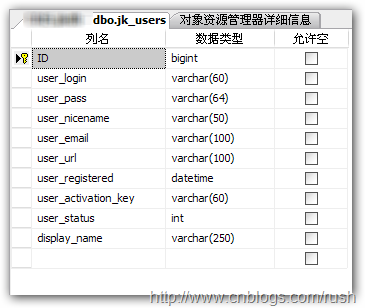
作項目分析,數據庫設計是一個很重要也很難的問題,
完全按照范式有可能不符合用戶需求,不利於編程,
看來是具體問題具體分析,數據庫設計是范式和需求的折中。
在上學時,沒覺得數據類型有多重要,現在發覺了解數據類型
的具體內容也是很重要的,可以知道不同數據庫之間的兼容問題
該怎麼處理。
數據庫設計技巧:
第2 部分— 設計表和字段
1. 檢查各種變化
我在設計數據庫的時候會考慮到哪些數據字段將來可能會發生變更。比方說,姓氏就是如此(注
意是西方人的姓氏,比如女性結婚後從夫姓等)。所以,在建立系統存儲客戶信息時,我傾向於
在單獨的一個數據表裡存儲姓氏字段,而且還附加起始日和終止日等字段,這樣就可以跟蹤這一
數據條目的變化。
— Shropshire Lad
2. 采用有意義的字段名
有一回我參加開發過一個項目,其中有從其他程序員那裡繼承的程序,那個程序員喜歡用屏幕上
顯示數據指示用語命名字段,這也不賴,但不幸的是,她還喜歡用一些奇怪的命名法,其命名采
用了匈牙利命名和控制序號的組合形式,比如cbo1、txt2、txt2_b 等等。
除非你在使用只面向你的縮寫字段名的系統,否則請盡可能地把字段描述的清楚些。當然,也別
做過頭了,比如Customer_Shipping_Address_Street_Line_1 I 雖然很富有說明性,但沒人願意
鍵入這麼長的名字,具體尺度就在你的把握中。
— Lamont Adams
3. 采用前綴命名
如果多個表裡有好多同一類型的字段(比如FirstName),你不妨用特定表的前綴(比如
CusLastName)來幫助你標識字段。
— notoriousDOG
時效性數據應包括“最近更新日期/時間”字段。時間標記對查找數據問題的原因、按日期重新處
理/重載數據和清除舊數據特別有用。
— kol
5. 標准化和數據驅動
數據的標准化不僅方便了自己而且也方便了其他人。比方說,假如你的用戶界面要訪問外部數據
源(文件、XML 文檔、其他數據庫等),你不妨把相應的連接和路徑信息存儲在用戶界面支持表
裡。還有,如果用戶界面執行工作流之類的任務(發送郵件、打印信箋、修改記錄狀態等),那
麼產生工作流的數據也可以存放在數據庫裡。預先安排總需要付出努力,但如果這些過程采用數
據驅動而非硬編碼的方式,那麼策略變更和維護都會方便得多。事實上,如果過程是數據驅動
的,你就可以把相當大的責任推給用戶,由用戶來維護自己的工作流過程。
— tduvall
6. 標准化不能過頭
對那些不熟悉標准化一詞(normalization )的人而言,標准化可以保證表內的字段都是最基礎的
要素,而這一措施有助於消除數據庫中的數據冗余。標准化有好幾種形式,但Third Normal
Form(3NF)通常被認為在性能、擴展性和數據完整性方面達到了最好平衡。簡單來說,3NF 規
定:
· 表內的每一個值都只能被表達一次。
· 表內的每一行都應該被唯一的標識(有唯一鍵)。
· 表內不應該存儲依賴於其他鍵的非鍵信息。
遵守3NF 標准的數據庫具有以下特點:有一組表專門存放通過鍵連接起來的關聯數據。比方說,
某個存放客戶及其有關定單的3NF 數據庫就可能有兩個表:Customer 和Order。Order 表不包
含定單關聯客戶的任何信息,但表內會存放一個鍵值,該鍵指向Customer 表裡包含該客戶信息
的那一行。
更高層次的標准化也有,但更標准是否就一定更好呢?答案是不一定。事實上,對某些項目來
說,甚至就連3NF 都可能給數據庫引入太高的復雜性。
— Lamont Adams
為了效率的緣故,對表不進行標准化有時也是必要的,這樣的例子很多。曾經有個開發財務分析
軟件的活就是用非標准化表把查詢時間從平均40 秒降低到了兩秒左右。雖然我不得不這麼做,
但我絕不把數據表的非標准化當作當然的設計理念。而具體的操作不過是一種派生。所以如果表
出了問題重新產生非標准化的表是完全可能的。
