的時候,創建的主鍵默認就是聚集索引(除非有特別設置為NOCLUSTER)。
在主鍵與聚集索引的處理方面,注意以下事項:
1、主鍵不與聚集索引分離
2、聚集索引鍵列盡量避免使用int之外的數據類型
3、盡量避免使用復合主鍵
創建索引時的注意事項
1、始終包含聚集索引
當表中不包含聚集索引時,表中的數據是無序的,這會降低數據檢索效率。即使通過索引縮小了數據檢索的范圍,但由於數據本身是無序的,當從表中提取實際數據時,會產生頻繁的定位問題,這也使得SQL Server基本上不會使用無聚集索引表中的索引來檢索數據。
2、保證聚集索引唯一
由於聚集索引是非聚集索引的行定位器,如果它不唯一,則會使行定位器中包含輔助數據,同時也導致從表中提取數據時,需要借助行定位器中的輔助數據來定位,這會降低處理效率。
3、保證聚集索引最小
每個聚集鍵值都是所有非聚集索引的葉結點記錄,它越小,意味著每個非聚集索引的索引葉包含的有效數據越多,這對於提升索引效率很有好處。
4、覆蓋索引
覆蓋索引是指索引中的列包含了數據處理中涉及的所有列,覆蓋索引相當原始表的一個子集,由於這個子集中包含了數據處理涉及的所有列,因此操作這個子集就可以滿足數據處理需要。一般而言,如果大多數處理都只涉及某個大表的某些列,可以考慮為這些列建立覆蓋索引。
覆蓋索引的建立方法是將要包含的列中的關鍵列做為索引鍵列,將其他列做為索引的包含列(使用索引創建語句中的INCLUDE子句)。
5、適量的索引
當數據發生變化時,SQL Server會同步維護相關索引中的數據,過多的索引會加影響數據變更的處理效率。因此,只應該在經常使用的列上建立索引。
適量的索引還體現在對索引列的組合方式的控制上。例如,如果有兩個列col1和col2,這兩個列的組合會產生三種使用情況:單獨使用col1、單獨使用col2及同時使用col1和col2。如果有為每種情況都建立索引,則需要建立三個索引。但也可以只建立一個復合索引(col1, col2),這樣能夠依次滿足col1+col2、col1、col2這三種方式的查詢,其中,col2利用這個查詢會比較勉強(還要配合單獨的統計),可以視實際情況確定是否需要為col2建立單獨的索引。
特別注意:
不要建立重復索引,目前最常見的重復索引是單獨為某個列建立主鍵和聚集索引
與直接從表中提取數據相比,根據索引檢索數據,多了一個索引檢索的過程,這個過程要求能夠盡量縮小數據檢索范圍,並且使用最少的時間,這樣才能真正保證能夠通過索引提高數據檢索效率。
實現上述目的,對於索引鍵列的選擇,應該遵循如下原則:
選擇性原則
選擇性是滿足條件的記錄占總記錄數的百分比,這個比率應該盡可能低,這樣才能保證通過索引掃描後,只需要從基礎表提取很少的數據。
如果這個比率偏高,則不應該考慮在此列上建立索引。
數據密度原則
數據密度是指列值唯一的記錄占總記錄數的百分比,這個比率越高,則說明此列越適合建立索引。
在考慮數據密度的時候,還要注意數據分布的問題,只有經常檢索的密度高時,才適合建立索引。例如,如果一張表有10萬記錄,雖然某個列不重復的記錄有9萬條,但如果經常檢索的2萬條記錄,其不重復的列值才幾十條的話,這個列是不太適合建立索引的。另一種情況是,整體數據密度不大,但經常檢索的數據的密度大,例如訂單的狀態,一般來說,訂單的狀態就幾種,但已經Close的訂單往往占整個數據的絕大部分,但數據處理的時候,基本上都是檢索未Close的訂單,這種情況下,為訂單的狀態列建立索引還是比較有效的(SQL Server 2008中,可以為這種列建立具有更佳效果的篩選索引)。
6、索引鍵列大小
一般不宜為超過100Byte的列建立索引。
7、復合索引鍵列順序
在索引中,索引的順序主要由索引中的每一個鍵列確定,因此,對於復合索引,索引中的列順序是很重要的,應該優先把數據密度大,選擇性列,存儲空間小的列放在索引鍵列的前面。