Sql Server查詢機能優化之弗成小觑的書簽查找引見。本站提示廣大學習愛好者:(Sql Server查詢機能優化之弗成小觑的書簽查找引見)文章只能為提供參考,不一定能成為您想要的結果。以下是Sql Server查詢機能優化之弗成小觑的書簽查找引見正文
小小法式猿SQL Server認知的生長
1.沒卒業或任務沒多久,只曉得稀有據庫、SQL這麼個東東,渾然分不清SQL和Sql Server Oracle、MySql的關系,平日以為SQL就是SQL Server
2.任務好幾年了,也寫過很多SQL,卻渾然不曉得索引為什麼物,只曉得數據庫有索引這麼個器械,分不清集合索引和非集合索引,只曉得查詢慢了建個索引查詢就快了,到頭來索引也建了很多,查詢也確切快了,有時問之:汝建之索引為什麼類型?答曰:。。。
3.終究遭到安慰開端發奮圖強,買書,gg查材料終究曉得本來索引分為集合索引和非集合索引,馬上泣如雨下,嗚呼哀哉,吾終知索引為什麼物也。
4.再進一步進修之亦知集合索引為物理索引、非集合索引為邏輯索引,集合索引為數據的存儲次序,非集合索引是邏輯索引既對集合索引的索引
5.再往後學會了檢查履行籌劃,經由過程查詢籌劃終究對查詢進程有了年夜概懂得,也曉得了集合索引掃描和表掃描沒有效到索引,看到集合索引、索引查找愉快的笑逐顏開,看到RID、鍵查找暗自竊喜,瞧,鍵查找確定就是症結字查找了,用著索引呢,效力確定高,因而每次寫完sql都要不雅看下其履行籌劃,表掃描的干貨一切不要,俺只需索引查找、鍵查找。
6.自負滿滿的過著悠哉的小日子,忽然有一天渺茫了,為嘛俺明明在這個字段上樹立了索引,它她妹的老給我顯示集合索引掃描的,豈非查詢優化器發熱了,現實履行下,發明現實的履行籌劃照樣表掃描,這下完全困惑了,也許是查詢優化器顯示的有成績吧。
7.持續深刻進修終發明,數據庫這潭水太深了,懂得的太單方面了,想一想從猿到人的退化進程吧,恩恩,如今就是一個靈智初開的法式猿,向著巨大的法式員奮勇進步
恩恩,跑題了,進入我們的主題:數據庫的書簽查找
熟悉書簽查找
書簽查找這個詞能夠關於許多開辟人員比擬生疏,許多人都碰到過,然則卻沒惹起足夠的看重以致於一向都疏忽它的存在了
界說:當查詢優化器應用非集合索引停止查找時,假如所選擇的列或查詢前提中的列只部門包括在應用的非集合索引和集合索引中時,就須要一個查找(lookup)來檢索其他字段來知足要求。對一個有聚簇索引的表來講是一個鍵查找(key lookup),對一個堆表來講是一個RID查找(RID lookup),這類查找等於——書簽查找(bookmark lookup)。簡略的說就是當你應用的sql查詢前提和select前往的列沒有完整包括在索引列中時就會產生書簽查找。
書簽查找的主要性
1.書簽查找產生前提:只要在應用非集合索引停止數據查找時才會發生書簽查找,集合索引查找、集合索引掃描和表掃描不會產生書簽查找。
2.書簽查找產生頻率:書簽查找產生頻率異常高,乃至可以說年夜部門查詢都邑產生書簽查找,我們曉得一個表只能樹立一個集合索引,所以我們的查詢更多的會應用非集合索引,非集合索引弗成能籠罩一切的查詢列,所以會常常性發生書簽查找。
3.書簽查找的影響:招致索引掉效的重要緣由之一。書簽查找依據索引的行定位器從表中讀取數據,除索引頁面的邏輯讀取外,還須要數據頁面的邏輯讀取,假如查詢的成果前往數據量較年夜會招致年夜量的邏輯讀或許索引掉效,這也是為何我們檢查查詢籌劃時有時明明在查詢列上樹立了索引,查詢優化器卻仍然應用表掃描的緣由。
4.若何清除書簽查找:
1.應用集合索引查找,集合索引的葉子節點就是數據行自己,是以不存在書簽查找