— epepke
7. Microsoft Access 報表技巧
如果你正在使用Microsoft Access,你可以用對用戶友好的字段名來代替編號的名稱:比如用
Customer Name 代替txtCNaM。這樣,當你用向導程序創建表單和報表時,其名字會讓那些不
是程序員的人更容易閱讀。
— jwoodruf
8. 不活躍或者不采用的指示符
增加一個字段表示所在記錄是否在業務中不再活躍挺有用的。不管是客戶、員工還是其他什麼
人,這樣做都能有助於再運行查詢的時候過濾活躍或者不活躍狀態。同時還消除了新用戶在采用
數據時所面臨的一些問題,比如,某些記錄可能不再為他們所用,再刪除的時候可以起到一定的
防范作用。
— theoden
9. 使用角色實體定義屬於某類別的列
在需要對屬於特定類別或者具有特定角色的事物做定義時,可以用角色實體來創建特定的時間關
聯關系,從而可以實現自我文檔化。
這裡的含義不是讓PERSON 實體帶有Title 字段,而是說,為什麼不用PERSON 實體和
PERSON_TYPE 實體來描述人員呢?然後,比方說,當John Smith, Engineer 提升為John
Smith, Director 乃至最後爬到John Smith, CIO 的高位,而所有你要做的不過是改變兩個表
PERSON 和PERSON_TYPE 之間關系的鍵值,同時增加一個日期/時間字段來知道變化是何時
發生的。這樣,你的PERSON_TYPE 表就包含了所有PERSON 的可能類型,比如Associate、
Engineer、Director、CIO 或者CEO 等。
還有個替代辦法就是改變PERSON 記錄來反映新頭銜的變化,不過這樣一來在時間上無法跟蹤
個人所處位置的具體時間。
— teburlew
10. 采用常用實體命名機構數據
組織數據的最簡單辦法就是采用常用名字,比如:PERSON、ORGANIZATION、ADDRESS 和
PHONE 等等。當你把這些常用的一般名字組合起來或者創建特定的相應副實體時,你就得到了
自己用的特殊版本。開始的時候采用一般術語的主要原因在於所有的具體用戶都能對抽象事物具
體化。
有了這些抽象表示,你就可以在第2 級標識中采用自己的特殊名稱,比如,PERSON 可能是
Employee、Spouse、Patient、Client、Customer、Vendor 或者Teacher 等。同樣的,
ORGANIZATION 也可能是MyCompany、MyDepartment、Competitor、Hospital、
Warehouse、Government 等。最後ADDRESS 可以具體為Site、Location、Home、Work、
Client、Vendor、Corporate 和FieldOffice 等。
采用一般抽象術語來標識“事物”的類別可以讓你在關聯數據以滿足業務要求方面獲得巨大的靈
活性,同時這樣做還可以顯著降低數據存儲所需的冗余量。
— teburlew
11. 用戶來自世界各地
在設計用到網絡或者具有其他國際特性的數據庫時,一定要記住大多數國家都有不同的字段格
式,比如郵政編碼等,有些國家,比如新西蘭就沒有郵政編碼一說。
— billh
12. 數據重復需要采用分立的數據表
如果你發現自己在重復輸入數據,請創建新表和新的關系。
— Alan Rash
13. 每個表中都應該添加的3 個有用的字段
· dRecordCreationDate,在VB 下默認是Now(),而在SQL Server 下默認為GETDATE()
· sRecordCreator,在SQL Server 下默認為NOT NULL DEFAULT USER
· nRecordVersion,記錄的版本標記;有助於准確說明記錄中出現null 數據或者丟失數據的原
因
— Peter Ritchie
14. 對地址和電話采用多個字段
