如果你的數據庫中某一個表中的數據滿足以下幾個條件,那麼你就要考慮創建分區表了。
1、數據庫中某個表中的數據很多。很多是什麼概念?一萬條?兩萬條?還是十萬條、一百萬條?這個,我覺得是仁者見仁、智者見智的問題。當然數據表中的數據多到查詢時明顯感覺到數據很慢了,那麼,你就可以考慮使用分區表了。如果非要我說一個數值的話,我認為是100萬條。
2、但是,數據多了並不是創建分區表的惟一條件,哪怕你有一千萬條記錄,但是這一千萬條記錄都是常用的記錄,那麼最好也不要使用分區表,說不定會得不償失。只有你的數據是分段的數據,那麼才要考慮到是否需要使用分區表。
3、什麼叫數據是分段的?這個說法雖然很不專業,但很好理解。比如說,你的數據是以年為分隔的,對於今年的數據而言,你常進行的操作是添加、修改、刪除和查詢,而對於往年的數據而言,你幾乎不需要操作,或者你的操作往往只限於查詢,那麼恭喜你,你可以使用分區表。換名話說,你對數據的操作往往只涉及到一部分數據而不是所有數據的話,那麼你就可以考慮什麼分區表了。
那麼,什麼是分區表呢?
簡單一點說,分區表就是將一個大表分成若干個小表。假設,你有一個銷售記錄表,記錄著每個每個商場的銷售情況,那麼你就可以把這個銷售記錄表按時間分成幾個小表,例如說5個小表吧。2009年以前的記錄使用一個表,2010年的記錄使用一個表,2011年的記錄使用一個表,2012年的記錄使用一個表,2012年以後的記錄使用一個表。那麼,你想查詢哪個年份的記錄,就可以去相對應的表裡查詢,由於每個表中的記錄數少了,查詢起來時間自然也會減少。
但將一個大表分成幾個小表的處理方式,會給程序員增加編程上的難度。以添加記錄為例,以上5個表是獨立的5個表,在不同時間添加記錄的時候,程序員要使用不同的SQL語句,例如在2011年添加記錄時,程序員要將記錄添加到2011年那個表裡;在2012年添加記錄時,程序員要將記錄添加到2012年的那個表裡。這樣,程序員的工作量會增加,出錯的可能性也會增加。
使用分區表就可以很好的解決以上問題。分區表可以從物理上將一個大表分成幾個小表,但是從邏輯上來看,還是一個大表。
接著上面的例子,分區表可以將一個銷售記錄表分成五個物理上的小表,但是對於程序員而言,他所面對的依然是一個大表,無論是2010年添加記錄還是2012年添加記錄,對於程序員而言是不需要考慮的,他只要將記錄插入到銷售記錄表——這個邏輯中的大表裡就行了。SQL Server會自動地將它放在它應該呆在的那個物理上的小表裡。
同樣,對於查詢而言,程序員也只需要設置好查詢條件,OK,SQL Server會自動將去相應的表裡查詢,不用管太多事了。
這一切是不是很誘人?