2.集合索引掃描、表掃描,說白了就是啥索引都不建直接全表掃描,確定不會產生書簽查找,不外效力嗎。。。
3.應用非集合索引的鍵列包括一切查詢或前往的列,這個不靠譜,非集合索引最年夜鍵列數為16,最年夜索引鍵年夜小為900字節,就算你有勇氣在16列上全體樹立索引,那假如表的列數跨越16列了你咋辦,還有索引列長度之和不克不及跨越900字節,所以弗成能讓非集合索引包括一切列,並且索引觸及到得列越多保護索引的開支也就越年夜。
4.應用include,嗯,這是個好東東,索引做到只能包括16列且不克不及跨越900字節,include不受此限制,最多可以包括1023列怎樣也夠你用了,並且對長度也沒無限制你可以為所欲為的包括nvarchar(max)這也的列,固然了text之流就不要斟酌了
5.其它,其它還有神馬呢,這個我也不曉得了,估量應當、能夠、年夜概木有了吧,如有曉得的兄弟可以告知我聲哈
能夠下面說的有點籠統,我們開看看詳細的例子
普通我們的數據庫都邑建上集合索引(普通年夜家愛好建表時有效沒有確定先來個自增ID列當主鍵,這個主鍵SQL Server默許就給你創立成集合索引了),故我們這裡都假定表上曾經樹立了集合索引,不斟酌堆表(就是沒有集合索引的表)
1.起首創立表Users、拔出一些示例數據並樹立集合索引PK_UserID 非集合索引IX_UserName
--懶得的肥兔 --創立表Users
Create table Users
(
UserID int identity,
UserName nvarchar(50),
Age int,
Gender bit,
CreateTime datetime
)
--在UserID列創立集合索引PK_UserID
create unique clustered index PK_UserID on Users(UserID)
--在UserName創立非集合索引IX_UserName
create index IX_UserName on Users(UserName)
--拔出示例數據
insert into Users(UserName,Age,Gender,CreateTime)
select N'Bob',20,1,'2012-5-1'
union all
select N'Jack',23,0,'2012-5-2'
union all
select N'Robert',28,1,'2012-5-3'
union all
select N'Janet',40,0,'2012-5-9'
union all
select N'Michael',22,1,'2012-5-2'
union all
select N'Laura',16,1,'2012-5-1'
union all
select N'Anne',36,1,'2012-5-7'
2.履行以下查詢並檢查查詢籌劃,可以看到第一個SQL履行集合索引掃描,第二個SQL履行集合索引查找都沒有應用到書簽查找
select * from Users
select * from Users where UserID=4

3.比擬以下幾個查詢SQL,不雅察其查詢籌劃,思慮下為何會產生書簽查找
--查詢1:應用索引IX_UserName,選擇列UserID,UserName,查詢前提列為UserName
select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert'
--查詢2:應用索引IX_UserName,選擇列UserID,UserName,Age,查詢前提列為UserName