描述街道地址就短短一行記錄是不夠的。Address_Line1、Address_Line2 和Address_Line3 可
以提供更大的靈活性。還有,電話號碼和郵件地址最好擁有自己的數據表,其間具有自身的類型
和標記類別。
— dwnerd
過分標准化可要小心,這樣做可能會導致性能上出現問題。雖然地址和電話表分離通常可以達到
最佳狀態,但是如果需要經常訪問這類信息,或許在其父表中存放“首選”信息(比如
Customer 等)更為妥當些。非標准化和加速訪問之間的妥協是有一定意義的。
— dhattrem
15. 使用多個名稱字段
我覺得很吃驚,許多人在數據庫裡就給name 留一個字段。我覺得只有剛入門的開發人員才會這
麼做,但實際上網上這種做法非常普遍。我建議應該把姓氏和名字當作兩個字段來處理,然後在
查詢的時候再把他們組合起來。
— klempan
Klempan 不是唯一一個注意到使用單個name 字段的人,要把這種情況變得對用戶更為友好有好
些方法。我最常用的是在同一表中創建一個計算列,通過它可以自動地連接標准化後的字段,這
樣數據變動的時候它也跟著變。不過,這樣做在采用建模軟件時得很機靈才行。總之,采用連接
字段的方式可以有效的隔離用戶應用和開發人員界面。
— damon
16. 提防大小寫混用的對象名和特殊字符
過去最令我惱火的事情之一就是數據庫裡有大小寫混用的對象名,比如CustomerData。這一問
題從Access 到Oracle 數據庫都存在。我不喜歡采用這種大小寫混用的對象命名方法,結果還不
得不手工修改名字。想想看,這種數據庫/應用程序能混到采用更強大數據庫的那一天嗎?采用全
部大寫而且包含下劃符的名字具有更好的可讀性(CUSTOMER_DATA),絕對不要在對象名的
字符之間留空格。
— bfren
17. 小心保留詞
要保證你的字段名沒有和保留詞、數據庫系統或者常用訪問方法沖突,比如,最近我編寫的一個
ODBC 連接程序裡有個表,其中就用了DESC 作為說明字段名。後果可想而知!DESC 是
DESCENDING 縮寫後的保留詞。表裡的一個SELECT *語句倒是能用,但我得到的卻是一大堆
毫無用處的信息。
— Daniel Jordan
18. 保持字段名和類型的一致性
在命名字段並為其指定數據類型的時候一定要保證一致性。假如字段在某個表中叫做
“agreement_number”,你就別在另一個表裡把名字改成“ref1”。假如數據類型在一個表裡
是整數,那在另一個表裡可就別變成字符型了。記住,你干完自己的活了,其他人還要用你的數
據庫呢。
— setanta
19. 仔細選擇數字類型
在SQL 中使用smallint 和tinyint 類型要特別小心,比如,假如你想看看月銷售總額,你的總額字
段類型是smallint,那麼,如果總額超過了$32,767 你就不能進行計算操作了。
— egermain
20. 刪除標記
在表中包含一個“刪除標記”字段,這樣就可以把行標記為刪除。在關系數據庫裡不要單獨刪除
某一行;最好采用清除數據程序而且要仔細維護索引整體性。
— kol
21. 避免使用觸發器
觸發器的功能通常可以用其他方式實現。在調試程序時觸發器可能成為干擾。假如你確實需要采
用觸發器,你最好集中對它文檔化。
— kol
22. 包含版本機制
建議你在數據庫中引入版本控制機制來確定使用中的數據庫的版本。無論如何你都要實現這一要
求。時間一長,用戶的需求總是會改變的。最終可能會要求修改數據庫結構。雖然你可以通過檢
查新字段或者索引來確定數據庫結構的版本,但我發現把版本信息直接存放到數據庫中不更為方
便嗎?。
— Richard Foster
23. 給文本字段留足余量
ID 類型的文本字段,比如客戶ID 或定單號等等都應該設置得比一般想象更大,因為時間不長你
多半就會因為要添加額外的字符而難堪不已。比方說,假設你的客戶ID 為10 位數長。那你應該
把數據庫表字段的長度設為12 或者13 個字符長。這算浪費空間嗎?是有一點,但也沒你想象的
