一、引言
數據庫是用來保存計算的最終結果的,所以是整個信息系統的最重要組成部分。在許多人看來,當前的數據庫技術已經可以說是非常地成熟了。然而,在滿足不斷增長的聯機事務處理應用方面,當前的數據庫技術其實還存在不少急迫需要解決的技術問題。
對於所有的數據庫而言,除了記錄正確的處理結果之外,它們都面臨著四方面的挑戰:如何提高處理速度,數據可用性、數據安全性和數據集可擴性,也就是說,如何使當前的數據庫具有這四方面的可伸縮性,使客戶能同時得到更高的處理速度、更高的數據可用性、更高的數據安全性和更大的數據集,而不是提升了其中的部分指標,卻損壞了其余的指標或者其余的指標沒有改進。隨著IT應用的深入和有線,無線網絡的快速增長,聯機事務處理業務對以上四方面提出了更高的要求。
將多個數據庫聯在一起組成數據庫集群來達到上述目標應該說是一個很自然的想法。理想的數據庫集群應該可以做到以下幾點:
◆ 在需要更高數據庫處理速度的時候,我們只需簡單增加數據庫服務器就可以了。這樣可以大大減小硬件投資的風險,而且大大提高現有服務的質量。
◆ 在任何時刻需要有多個隨時可用的實時同步數據服務。為了防災,最好有多個異地的同步數據服務。這不光會大大增加數據可用性,還會有意想不到的更高數據庫處理速度的效益。
◆ 除了密碼保護之外,我們最好能控制企業內部對數據庫的非法訪問。
◆ 數據集的可擴性可能是最簡單的要求了。但是,用增加數據庫服務器的辦法來擴大數據集對數據可用性會產生負面影響。如果沒有數據冗余,那麼每增加一台服務器,整個系統的可用性就會成倍地降低。最好的結果是我們能任意增大數據集而沒有對可用性的負面影響。
上述最後一條揭示了我們將面臨的技術困難--除了異常簡單的應用之外,有關數據庫集群的技術都是非常困難和復雜的。更具挑戰性的是,實際的應用要求上述幾方面的指標能同時提升,而不是某一指標提升了,另外的指標卻下降了。然而,所有的技術都是有副作用的,這就是當前數據庫集群技術面臨的重大困難。
客觀地比較各種數據庫技術是很困難的,比較各種數據庫集群技術可見會更困難。本文試圖對當前主要的數據庫集群用到的具體技術進行分析,目的是評價每種技術的優缺點,並且按它們各自的設計目的和使用效益評分, 最後得出每種數據庫集群的一個綜合評價值。從而建立一個客觀評價數據庫集群技術的評價體系。 我們希望能用這個評價標准來評價現有的和今後將出現的數據庫集群技術, 並且理清一些很容易混淆的概念。
為了使得這個研究更具實用價值, 我們還包括了兩項和具體技術沒有直接關系的評價:集群管理難易度和應用的透明度。
評分標准:每一項技術都用從0(不支持)分到1(支持最好)分給出評分,減分是按四分法來做, 所有的效益都大致分為四個梯度,按大約的比例減分。
二、數據庫集群技術的分類
數據庫集群用到的技術很自然地圍繞著上述四方面的挑戰而展開的。所以我們也圍繞著這四個挑戰來展開討論,每個大指標又將分成幾個子指標,每個子指標則對應一種為實現大指標而采用的特定技術。評價標准將給當前六大類數據庫集群技術打分。歡迎讀者來信對我們的評分標准提出質疑。
在開始討論之前,值得指出的是,我們討論的六大類數據庫集群技術分屬兩類體系結構:基於數據庫引擎的集群技術和基於數據庫網關(中間件)的集群技術。
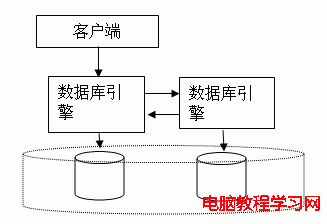
圖 1. 共享磁盤或非共享磁盤的基於數據庫引擎的集群技術
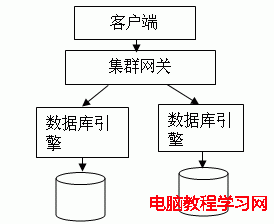
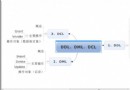
圖 2. 基於數據庫網關(中間件)的集群技術(不共享磁盤)
基於數據庫引擎的集群技術要求數據庫引擎本身具有集群功能(一般只有企業版的數據庫才具有這種功能),而基於數據庫網關(中間件)的集群技術則對數據庫沒有集群能力的要求。所以標准版或企業版都可以用。
在本文中,我們將評估下列數據庫集群技術:
Oracle’s Real Application Cluster (我們將稱之為RAC).