select UserID,UserName,Age from Users with(index(IX_UserName)) where UserName='Robert'
--查詢3:應用索引IX_UserName,選擇列UserID,UserName,查詢前提列為UserName,Age
select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert' and Age=28
--查詢4:應用索引IX_UserName,選擇列一切列,查詢前提列為UserName
select * from Users with(index(IX_UserName)) where UserName='Robert'
剖析:
查詢1:選擇的列UserID是集合索引PK_UserID的鍵列,UserName為索引IX_UserName的鍵列,查詢前提列為UserName,因為索引IX_UserName包括了查詢用到得一切列,所以僅須要掃描索引便可前往查詢成果,不須要再額定的去數據頁獲得數據,故不會產生書簽查找
查詢2:選擇列Age不包括在集合索引PK_UserID和IX_UserName中,故須要停止額定的書簽查找
查詢3:查詢前提Age列不包括在集合索引PK_UserID和IX_UserName中,故須要停止額定的書簽查找
查詢4:包括了一切的列,Age、Gender、CreateTime列均不在集合索引PK_UserID和IX_UserName中,所以須要書簽查找以定位數據
這裡說明下:查詢頂用到的列不管是一列照樣多列不在索引籠罩規模查詢開支根本上一樣,每筆記錄均只須要一次書簽查找開支,不會說由於查詢3只要一個Age列,查詢4有Age、Gender、CreateTime 3列不在索引籠罩規模而招致額定的開支
剖析:
查詢1:選擇的列UserID是集合索引PK_UserID的鍵列,UserName為索引IX_UserName的鍵列,查詢前提列為UserName,因為索引IX_UserName包括了查詢用到得一切列,所以僅須要掃描索引便可前往查詢成果,不須要再額定的去數據頁獲得數據,故不會產生書簽查找
查詢2:選擇列Age不包括在集合索引PK_UserID和IX_UserName中,故須要停止額定的書簽查找
查詢3:查詢前提Age列不包括在集合索引PK_UserID和IX_UserName中,故須要停止額定的書簽查找
查詢4:包括了一切的列,Age、Gender、CreateTime列均不在集合索引PK_UserID和IX_UserName中,所以須要書簽查找以定位數據
這裡說明下:查詢頂用到的列不管是一列照樣多列不在索引籠罩規模查詢開支根本上一樣,每筆記錄均只須要一次書簽查找開支,不會說由於查詢3只要一個Age列,查詢4有Age、Gender、CreateTime 3列不在索引籠罩規模而招致額定的開支
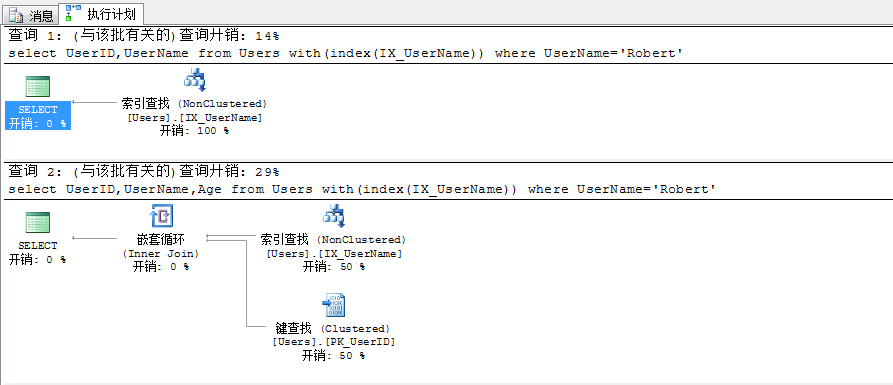

書簽查找是怎樣產生的
和很多人一樣看到年夜神們畫的二叉樹索引構造圖就腦殼年夜,看得雲裡霧裡,所以這裡我們以表Users為例來講集合索引(PK_UserID)和非集合索引(IX_UserName)的構造可以簡略的表現為下圖
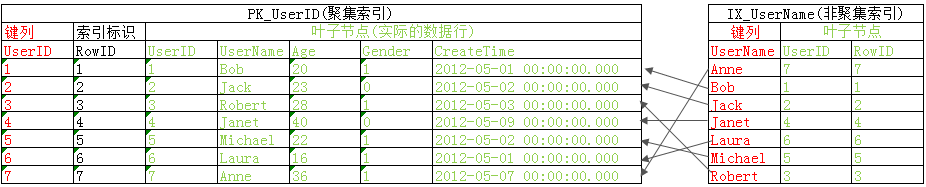
起首我們來看集合索引PK_UserID,關於集合索引來講數據行就是其葉子節點,故當履行集合索引查找時找到了詳細的鍵值後便可以直接去葉子節點獲得一切須要的數據不須要停止額定的邏輯讀,好比select * from Users where UserID=2,依據值2在索引PK_UserID中找到UserID為2的值後去葉子節點便可以拿到所需數據,然後前往查詢成果
