簡介
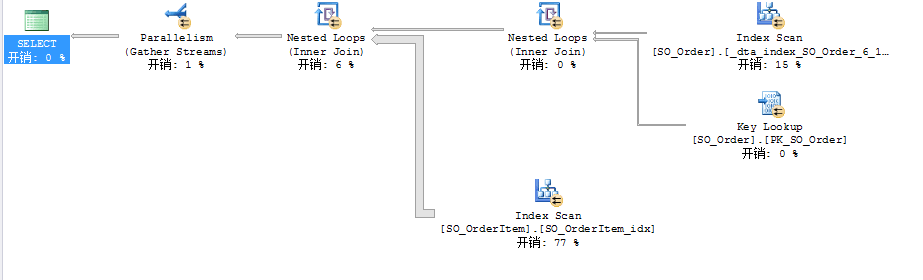
當查詢優化器(Query Optimizer)將T-SQL語句解析後並從執行計劃中選擇最低消耗的執行計劃後,具體的執行就會交由執行引擎(Execution Engine)來進行執行。本文旨在分類講述執行計劃中每一種操作的相關信息。
首先最基本的操作就是訪問數據。這既可以通過直接訪問表,也可以通過訪問索引來進行。表內數據的組織方式分為堆(Heap)和B樹,其中表中沒有建立聚集索引時數據是通過堆進行組織的,這個是無序的,表中建立聚集索引後和非聚集索引的數據都是以B樹方式進行組織,這種方式數據是有序存儲的。通常來說,非聚集索引僅僅包含整個表的部分列,對於過濾索引,還僅僅包含部分行。
除去數據的組織方式不同外,訪問數據也分為兩種方式,掃描(Scan)和查找(Seek),掃描是掃描整個結構的所有數據,而查找只是查找整個結構中的部分數據。因此可以看出,由於堆是無序的,所以不可能在堆上面進行查找(Seek)操作,而相對於B樹的有序,使得在B樹中進行查找成為可能。當針對一個以堆組織的表進行數據訪問時,就會進行堆掃描,如圖1所示。

圖1.表掃描
可以看出,表掃描的圖標很清晰的表明表掃描的性質,在一個無序組織表中從頭到尾掃描一遍。
而對於B樹結構的聚集索引和非聚集索引,同樣可以進行掃描,通常來講,為了獲取索引表中的所有數據或是獲得索引行樹占了數據大多數使得掃描的成本小於查找時,會進行聚集索引掃描。如圖2所示。

圖2.聚集索引掃描
聚集索引掃描的圖標也同樣能夠清晰的表明聚集索引掃描的性質,找到最左邊的葉子節點後,依次掃描所有葉子節點,達到掃描整個結構的作用。當然對於非聚集索引也是同樣的概念,如圖3所示。

圖3.非聚集索引的掃描
而對於僅僅選擇B樹結構中的部分數據,索引查找(Seek)使得B樹變得有意義。根據所查找的關鍵值,可以使得從僅僅從B樹根部向下走單一路徑,因此免去了掃描不必要頁的消耗,圖4是查詢計劃中的一個索引查找。

圖4.聚集索引查找
索引查找的圖標也是很傳神的,可以看到圖標那根線從根節點一路向下到葉子節點。也就是找到所求數據所在的頁,不難看出,如果我們需要查找多條數據且分散在不同的頁中,這個查找操作需要重復執行很多回,當這個次數大到一定程度時,SQL Server會選擇消耗比較低的索引掃描而不是再去重復索引查找。對於非聚集索引查找,概念是一樣的,就不再上圖片了。
書簽查找(Bookmark Lookup)
你也許會想,假如非聚集索引可以快速的找到所求的數據,但遺憾的是,非聚集索引卻不包含所有所求列時該怎麼辦?這時SQL Server會面臨兩個選擇,直接訪問基本表去獲取數據或是在非聚集索引中找到數據後,再去基本表獲得非聚集索引沒有覆蓋到的所求列。這個選擇取決於所估計的行數等統計信息。查詢分析器會選擇消耗比較少的那個。
一個簡單的書簽查找如圖5所示。

圖5.一個簡單的書簽查找