Microsoft SQL Cluster Server (我們將稱之為MSCS).
.IBM’s DB2 UDB High Availability Cluster (我們將稱之為UDB)
Sybase ASE High Availability Cluster (我們將稱之為ASE)
MySQL High Availability Cluster (我們將稱之為MySQL CS).
Parallel Computers Technology Inc.’s ICX-UDS middleware 我們將稱之為ICX).
除了ICX,所有其它的集群技術都是基於數據庫引擎的。所以ICX可以支持任何當前流行的數據庫。
至於其他相關技術,如RAID(廉價冗余磁盤陣列)、磁盤鏡像硬件(EMC的TimeFinder系列)、文件復制工具(如DoubleTake, Veritas and Legato),我們也將做簡單評價和打分。我們會用DM來代表磁盤鏡像 (Data Mirror), FM 代表文件鏡像(File Mirror).
本文只限於討論上述六類數據庫集群系統和上述相關技術。如果有什麼重要技術遺漏的話,歡迎讀者和作者聯系討論。
三、數據庫集群技術
1)提高數據庫處理速度的技術
目前有四種提高數據庫處理速度的辦法:
◆ 提高磁盤速度:這包括RAID和其他磁盤文件分段的處理。主要的思想是提高磁盤的並發度(多個物理磁盤存放同一個文件)。盡管實現方法各不相同,但是它們最後的目的都是提供一個邏輯數據庫的存儲映象。我們要評價的六個系統都能有效地利用這些技術。由於ICX已經有最大的磁盤冗余度,RAID 磁盤系統的設置應該側重於速度,而不是數據冗余。這樣磁盤利用的效益就會提高。
◆ 分散數據的存放:主要思想是利用多個物理服務器來存放數據集的不同部分(一個數據庫表格分散到多個服務器或者每個服務器分管幾個內容不同的表格)。這些辦法不但可以擴展數據集(數據集的可擴性),而且使得不同的服務器進行並行計算成為可能。例如,對於ORACLE的RAC來講,由於它是共享磁盤的體系結構,你只需要簡單地增加一個服務器節點,RAC就能自動地將這節點加入到它的集群服務中去。RAC會自動地將數據分配到這節點上,並且會將接下來的數據庫訪問自動分布到合適的物理服務器上,而不用修改應用程序。對於UDB來講,因為它是非共享磁盤的體系結構,因此就必須手工修改數據的分區,MSCS和ASE也是同樣的情況。MySQL也需要手工分區,並且是這幾種數據庫中支持分區的自動化程度最低的,也就是說,應用程序需要自己負責數據庫的分布式訪問。不管數據存放是如何實現的,分布式存放數據的缺點是對數據庫的可用性有負面影響。任何一台服務器的損壞都會影響整個系統的可用性。但是,這是迄今為止各大數據庫廠商能提供的業界最好的數據庫集群技術了。ICX是一種基於中間件的數據庫集群技術,它對客戶端和數據庫服務器都是透明的。因此,ICX可以用來集群幾個數據庫集群(一個邏輯數據庫),也可以用於集群幾個物理數據庫服務器(來增強一個分管關鍵數據的物理服務器)。
◆ 對稱多處理器系統:此技術的思想是利用多處理機硬件技術來提高數據庫的處理速度。但是,除了ICX,所有其它的數據庫集群技術只支持單一的可修改的邏輯數據庫。絕大部分的數據庫事務處理是磁盤密集型的,純計算負荷很小的,對稱多處器技術在數據庫上的應用的實際收益是很有限的。這也說明了為什麼實際應用中最多只用了四個CPU的原因。所有的基於數據庫引擎的集群都支持這個技術,ICX對SMP技術是中性的,因為它能把多個數據庫服務器集合在一起構成一個集群,也能將多個現存的數據庫集群集合在一起,構成集群的集群。