然後看非集合索引IX_UserName,下面我們說過非集合索引籠罩的列為非集合索引的鍵列+包括的列+集合索引的鍵列,關於IX_UserName來講就是如圖中所示鍵列UserName保留在索引的二叉樹節點中,集合索引的列包括在其葉子節點中,這也就構成了對列(UserName,UserID)的籠罩,關於查詢1(select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert')來講查詢只用到了UserName,UserID列,如許只須要掃描索引IX_UserName便可拿到一切數據然落後行成果前往,而關於查詢2、查詢3來講因為須要用到Age列,而索引IX_UserName中並沒有包括Age列,這時候就須要個書簽查找(bookmark lookup)依據葉節點中的RowID去定位到詳細的數據行獲得Age列值,關於示例查詢來講先依據索引IX_UserName定位Robert地點行,然後依據RowID=3去數據內外獲得Age值,然後完成查詢,關於查詢4來講須要更多的列(Age,Gender,CreateTime),異樣定位到Robert地點行RowID=3,去數據表一次性拿到Age,Gender,CreateTime數據然後前往,如許就構成了書簽查找(查詢籌劃中顯示為鍵查找或RID查找)
書簽查找的對查詢機能的影響
--這是我們如今應用的索引create index IX_UserName on Users(UserName)
翻開IO統計並履行上面兩個查詢
--set statistics io onselect * from Users where UserName like 'ja%'select * from Users with(index(IX_UserName)) where UserName like 'ja%'
兩個查詢都前往2條數據,集合索引掃描僅僅2次邏輯讀,應用索引IX_UserName卻到達了6次的邏輯讀


我們示例的數據量比擬小,所以感觸感染不顯著,不外我們卻也看到了我們在UserName列上市樹立了索引 IX_UserName,默許情形下查詢優化器並沒有應用我們的索引,而是選擇了表掃描,僅僅須要2次邏輯讀就拿到了我們須要的數據,在我們應用索引提醒強迫查詢優化器應用索引IX_UserName後,異樣也是前往2條數據,邏輯讀缺到達了驚人的6次,看查詢籌劃應用IX_UserName後產生了書簽查找,而這個開支重要是有書簽查找形成的,並且跟著我們前往數據量的增長,由書簽查找招致的邏輯讀將會成直線上升,形成的成果就是查詢開支比停止全表掃描還要年夜的多,終究招致索引掉效
應用籠罩索引防止書簽查找
籠罩索引是指非集合索引上的列(鍵列+包括列) + 集合索引的鍵列包括了查詢頂用到的一切列,關於索引IX_UserName來講索引籠罩列就是(UserName,UserID)。若查詢中只用到了索引所籠罩的列,那末只需掃描索引便可完成查詢,若用到了索引籠罩規模之外的列就須要書簽查找來獲得數據,當這類查找產生次較多時就會招致索引掉效從而招致表掃描,由於查詢優化器是基於開支的優化器,當其發明應用非集合索引激發的書簽查找開支比表掃描開支還年夜時就會廢棄應用索引,轉向表掃描。
1.在UserName,Age列上重建索引IX_UserName,這時候關於索引IX_UserName來講籠罩列變成(UserName,Age,UserID),再次履行下面的查詢SQL可以發明查詢籌劃曾經產生變更