的確,那麼我們就可以開始動手創建分區表了。
第一、創建分區表的第一步,先創建數據庫文件組,但這一步可以省略,因為你可以直接使用PRIMARY文件。但我個人認為,為了方便管理,還是可以先創建幾個文件組,這樣可以將不同的小表放在不同的文件組裡,既便於理解又可以提高運行速度。創建文件組的方法很簡單,打開SQL Server Management Studio,找到分區表所在數據庫,右鍵單擊,在彈出的菜單裡選擇“屬性”。然後選擇“文件組”選項,再單擊下面的“添加”按鈕,如下圖所示:
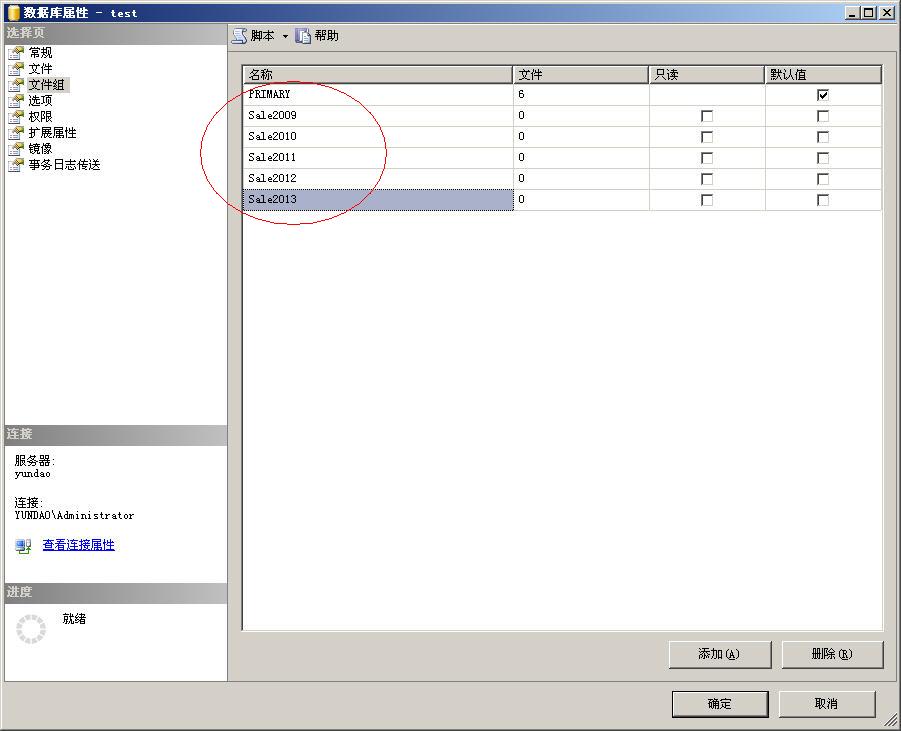
第二,創建了文件組之後,還要再創建幾個數據庫文件。為什麼要創建數據庫文件,這很好理解,因為分區的小表必須要放在硬盤上,而放在硬盤上的什麼地方呢?當然是文件裡啦。再說了,文件組中沒有文件,文件組還要來有啥用呢?還是在上圖的那個界面,選擇“文件”選項,然後添加幾個文件。在添加文件的時候要注意以下幾點:
1、不要忘記將不同的文件放在文件組中。當然一個文件組中也可以包含多個不同的文件。
2、如果可以的話,將不同的文件放在不同的硬盤分區裡,最好是放在不同的獨立硬盤裡。要知道IQ的速度往往是影響SQL Server運行速度的重要條件之一。將不同的文件放在不同的硬盤上,可以加快SQL Server的運行速度。
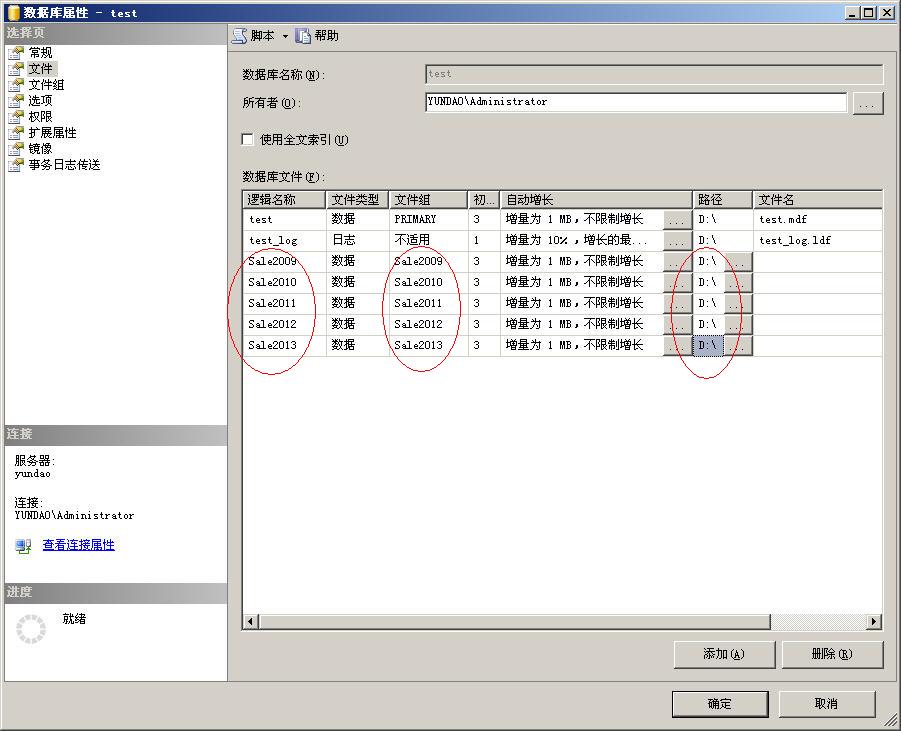
在本例中,為了方便起見,將所有數據庫文件都放在了同一個硬盤下,並且每個文件組中只有一個文件。如下圖所示。
第三、創建一個分區函數。這一步是必須的了,創建分區函數的目的是告訴SQL Server以什麼方式對分區表進行分區。這一步必須要什麼SQL腳本來完成。以上面的例子,我們要將銷售表按時間分成5個小表。假設劃分的時間為:
第1個小表:2010-1-1以前的數據(不包含2010-1-1)。
第2個小表:2010-1-1(包含2010-1-1)到2010-12-31之間的數據。
第3個小表:2011-1-1(包含2011-1-1)到2011-12-31之間的數據。
