數據挖掘是SQL Server 2000中最令人激動的新功能之一。我將數據挖掘看作是一個能夠自動分析數據以獲取相關信息的過程,數據挖掘可以和任一關系數據庫或者OLAP數據源集成使用,但它和OLAP的集成所帶來的好處卻是極為顯著的。因為結構化的數據源使得用戶無需再向數據挖掘算法提供海量信息了。盡管不是什麼專家,但我從同事Greg Bernhardt那裡學到東西已經足夠我來對數據挖掘作一翻解釋了,我還希望由此使得分析服務的數據挖掘功能不再神秘並向你展示如何在分析應用中使用數據挖掘。
數據挖掘功能
數據挖掘彌補了分析服務功能中的重要不足之處。微軟在SQL Server 7.0中引入了針對特定問題的分析和探測性分析功能。在針對特定問題的分析中,分析器要清楚用戶需要回答什麼問題並簡單地利用OALP引擎獲取相關信息。例如,一個快餐店的經理可能想知道:“最近四個季度,漢堡包的營業額和利潤怎麼樣?”
在探測性分析中,分析器可能對用戶的興趣有所了解,但不需要回答具體的問題。例如,一個公司可能知道自己的一些零售商店沒有利潤,但卻不知道原因何在。分析器在一個OLAP多維數據集中通過獲取更多的細節資料,進行多維查找,獲得最感興趣的數據,我們稱這一過程為數據沖浪。
數據挖掘同“針對特定問題”的分析和探測性分析都不相同。通過數據挖掘,分析服務可以浏覽信息,尋找相關數據並提交數據。數據挖掘可以說是探測性分析的理想搭檔。
SQL Server 2000通過新的API━━OLE DB for Data Mining(OLE DB for DM)實現了數據挖掘的功能,這是一個為方便各種應用程序使用數據挖掘功能而設計的編程接口。通過OLE DB for DM, 微軟提供了兩種數據挖掘算法(其它軟件供應商也可以插入新的算法)。理論上,利用OLE DB for DM開發的分析程序能夠使用新發明的算法。
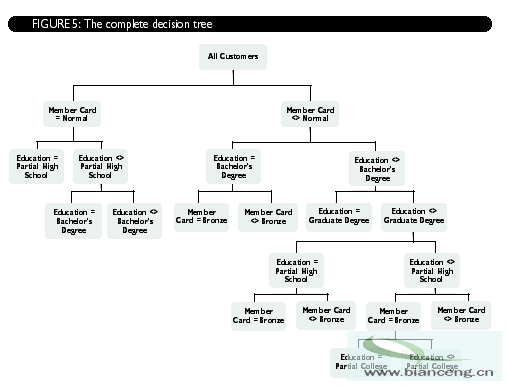
SQL Sever 2000中包含的兩種算法是決策樹和群。決策樹將信息分類為一個樹狀結構,可以幫助我們預測數據的某些特性。例如,可以將用戶信息(如收入、婚姻狀況及受教育程度)交由決策樹算法,對預測該用戶是否具有信用風險提供幫助。可以用群集算法尋找數據中的自然分組。例如,可以將所有的用戶信息送入群集算法,要求把所有客戶分為三個組。算法可能會找到一個已婚、受教育程度較高而收入偏低的分組,一個單身、高收入的分組和一個受教育程度較低而收入較高的分組。通過進一步的分析可能個發現每個分組都有一個特定的購物方式。利用這些資料,我們可以進行高效益、針對性強的廣告活動。注意第二、三分組並沒有完全使用所有的三項輸入的信息,因為對於分組來說,並不是所有的輸入信息都很重要。因此,第二組的描述之所以不包括受教育程度是由於分組不是根據教育水平來劃分的。
使用分析服務