◆ 交易處理負載均衡:此技術的思想是在保持數據集內容同步的前提下,將只讀操作分布到多個獨立的服務器上運行。因為絕大多數的數據庫操作是浏覽和查詢,,如果我們能擁有多個內容同步的數據庫服務器,交易負載均衡就具有最大的潛力(可以遠遠大於上面敘述的最多達四個處理器的對稱多處理器系統)來提高數據庫的處理速度,同時會具有非常高的數據可用性(真正達到5個9,即99.999%)。所有基於數據庫引擎的集群系統都只支持一個邏輯數據庫映象和一個邏輯或物理的備份。這個備份的主要目的是預防數據災難。因此,備份裡的數據只能通過復制機制來更新,應用程序是不能直接更新它的。利用備份數據進行交易負載均衡只適用於一些非常有限的應用,例如報表統計、數據挖掘以及其它非關鍵業務的應用。只有ICX能夠做到同步復制多個數據庫服務器從而達到在保持數據一直性前提下的真正的負載平衡。
上述所有技術在實際部署系統的時候可以混合使用以達到最佳效果。
2)提高數據庫可用性的技術
根據物理法則,提高冗余度是提高數據庫可用性的唯一途徑。
提高數據庫冗余度大致有四種方法:
◆ 硬件級的冗余:主要思想是讓多處理機同時執行同樣的任務用以屏蔽瞬時和永久的硬件錯誤。有兩種具體的實現方法:。冗余處理機的造價昂貴,效益很低。實際應用日漸減少。基於數據庫的集群系統都是用多個獨立的數據庫服務器來實現一個邏輯數據庫,在任意瞬間,每台處理器運行的都是不同的任務。這種系統可以屏蔽單個或多個服務器的損壞,但是因為沒有處理的冗余度,每次恢復的時間比較長,它們需要把被損壞的服務進程在不同的服務器上從新建立起來。ICX讓多個獨立的數據庫服務器作同樣的處理。發現處理器問題時的切換不需要重建進程的狀態,所以故障屏蔽是極快的。
◆ 通訊鏈路級的冗余:冗余的通訊鏈路可以屏蔽瞬時和永久的通訊鏈路級的錯誤。基於數據庫引擎的集群系統有兩種結構:共享磁盤和獨立磁盤。RAC, MSCS 和 MySQL CS可以認為是共享磁盤的集群系統。UDB和ASE 是獨立磁盤的集群系統。共享磁盤集群系統對網絡系統的要求很高,所以通訊的冗余度最小。獨立磁盤集群系統可以把磁盤系統獨立管理,通訊冗余度較高。 ICX的通訊鏈路級的冗余度最高,因為它使用的是多個獨立的數據庫服務器和獨立的磁盤系統。 ICX也可以用於共享磁盤系統。 但是冗余度會相應降低。
◆ 軟件級的冗余:由於現代操作系統和數據庫引擎的高度並發性,由競爭條件、死鎖、以及時間相關引發的錯誤占據了非正常停機服務的絕大多數原因。采用多個冗余的運行數據庫進程能屏蔽瞬時和永久的軟件錯誤。基於數據庫引擎的集群系統都用多個處理器來實現一個邏輯數據庫,它們只能提供部分軟件冗余,因為每一瞬間每個處理器執行的都是不同的任務。只有ICX可以提供最大程度的軟件級冗余。
◆ 數據冗余:有兩類冗余數據集。
被動更新數據集:所有目前的數據復制技術(同步或異步),例如磁盤鏡像(EMC的TimeFinder系列)、數據庫文件復制(如DoubleTake, Veritas and Legato)以及數據庫廠商自帶的數據庫備份工具都只能產生被動復制數據集。通常,為了實現復制功能,需要消耗掉主服務器5%(異步)到30%(同步)的處理能力。被動更新的數據一般只用於災難恢復.被動更新數據集還有兩個致命的問題:一旦主處理機故障造成數據損壞,被動更新的數據集也會被破壞。另外,和主動更新系統相比,被動更新系統對數據網絡的帶寬要求更高。這是因為它缺少交易的信息,很多數據復制是盲目的。
主動更新數據集:這種數據集需要一台(或多台)獨立的備份數據庫服務器來管理,由於這種數據集及時可用,它可以有多種用途,例如報表生成,數據挖掘,災難恢復甚至低質量負載均衡。 同樣地,這裡也有同步和異步兩種技術。
◆ 異步主動復制數據集:這種技術是先把事務處理交給主服務器來完成,然後這些事務處理再被串行地交給備份服務器以執行同樣的操作來保證數據的一致性。這種技術生成的數據集和主數據集有一個時間差,所以僅適用於災難恢復、數據挖掘、報表統計以及有限的在線應用。所有的商用數據庫都支持異步主動復制技術。這種辦法的難度在於復制隊列的管理上,這個隊列是用來屏蔽主服務器和備份服務器之間的速度差異的。因為主服務器可以盡可能地利用所有軟硬件的並發性來處理並發的事務,而備份服務器只能串行地復制,在高負荷事務處理的情況下,復制隊列經常可能溢出。因為沒有任何辦法來控制事務處理請求的速度,在高負荷事務處理的情況下,復制隊列只能經常性地重建。因為所有現代數據庫系統都支持熱備份和LOG SHIPPING。通過精心策劃,應該可以實現不關閉主服務器而重建隊列。ICX也支持異步主動復制. ICX的復制隊列的重建是通過ICX的自動數據同步軟件來完成的,所以不需要人工操作。