那麼多:一個字段加長3 個字符在有1 百萬條記錄,再加上一點索引的情況下才不過讓整個數據
庫多占據3MB 的空間。但這額外占據的空間卻無需將來重構整個數據庫就可以實現數據庫規模
的增長了。
— tlundin
24. 列命名技巧
我們發現,假如你給每個表的列名都采用統一的前綴,那麼在編寫SQL 表達式的時候會得到大
大的簡化。這樣做也確實有缺點,比如破壞了自動表連接工具的作用,後者把公共列名同某些數
據庫聯系起來,不過就連這些工具有時不也連接錯誤嘛。舉個簡單的例子,假設有兩個表:
Customer 和Order。Customer 表的前綴是cu_,所以該表內的子段名如下:cu_name_id、
cu_surname、cu_initials 和cu_address 等。Order 表的前綴是or_,所以子段名是:
or_order_id、or_cust_name_id、or_quantity 和or_description 等。
這樣從數據庫中選出全部數據的SQL 語句可以寫成如下所示:
Select * from Customer, Order
Where cu_surname = "MYNAME"
and cu_name_id = or_cust_name_id
and or_quantity = 1;
在沒有這些前綴的情況下則寫成這個樣子:
Select * from Customer, Order
Where Customer.surname = "MYNAME"
and Customer.name_id = Order.cust_name_id
and Order.quantity = 1
第1 個SQL 語句沒少鍵入多少字符。但如果查詢涉及到5 個表乃至更多的列你就知道這個技巧
多有用了。
— Bryce Stenberg
第3 部分— 選擇鍵和索引
1. 數據采掘要預先計劃
我所在的市場部門一度要處理8 萬多份聯系方式,同時填寫每個客戶的必要數據(這絕對不是小
活)。我從中還要確定出一組客戶作為市場目標。當我從最開始設計表和字段的時候,我試圖不
在主索引裡增加太多的字段以便加快數據庫的運行速度。然後我意識到特定的組查詢和信息采掘
既不准確速度也不快。結果只好在主索引中重建而且合並了數據字段。我發現有一個指示計劃相
當關鍵——當我想創建系統類型查找時為什麼要采用號碼作為主索引字段呢?我可以用傳真號碼
進行檢索,但是它幾乎就象系統類型一樣對我來說並不重要。采用後者作為主字段,數據庫更新
後重新索引和檢索就快多了。
— hscovell
可操作數據倉庫(ODS)和數據倉庫(DW)這兩種環境下的數據索引是有差別的。在DW 環境
下,你要考慮銷售部門是如何組織銷售活動的。他們並不是數據庫管理員,但是他們確定表內的
鍵信息。這裡設計人員或者數據庫工作人員應該分析數據庫結構從而確定出性能和正確輸出之間
的最佳條件。
— teburlew
2. 使用系統生成的主鍵
這一天類同技巧1,但我覺得有必要在這裡重復提醒大家。假如你總是在設計數據庫的時候采用
系統生成的鍵作為主鍵,那麼你實際控制了數據庫的索引完整性。這樣,數據庫和非人工機制就
有效地控制了對存儲數據中每一行的訪問。
采用系統生成鍵作為主鍵還有一個優點:當你擁有一致的鍵結構時,找到邏輯缺陷很容易。
— teburlew
3. 分解字段用於索引
為了分離命名字段和包含字段以支持用戶定義的報表,請考慮分解其他字段(甚至主鍵)為其組
成要素以便用戶可以對其進行索引。索引將加快SQL 和報表生成器腳本的執行速度。比方說,
我通常在必須使用SQL LIKE 表達式的情況下創建報表,因為case number 字段無法分解為
year、serial number、case type 和defendant code 等要素。性能也會變壞。假如年度和類型字
段可以分解為索引字段那麼這些報表運行起來就會快多了。
— rdelval
4. 鍵設計4 原則
· 為關聯字段創建外鍵。
· 所有的鍵都必須唯一。
