自SQL Server 2014發布後,其新特性之一:內存優化表,一直是人們關注的熱點。內存優化表,顧名思義就是將全部數據存放在內存中的內存表,針對內存優化表的訪問沒有物理IO開銷,事務之間不再通過鎖機制相互隔離,這極大地優化了表的查詢性能。下文我們就來為大家簡單談談內存優化表的原理、實現過程,以及使用內存優化表的注意事項。
一、內存優化表在內存中的數據行存放
內存優化表中的行在內存中並不是以傳統的頁(8KB)為單位存放,而是以行為單位存放的。內存優化表是基於行版本存儲的,同一行在內存中有多個版本,可以將內存優化表的存儲結構看作是該表中所有行的多個行版本的集合。下圖所示為內存優化表中一行的數據結構:

Row header記錄了這一行的事務范圍以及索引指針,Row body記錄了一行的實際數據。每有一個事務操作一行記錄時,就會生成該行記錄的一個新的行版本,此行版本在事務未提交前只有該事務可見,提交之後可以被其他事務訪問。內存優化表就是通過行版本的方式達到事務的高並發和事務之間的相互隔離。如下圖所示:
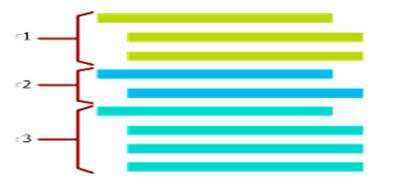
圖中實際上只有3行,第1行有3個行版本,第2行有2個行版本,第3行有4個行版本。
二、內存優化表事務的持久性
既然是內存表,是不是意味著一旦數據庫關閉後,內存表中的所有數據都會丟失呢?關於這個問題,SQL Server提供了兩種解決方案可供選擇:非持久性的內存優化表以及持久性的內存優化表。如果我們在創建內存優化表時,選擇的是非持久性模式,那麼就如上述疑問猜測的一樣,一旦數據庫關閉,內存表中的數據將被清空,若數據庫關閉是由意外導致的,就意味著數據的丟失。當然,有弊也有利,非持久性的內存優化表帶來的性能提升也是最大的。非持久性的內存優化表可用來支撐報表,分析服務等只讀的應用,在每次數據庫重啟後重新填充內存表即可。
如果我們在創建內存優化表的時候選擇的是持續性模式,在執行事務操作時就和操作基於磁盤的表一樣,任何提交的更改都將是一個持久性的變化,不會隨著數據庫的重啟而丟失。那麼內存優化表是如何實現這一事務持久化的過程的呢?下面,我們就來談談內存優化表實現事務持久化的方式——脫機檢查點進程。
脫機檢查點進程是一個異步的數據庫寫進程,和我們熟知的lazy write類似。
和lazy write不同的是,脫機檢查點進程是一個始終做連續寫的進程,這一特點極大地提升了線程的工作效率。
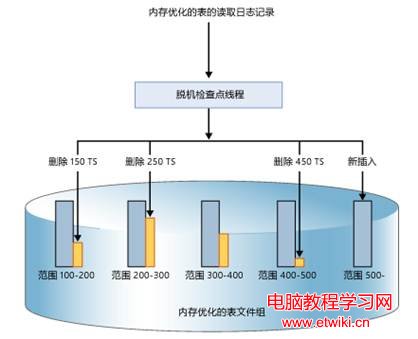
脫機檢查點會讀取事務日志中針對內存數據的操作,並將這些操作異步的寫入到數據文件及差異文件中(內存優化表創建在單獨的一個文件組中,此文件組由多個數據文件及差異文件對構成如上圖所示,藍色為數據文件,黃色為差異文件),針對不同的事務操作,脫機檢查點有不同的處理方法:
Insert操作:所有的插入操作都按照事務的順序連續地寫入到數據文件中,並不區分表。這就意味著一個數據文件中可能有多個表的記錄(如果該數據庫有多張內存優化表的話)。
Update操作:所有的更新操作都是一次刪除操作加一次插入操作。在原記錄所在數據文件對應的差異文件中標記刪除該記錄,然後按照事務的順序,往最新的數據文件中插入更改後的新記錄。
Delete操作:在記錄所在的數據文件對應的差異文件中,標記刪除此記錄。
通過這樣的方式,持久化的操作就變為連續的IO操作,效率得到極大提升。
三、內存優化表的實現步驟
1、創建實驗庫並添加內存表文件組
新建數據庫testdb
添加內存優化文件組
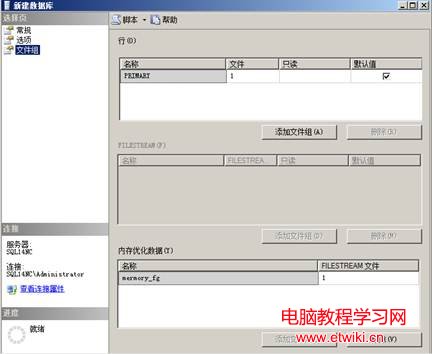
為內存優化文件組添加數據文件(選擇filestream數據)
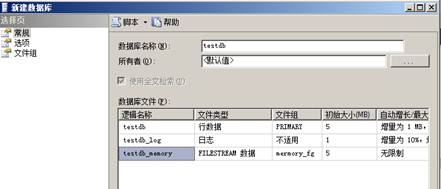
2、新建內存優化表memory_tab

內存優化表支持兩種索引:非聚集索引以及非聚集哈希索引。非聚集哈希索引的bucket_count參數設置最好為表記錄的兩倍左右。Durability = schema_and_data意味著創建的是持久性的內存優化表。
四、使用內存優化表的限制
內存優化表和普通的基於磁盤的表有很大的區別,在帶來性能優化的同時,也有很多的限制:
1. 不支持的數據類型:varchar(max)、nvarchar(max)、image、xml、text、ntext、rowversion、datetimeoffset、geography、geometry、hierarchyid、sql_variant、UDT。
2. 每行的總字節數不得超過 8060 個字節。
3. 不支持外鍵或約束檢查。
4. 支持 IDENTITY(1, 1)。 但是不支持使用 IDENTITY(x, y)(其中 x != 1 或 y != 1 )定義的標識列。
5. 不支持dml觸發器。
6. 內存優化表中的 (var)char 列必須使用代碼頁 1252 排序規則。 此限制不適用於 n(var)char 列。 下列代碼檢索所有 1252 排序規則:
select * from sys.fn_helpcollations() where collationproperty(name, 'codepage') = 1252;
7. 如果數據庫排序規則不是代碼頁 1252 排序規則,則本機編譯的存儲過程不能使用 (var)char 類型的參數、局部變量或字符串常量。
8. 無法修改表結構,只能刪除表再重建。
9. 索引只能建hash非聚焦索引, 不能建聚焦索引。
10. 索引只能在建表時建立,不能重建索引。