◆ 同步主動復制數據集:這種技術要求所有的並發事務處理在所有的數據庫服務器上同時完成。一個直接的好處就是沒有了隊列的管理問題,同時也可以通過負載均衡實現更高的性能和更高的可用性。這種技術也有兩種完全不同的實現方法:完全串行化和動態串行化。完全串行化的事務處理來自於主數據庫的事務處理引擎,RAC, UDB, MSCS (SQL Server 2005) 和 ASE是用完全串行化並結合兩階段提交協議來實現的,這種設計的目標就是為了獲得一份可用於快速災難恢復的數據集。這種系統有兩個關鍵的問題。第一,兩階段提交協議是一種“ALL OR NOTHING”的協議。仔細研究兩階段提交協議後就能發現,為了獲取這備份數據集,事務處理的可用性會降低一半。第二,完全串行化的做法又引進了主-從數據庫服務器速度不匹配的問題。強制同步造成整個系統的速度被降低到完全串行化的水平。相反,ICX-UDS采用了動態串行復制引擎。這設計可以充分利用多個獨立數據庫的處理能力。ICX避免了使用兩階段提交協議,因此一個事務處理只有在集群中的所有服務器全都同時崩潰的情況下才會回滾。
為了防災,必須使用遠程網絡。 所以我們在這裡討論遠程數據復制的辦法。這裡大概有四種辦法。
◆ 動態遠程異步復制:這種辦法是指主服務器通過遠程網串行地把交易復制到備份服務器上。由於主-副之間的速度不匹配,隊列管理的問題就很突出。 由於遠程網的速度一般都比較慢,隊列溢出的概率大大增加。所有的集群系統都支持這種復制辦法,只是隊列管理的辦法不同而已。DM,FM和RAID都不能支持這種辦法。RAID只能在局域網內工作。
◆ 動態遠程同步復制.:這種辦法是指主服務器通過遠程網並行地把交易復制備份服務器上。只有ICX 具有這種能力。
◆ 靜態遠程異步復制.:這種辦法是指通過遠程網把數據串行地復制(不通過數據庫服務器)到異地。DM和FM支持這種復制辦法。因為串行處理和隊列管理的關系,這對於處理量大的系統不適用。但是這種復制辦法對應用是透明的,所有集群系統都可采用.
◆ 靜態遠程同步復制.:這種辦法也是指通過遠程網把數據串行地復制(不通過數據庫服務器)到異地。不同的是,這裡沒有隊列管理。取代隊列管理的是發送端的一個新的協議:每次發送都要等接受端確認復制成功。否則回滾。DM和FM都支持這種復制辦法。這種辦法只能在短距離范圍內工作, 大約5 英裡光纖的樣子。如果超出這個距離范圍的話,顯然事務處理回滾的概率就會很高。但是這種復制辦法對應用是透明的,所有集群系統都可采用。
3)提高數據庫安全和數據集可擴展的技術
在提高數據庫安全性和數據集可擴性這兩方面,可以創新的空間是很小的。數據庫最常見的安全辦法是口令保護,要麼是分布式的,要麼是集中式的。在數據庫前面增加防火牆會增加額外的延遲,因此,盡管許多安全侵犯事件是來自於公司內部,但是數據庫防火牆還是很少被采用。如果數據庫集群技術是基於中間件技術實現的,就有可能在不增加額外延遲的情況下 ,在數據經過的路徑上實現防火牆功能。ICX完全實現了這種思想。
數據庫數據集的可擴性只能通過將數據分布到多個獨立的物理服務器上來實現。為了彌補可用性的損失,ICX能被用來提高整個邏輯數據庫或者部分重要服務器的處理速度,可用性和安全性。
四、數據庫集群管理
共享磁盤的集群系統,比如RAC, MSCS, 它們的管理比較方便,其中RAC的服務更多。但是,由於它們都要求應用程序對集群不透明,而且配置,修改也比較麻煩,所以我們給它打0.75分。UDB, ASE, MySQL CS 用的都是非共享磁盤,所以管理更麻煩,因此它們只得了0.5分。
和其他系統相比,ICX 的集群配置和管理來得很簡單。但是,由於每台數據庫服務器都有自己的一些系統相關的特有數據,比如進程號,記錄行號,時間戳,等等,在對數據庫引擎和數據進行底層修復的時候需要用到這些數據。所以這些任務需要直接到每台數據庫處理器上去作,比較麻煩。為此,ICX也只得0.75分.