· 避免使用復合鍵。
· 外鍵總是關聯唯一的鍵字段。
— Peter Ritchie
5. 別忘了索引
索引是從數據庫中獲取數據的最高效方式之一。95%的數據庫性能問題都可以采用索引技術得到
解決。作為一條規則,我通常對邏輯主鍵使用唯一的成組索引,對系統鍵(作為存儲過程)采用
唯一的非成組索引,對任何外鍵列采用非成組索引。不過,索引就象是鹽,太多了菜就篌了。你
得考慮數據庫的空間有多大,表如何進行訪問,還有這些訪問是否主要用作讀寫。
— tduvall
大多數數據庫都索引自動創建的主鍵字段,但是可別忘了索引外鍵,它們也是經常使用的鍵,比
如運行查詢顯示主表和所有關聯表的某條記錄就用得上。還有,不要索引memo/note 字段,不
要索引大型字段(有很多字符),這樣作會讓索引占用太多的存儲空間。
— gbrayton
6. 不要索引常用的小型表
不要為小型數據表設置任何鍵,假如它們經常有插入和刪除操作就更別這樣作了。對這些插入和
刪除操作的索引維護可能比掃描表空間消耗更多的時間。
— kbpatel
7. 不要把社會保障號碼(SSN)選作鍵
永遠都不要使用SSN 作為數據庫的鍵。除了隱私原因以外,須知政府越來越趨向於不准許把
SSN 用作除收入相關以外的其他目的,SSN 需要手工輸入。永遠不要使用手工輸入的鍵作為主
鍵,因為一旦你輸入錯誤,你唯一能做的就是刪除整個記錄然後從頭開始。
— teburlew
上個世紀70 年代我還在讀大學的時候,我記得那時SSN 還曾被用做學號,當然盡管這麼做是非
法的。而且人們也都知道這是非法的,但他們已經習慣了。後來,隨著盜取身份犯罪案件的增
加,我現在的大學校園正痛苦地從一大攤子數據中把SSN 刪除。
— generalist
8. 不要用用戶的鍵
在確定采用什麼字段作為表的鍵的時候,可一定要小心用戶將要編輯的字段。通常的情況下不要
選擇用戶可編輯的字段作為鍵。這樣做會迫使你采取以下兩個措施:
· 在創建記錄之後對用戶編輯字段的行為施加限制。假如你這麼做了,你可能會發現你的應用程
序在商務需求突然發生變化,而用戶需要編輯那些不可編輯的字段時缺乏足夠的靈活性。當用
戶在輸入數據之後直到保存記錄才發現系統出了問題他們該怎麼想?刪除重建?假如記錄不可
重建是否讓用戶走開?
· 提出一些檢測和糾正鍵沖突的方法。通常,費點精力也就搞定了,但是從性能上來看這樣做的
代價就比較大了。還有,鍵的糾正可能會迫使你突破你的數據和商業/用戶界面層之間的隔
離。
所以還是重提一句老話:你的設計要適應用戶而不是讓用戶來適應你的設計。
— Lamont Adams
不讓主鍵具有可更新性的原因是在關系模式下,主鍵實現了不同表之間的關聯。比如,
Customer 表有一個主鍵CustomerID,而客戶的定單則存放在另一個表裡。Order 表的主鍵可能
是OrderNo 或者OrderNo、CustomerID 和日期的組合。不管你選擇哪種鍵設置,你都需要在
Order 表中存放CustomerID 來保證你可以給下定單的用戶找到其定單記錄。
假如你在Customer 表裡修改了CustomerID,那麼你必須找出Order 表中的所有相關記錄對其進
行修改。否則,有些定單就會不屬於任何客戶——數據庫的完整性就算完蛋了。
如果索引完整性規則施加到表一級,那麼在不編寫大量代碼和附加刪除記錄的情況下幾乎不可能
改變某一條記錄的鍵和數據庫內所有關聯的記錄。而這一過程往往錯誤叢生所以應該盡量避免。
— ljboast
9. 可選鍵有時可做主鍵
記住,查詢數據的不是機器而是人。
假如你有可選鍵,你可能進一步把它用做主鍵。那樣的話,你就擁有了建立強大索引的能力。這
樣可以阻止使用數據庫的人不得不連接數據庫從而恰當的過濾數據。在嚴格控制域表的數據庫
上,這種負載是比較醒目的。如果可選鍵真正有用,那就是達到了主鍵的水准。
我的看法是,假如你有可選鍵,比如國家表內的state_code,你不要在現有不能變動的唯一鍵上
創建後續的鍵。你要做的無非是創建毫無價值的數據。比如以下的例子:
Select count(*)
from address, state_ref
where
address.state_id = state_ref.state_id
and state_ref.state_code = 'TN'
我的做法是這樣的:
Select count(*)
from address
where
and state_code = 'TN'
如你因為過度使用表的後續鍵建立這種表的關聯,操作負載真得需要考慮一下了。
— Stocker
10. 別忘了外鍵
大多數數據庫索引自動創建的主鍵字段。但別忘了索引外鍵字段,它們在你想查詢主表中的記錄
及其關聯記錄時每次都會用到。還有,不要索引memo/notes 字段而且不要索引大型文本字段
(許多字符),這樣做會讓你的索引占據大量的數據庫空間。。
— gbrayton
第4 部分— 保證數據的完整性
1. 用約束而非商務規則強制數據完整性
如果你按照商務規則來處理需求,那麼你應當檢查商務層次/用戶界面:如果商務規則以後發生變
化,那麼只需要進行更新即可。
假如需求源於維護數據完整性的需要,那麼在數據庫層面上需要施加限制條件。
如果你在數據層確實采用了約束,你要保證有辦法把更新不能通過約束檢查的原因采用用戶理解
的語言通知用戶界面。除非你的字段命名很冗長,否則字段名本身還不夠。— Lamont Adams
只要有可能,請采用數據庫系統實現數據的完整性。這不但包括通過標准化實現的完整性而且還
包括數據的功能性。在寫數據的時候還可以增加觸發器來保證數據的正確性。不要依賴於商務層
保證數據完整性;它不能保證表之間(外鍵)的完整性所以不能強加於其他完整性規則之上。
— Peter Ritchie
2. 分布式數據系統
對分布式系統而言,在你決定是否在各個站點復制所有數據還是把數據保存在一個地方之前應該
估計一下未來5 年或者10 年的數據量。當你把數據傳送到其他站點的時候,最好在數據庫字段
中設置一些標記。在目的站點收到你的數據之後更新你的標記。為了進行這種數據傳輸,請寫下
你自己的批處理或者調度程序以特定時間間隔運行而不要讓用戶在每天的工作後傳輸數據。本地
拷貝你的維護數據,比如計算常數和利息率等,設置版本號保證數據在每個站點都完全一致。
— Suhair TechRepublic
3. 強制指示完整性
沒有好辦法能在有害數據進入數據庫之後消除它,所以你應該在它進入數據庫之前將其剔除。激
活數據庫系統的指示完整性特性。這樣可以保持數據的清潔而能迫使開發人員投入更多的時間處
理錯誤條件。
— kol
4. 關系
如果兩個實體之間存在多對一關系,而且還有可能轉化為多對多關系,那麼你最好一開始就設置
成多對多關系。從現有的多對一關系轉變為多對多關系比一開始就是多對多關系要難得多。
— CS Data Architect
5. 采用視圖
為了在你的數據庫和你的應用程序代碼之間提供另一層抽象,你可以為你的應用程序建立專門的
視圖而不必非要應用程序直接訪問數據表。這樣做還等於在處理數據庫變更時給你提供了更多的
自由。
— Gay Howe
6. 給數據保有和恢復制定計劃
考慮數據保有策略並包含在設計過程中,預先設計你的數據恢復過程。采用可以發布給用戶/開發
人員的數據字典實現方便的數據識別同時保證對數據源文檔化。編寫在線更新來“更新查詢”供
以後萬一數據丟失可以重新處理更新。
— kol
7. 用存儲過程讓系統做重活
解決了許多麻煩來產生一個具有高度完整性的數據庫解決方案之後,我所在的團隊決定封裝一些
關聯表的功能組,提供一整套常規的存儲過程來訪問各組以便加快速度和簡化客戶程序代碼的開
發。在此期間,我們發現3GL 編碼器設置了所有可能的錯誤條件,比如以下所示:
SELECT Cnt = COUNT (*)
FROM [<Table>]
WHERE [<primary key column>] = <new value>
IF Cnt = 0
BEGIN