第4個小表:2012-1-1(包含2012-1-1)到2012-12-31之間的數據。
第5個小表:2013-1-1(包含2013-1-1)之後的數據。
那麼分區函數的代碼如下所示:
[c-sharp] view plaincopy CREATE PARTITION FUNCTION partfunSale (datetime)
AS RANGE RIGHT FOR VALUES ('20100101','20110101','20120101','20130101')
其中:
1、CREATE PARTITION FUNCTION意思是創建一個分區函數。
2、partfunSale為分區函數名稱。
3、AS RANGE RIGHT為設置分區范圍的方式為Right,也就是右置方式。
4、FOR VALUES ('20100101','20110101','20120101','20130101')為按這幾個值來分區。
這裡需要說明的一下,在Values中,'20100101'、'20110101'、'20120101'、'20130101',這些都是分區的條件。“ 20100101”代表2010年1月1日,在小於這個值的記錄,都會分成一個小表中,如表1;而小於或等於'20100101'並且小於'20110101'的值,會放在另一個表中,如表2。以此類推,到最後,所有大小或等於'20130101'的值會放在另一個表中,如表5。
也許有人會問,為什麼值“ 20100101”會放在表2中,而不是表1中呢?這是由AS RANGE RIGHT中的RIGHT所決定的,RIGHT的意思是將等於這個值的數據放在右邊的那個表裡,也就是表2中。如果您的SQL語句中使用的是Left而不是RIGHT,那麼就會放在左邊的表中,也就是表1中。
第四、創建一個分區方案。分區方案的作用是將分區函數生成的分區映射到文件組中去。分區函數的作用是告訴SQL Server,如何將數據進行分區,而分區方案的作用則是告訴SQL Server將已分區的數據放在哪個文件組中。分區方案的代碼如下所示:
[c-sharp] view plaincopy CREATE PARTITION SCHEME partschSale