如果進行數據挖掘的對象是OLAP多維數據集而不是關系數據庫,就不能直接使用OLE DB for DM,因為分析服務可以通過自己的編程接口來實現數據挖掘功能。在服務器端,可以通過決策支持對象(Decision Support Objects,DSO)使用數據挖掘功能,而在客戶機端則可以通過OLE DB for OLAP或ActiveX多維數據對象(ADO MD)使用數據挖掘功能。
與群集算法相比,我更喜歡決策樹算法,因為它可以根據決策樹算法進行數據挖掘的結果創建新的“維”,我們可以將這些“維”納入一個新的虛擬多維數據集,還可以用數據挖掘的結果浏覽現有的維。
創建挖掘模型
創建挖掘模型,需要打開分析管理器(Analysis Manager),展開左邊的樹形浏覽窗口,打開FoodMart 2000數據庫。你將看到挖掘模型文件夾(挖掘模型定義了所挖掘的具體數據和根據該信息所做的預測類型。),右擊該文件夾,選擇新挖掘模型(New Mining Model)運行挖掘模型向導。該向導首先要求選擇是在關系型數據還是在多維數據集中進行數據挖掘。選擇Multidimensional後單擊Next按鈕。然後選擇要挖掘的數據集(在本例中選擇Sale數據集)。向導的第三步是選擇數據挖掘算法,選擇Microsoft Decision Trees(微軟的決策樹)後單擊Next按鈕。
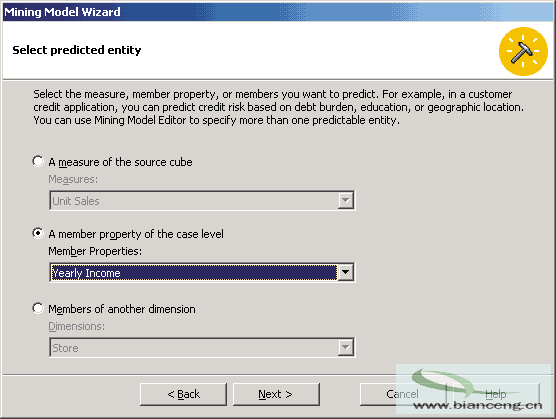
下一步就該選擇數據挖掘容器了(容器是新挖掘多維模型挖掘的數據實體)。選擇Customers維和Name層。下一步,選擇所作預測的類型。假設數據挖掘算法有輸入輸出,本例將用戶的相關信息作為輸入,年收入作為被預測的實體或輸出。年收入是Customer維中Name層的一個成員屬性。依次選擇A member property of the case level(容器層的成員屬性)―> Yearly Income,如圖1 所示。
下一步需要選擇為預測年收入所需要用到的OLAP多維數據集中的那部分數據。選中Customers維、Customers維中所有的層及Name層中Member屬性下的所有層,如圖2所示(這些都是缺省的設置)。需要注意的是,Yearly Income既是輸入也是輸出,這是因為我們正在訓練挖掘模型。為訓練挖掘模型,算法需要正確的答案。(如:現有用戶的實際年收入)
(圖2)
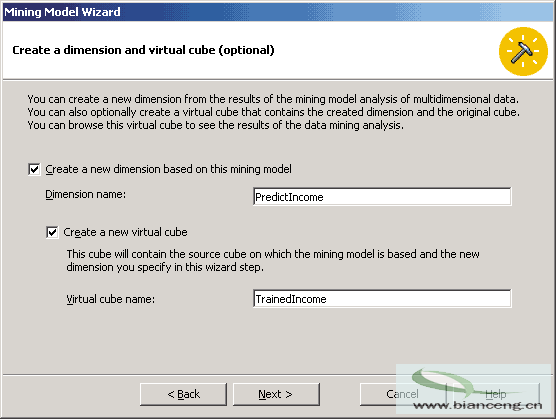
點擊Next按鈕,創建一個OLAP維和一個虛擬多維數據集。對話框設置按圖3所示。挖掘向導模式將根據Sales多維數據集創建一個虛擬多維數據集,增加一個名為PredictIncome的新數據挖掘維, 點擊Next後,為建立挖掘模型起個名字並決定是否立刻執行。我們將建立的挖掘模型命名為IncomModel, 點擊Save按鈕並立刻執行。當點擊Finish按鈕後,分析服務將對數據進行處理,並在挖掘模型編輯器中顯示挖掘的結果。