drop index IX_UserName on Userscreate index IX_UserName on Users(UserName,Age)
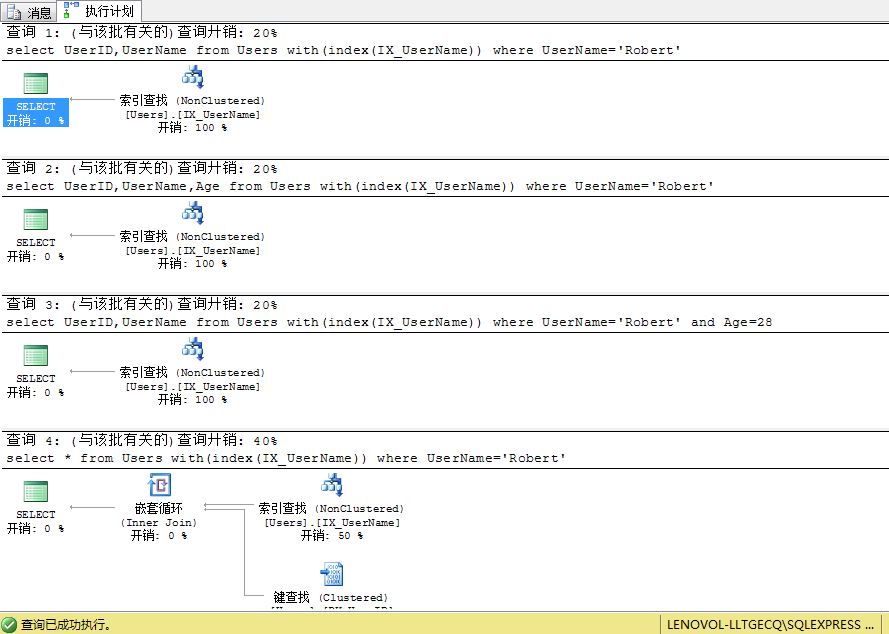
我們可以看到查詢2、查詢3的書簽查找曾經消逝,由於索引IX_UserName包括了查詢頂用到得一切列(UserID,UserName,Age),查詢4由於選擇前往一切列我們的索引沒有包括Gender和CreateTime列,故照樣會停止書簽查找
這時候索引IX_UserName構造表現以下

可見關於查詢2、查詢3僅僅經由過程索引IX_UserName既可以拿到須要的列UserName,Age,UserID,而關於查詢4索引並沒有全體籠罩照樣須要停止書簽查找
2.持續修正我們的索引IX_UserName,應用include包括非鍵列(鍵列就是索引上的列,非鍵列就是索引以外的列,關於include來講就是寄存於非集合索引葉子節點上的列,集合索引的列也放在非集合索引的葉子節點上)
drop index IX_UserName on Userscreate index IX_UserName on Users(UserName,Age) include(Gender,CreateTime)

可以看到我們修正索引應用include包括了Gender,CreateTime後,索引IX_UserName到達了對數據表Users的一切列的全籠罩,這時候候毫無疑問的查詢2、查詢3沒有湧現書簽查找,查詢4的書簽查找也消逝了。
此時索引IX_UserName 構造以下

索引IX_UserName曾經到達了對Users表的全籠罩,關於我們的查詢2、查詢3、查詢4來講,僅經由過程索引IX_UserName便可完成查詢,不須要停止書簽查找。
這時候我們再來看一下這兩個查詢的開支及查詢籌劃,可以看到不須要我們停止索引提醒,查詢優化器曾經主動選擇了我們的索引,邏輯讀也降至了2次
select * from Users where UserName like 'ja%'select * from Users with(index(IX_UserName)) where UserName like 'ja%'
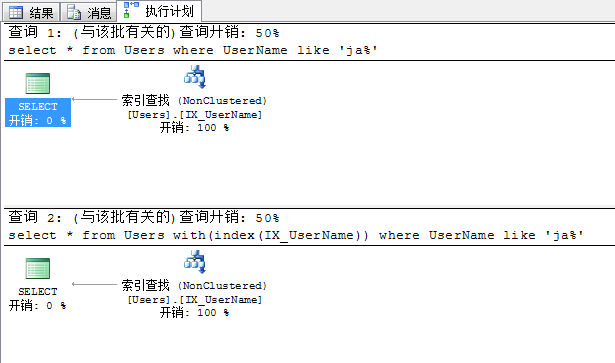

關於Include請參考 SQL Server 索引中include的魅力(具有包括性列的索引)
這裡解釋下書簽查找對查詢機能有著較年夜的影響而且根本上弗成防止,這其實不意味著書簽查找就是禍不單行,本來我們不是也不曉得啥叫書簽查找麼,查詢機能一樣也不差,是吧,呵呵。書簽查找也解釋了為何我們不推舉寫sql時應用select *,也說明了為何有時刻我們的索引會掉效,同時可以作為優化查詢機能斟酌的一個方面,在設計表和索引時盡可能躲避書簽查找帶來的負面影響,好比非集合索引盡可能選擇高選擇性的列即前往盡可能少的行,須要年夜批量數據查詢時盡可能應用集合索引等。
本文中為了便於演示僅僅應用了有幾條數據的表,並且查詢中為了應用索引都用了索引提醒,現實開辟中請不要應用索引提醒,查詢優化器年夜多半情形下會為我們生成最優(最優不代表開支最小,只需開支足夠小即以為最優)的履行籌劃,索引構造外面用到得RowID也僅僅是為了演示虛擬出來的,我們只需以為它是關於數據行的一個標識位就好了。
此文旨在讓我們熟悉書簽查找並認識到書簽查找的意義,從而關於索引掉效緣由有清楚的熟悉,更好的懂得查詢籌劃。