相比較下,RAID, DM和 FM 都很簡單,對集群全是透明的,因此它們都得滿分.
五、應用透明度
這裡RAID, DM 和 FM 也都得滿分,因為它們所應用程序是完全透明的。
因為在錯誤回復和分區方面對應用程序不透明,因此基於數據庫引擎的RAC, MSCS, UDB, ASE和 MySQL CS)在這方面都只得了 0.75分。
ICX 用的是完全獨立的多台數據庫處理器。因為每台服務器都有和自己系統相關的信息,如系統標識、進程號、記錄行號和鎖標識等,如果在業務邏輯裡使用這些信息就會出現問題,因為每台都有自己不同的標識號。基於數據庫引擎的集群技術一般通過一個集群代理來屏蔽這些不同的信息。ICX沒有預設數據庫引擎,用戶需要在這方面做個案評估。
既然使用系統信息將某一應用綁定到了特定的服務器上,這種做法使得自動的錯誤回復變得幾乎不可能進行。所以說,一般而言,在工程上,這樣的做法是很不合理的,絕大多數應用程序是不會存在這樣的問題的。
即使真的有應用程序在業務邏輯裡使用了系統信息,那還是有兩種情況:
a) 可以從客戶端程序裡檢索到系統信息的使用,但是這些系統信息在數據庫表格裡不是作為索引關鍵字使用的。這種應用仍然可以使用ICX的集群技術。
b) 另外的就是不能使用ICX集群技術了,除非去除使用系統有關的信息。
正是因為考慮到了應用程序可能使用了底層的系統信息,導致對集群的不透明性,因此ICX透明性方面才得了0.75分。
六、ICX數據庫集群中間件以及它的應用
ICX的全稱是ICX-UDS DB Scaler。它是專門為能同時取得數據庫高處理速度,高可用性和高安全性而設計的。由於它不受象其它數據庫廠商那樣的基於數據庫引擎的集群技術的限制,ICX作為一種中間件,可以支持任意一種數據庫。
ICX的關鍵之處是它采用了類似通常的代理服務器的方法。這種方法把ICX放置在關鍵的網絡路徑上,這樣ICX就能監聽到所有進出數據庫系統的流量。因此,它就能夠以非常小的代價來提供非常關鍵的服務。這種方法有許多先天的優點,當然這些優點只能在解決了許多重要的技術難點以後才能體現出來。
ICX典型的部署是同時驅動多個(幾乎)一樣的數據庫服務器(和數據集)。
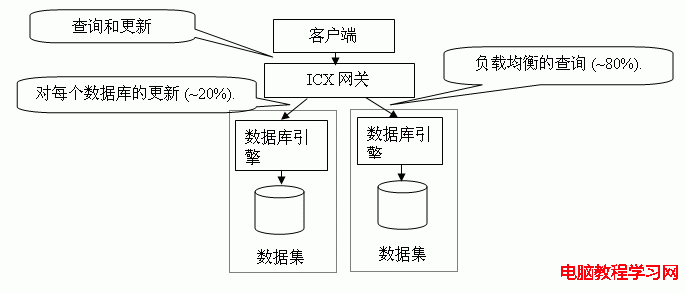
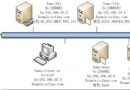
圖 3 帶自動負載均衡和復制功能的最典型的ICX部署
圖 3 顯示了ICX的一個最典型的部署,同時驅動兩個數據庫服務器的數據庫集群。下面是一些前提條件:
◆ 所有服務器運行同一版本的數據庫系統。
◆ 所有的服務器具有完全一樣的數據集,登陸信息,權限信息等。
◆ ICX網關要接管原來賦予給主數據庫的IP地址和端口號,所有的數據庫服務器將重新獲得新的IP地址和端口號
當前的ICX版本ICX-UDS Scaler 3.0可以最多同時掛接16個數據庫(理論上可以掛更多,但是從工程實際來說,掛接16個數據庫已經足夠了)。
在這種結構裡,ICX網關將自動過濾出無狀態(不影響直接數據修改)的查詢訪問,並將它們負載均衡到所有服務器上。在這裡,網關就象一個在線的“編譯器”,它將所有對數據庫的更新操作(和帶狀態的查詢操作)發送到所有數據庫上執行,而將無狀態的查詢操作只發送到其中某一數據庫服務器上。這樣,客戶在數據庫處理速度,可用性和安全性(如果設置了防火牆功能的話)等方面同時得到提高。