查到有這樣一段話,很耗CPU資源:
set statistics io on
set statistics time on
SELECT TOP 10 FeedBackID,UserID,ContentID,[Content],
Time,AddType,IP FROM CYZoneFeedBack
where contentid in (select articleid from cyzonearticle where userid=@user and delflag=0 and publishtype<>'b')
and CYZoneFeedBack.DelFlag =0 order by CYZoneFeedBack.Time desc
分析是這樣的:
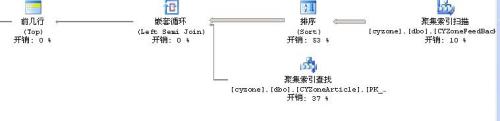
原來是排序造成了這麼多開銷。罪魁禍首在於 order by CYZoneFeedBack.Time 這句話,後改成:
set statistics io on
set statistics time on
SELECT TOP 10 FeedBackID,UserID,ContentID,[Content],
Time,AddType,IP FROM CYZoneFeedBack
where contentid in (select articleid from cyzonearticle where userid=107and delflag=0 and publishtype<>'b')
and CYZoneFeedBack.DelFlag =0 order by CYZoneFeedBack.feedbackid desc
執行計劃變為:
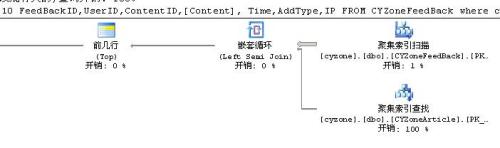
很明顯省掉了排序的操作。有時候,排序和時間是有相關性的,而聚集索引,沒有建在時間上,會導致排序成本的增加,恰當的利用自增ID來做時間排序,也能省掉很多開銷。