AS PARTITION partfunSale
TO (
Sale2009,
Sale2010,
Sale2011,
Sale2012,
Sale2013)
其中:
1、CREATE PARTITION SCHEME意思是創建一個分區方案。
2、partschSale為分區方案名稱。
3、AS PARTITION partfunSale說明該分區方案所使用的數據劃分條件(也就是所使用的分區函數)為partfunSale。
4、TO後面的內容是指partfunSale分區函數劃分出來的數據對應存放的文件組。
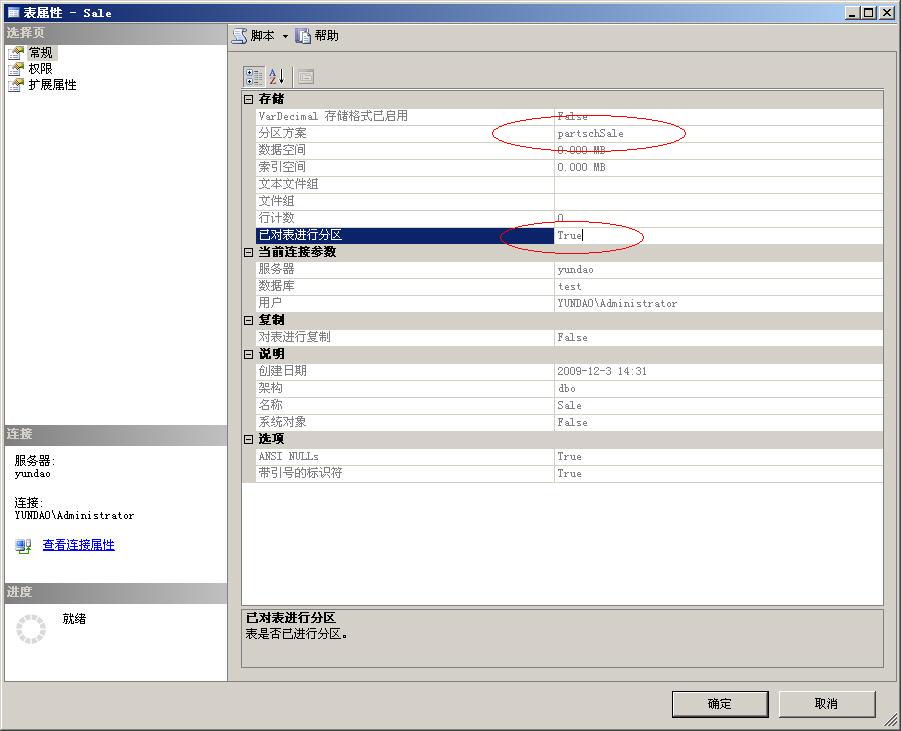
到此為止,分區函數和分區方案就創建完畢了。創建後的分區函數和分區方案在數據庫的“存儲”中可以看到,如下圖所示:
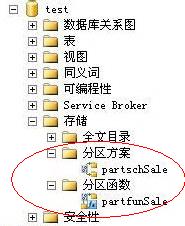
最後,創建分區表,創建方式和創建普遍表類似,如下所示:
[c-sharp] view plaincopy CREATE TABLE Sale(
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [varchar](16) NOT NULL,
[SaleTime][datetime] NOT NULL
) ON partschSale([SaleTime])
其中:
1、CREATE TABLE 意思是創建一個數據表。
2、Sale為數據表名。
3、()中為表中的字段,這裡的內容和創建普通數據表沒有什麼區別,惟一需要注意的是不能再創建聚集索引了。道理很簡單,聚集索引可以將記錄在物理上順序存儲的,而分區表是將數據分別存儲在不同的表中,這兩個概念是沖突的,所以,在創建分區表的時候就不能再創建聚集索引了。
4、ON partschSale()說明使用名為partschSale的分區方案。
5、partschSale()括號中為用於分區條件的字段是SaleTime。
OK,一個物理上是分離的,邏輯上是一體的分區表就創建完畢了。查看該表的屬性,可以看到該表已經屬於分區表了。