INSERT INTO [<Table>]
( [< primary key column>] )
VALUES ( <New value> )
END
ELSE
BEGIN
<indicate duplication error>
END
而一個非3GL 編碼器是這樣做的:
INSERT INTO [<Table>]
( [< primary key column>] )
VALUES
( <New value> )
IF @@ERROR = 2627 -- Literal error code for Primary Key Constraint
BEGIN
<indicate duplication error>
END
第2 個程序簡單多了,而且事實上,利用了我們給數據庫的功能。雖然我個人不喜歡使用嵌入文
字(2627)。但是那樣可以很方便地用一點預先處理來代替。數據庫不只是一個存放數據的地
方,它也是簡化編碼之地。
— a-smith
8. 使用查找
控制數據完整性的最佳方式就是限制用戶的選擇。只要有可能都應該提供給用戶一個清晰的價值
列表供其選擇。這樣將減少鍵入代碼的錯誤和誤解同時提供數據的一致性。某些公共數據特別適
合查找:國家代碼、狀態代碼等。
— CS Data Architect
第5 部分— 各種小技巧
1. 文檔、文檔、文檔
對所有的快捷方式、命名規范、限制和函數都要編制文檔。
— nickypendragon
采用給表、列、觸發器等加注釋的數據庫工具。是的,這有點費事,但從長遠來看,這樣做對開
發、支持和跟蹤修改非常有用。
— chardove
取決於你使用的數據庫系統,可能有一些軟件會給你一些供你很快上手的文檔。你可能希望先開
始在說,然後獲得越來越多的細節。或者你可能希望周期性的預排,在輸入新數據同時隨著你的
進展對每一部分細節化。不管你選擇哪種方式,總要對你的數據庫文檔化,或者在數據庫自身的
內部或者單獨建立文檔。這樣,當你過了一年多時間後再回過頭來做第2 個版本,你犯錯的機會
將大大減少。
— mrs_helm
2. 使用常用英語(或者其他任何語言)而不要使用編碼
為什麼我們經常采用編碼(比如9935A 可能是墨水筆的供應代碼,4XF788-Q 可能是帳目編
碼)?理由很多。但是用戶通常都用英語進行思考而不是編碼。工作5 年的會計或許知道
4XF788-Q 是什麼東西,但新來的可就不一定了。在創建下拉菜單、列表、報表時最好按照英語
名排序。假如你需要編碼,那你可以在編碼旁附上用戶知道的英語。
— amasa
3. 保存常用信息
讓一個表專門存放一般數據庫信息非常有用。我常在這個表裡存放數據庫當前版本、最近檢查/修
復(對Access)、關聯設計文檔的名稱、客戶等信息。這樣可以實現一種簡單機制跟蹤數據
庫,當客戶抱怨他們的數據庫沒有達到希望的要求而與你聯系時,這樣做對非客戶機/服務器環境
特別有用。
— Richard Foster
4. 測試、測試、反復測試
建立或者修訂數據庫之後,必須用用戶新輸入的數據測試數據字段。最重要的是,讓用戶進行測
試並且同用戶一道保證你選擇的數據類型滿足商業要求。測試需要在把新數據庫投入實際服務之
前完成。
— juneebug
5. 檢查設計
在開發期間檢查數據庫設計的常用技術是通過其所支持的應用程序原型檢查數據庫。換句話說,
針對每一種最終表達數據的原型應用,保證你檢查了數據模型並且查看如何取出數據。
— jgootee
6. Access 設計技巧
對復雜的Microsoft Access 數據庫應用程序而言,可以把所有的主表放在一個數據庫文件裡,然
後增加其他數據庫文件和裝載同原有數據庫有關的特殊函數。根據需要用這些函數連接到主文件
中的主表。比如數據輸入、數據QC、統計分析、向管理層或者政府部門提供報表以及各類只讀
查詢等。這一措施簡化了用戶和組權限的分配,而且有利於應用程序函數的分組和劃分,從而在
程序必須修改的時候易於管理。
— Dennis Walden