前言
在學習SQL 2012基礎教程過程中會時不時穿插其他內容來進行講解,相信看過SQL Server 2012 T-SQL基礎教程的童鞋知道前面寫的所有內容並非都是摘抄書上內容,如若是這樣那將沒有任何意義,學習的過程必須同時也是一個思考的過程,無論是獨立思考也好還是查資料也罷都是思考而非走馬觀花,要不然過一段時間又會健忘。簡短的內容,深入的理解。
話題
非聚集索引定義:非聚集索引也是一個B樹結構,與聚集索引不同的是,B樹的葉子節點存的是指向堆或聚集索引的指針。你真的理解了嗎??你能舉出例子嗎??其實本節最終想表達的就是這個意思,定義太長,我們抽象一點來定義並得出最終結論,請往下看。
聚集索引對非聚集索引影響
關於聚集索引和非聚集索引的概念、原理、創建都不會再敘述,若對此不太了解請參考園中其他園友的詳細介紹。
首先我們創建測試表
USE SQLStudy GO CREATE TABLE [dbo].[Test]( [ID] [int] NOT NULL, [First] [nchar](10) NULL, [Second] [nchar](10) NULL ) GO
接下來我們再來創建測試數據
INSERT INTO [SQLStudy].[dbo].[Test] ([ID],[First],[Second]) SELECT 1,'First1','Second1' UNION ALL SELECT 2,'First2','Second2' UNION ALL SELECT 3,'First3','Second3' UNION ALL SELECT 4,'First4','Second4' UNION ALL SELECT 5,'First5','Second5' GO
緊接著我們對表上的First和Second列創建聚集索引,如下
CREATE NONCLUSTERED INDEX [IX_MyTable_NonClustered] ON [dbo].[Test] ( [First] ASC, [Second] ASC )
此時我們來同時運行兩個查詢,看看其執行計劃【注】:上一篇已經說過,請啟用包括實際執行的計劃。
SELECT ID FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' SELECT Second FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' GO
此時我們看到的執行計劃如下:
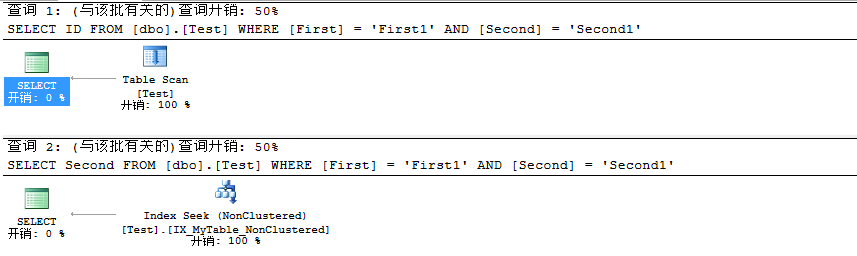
通過上述毫無疑問我們可以得出結論:查詢1是利用的全表掃描,而查詢2利用的非聚集索引查找。我們應該對於這個結論沒有任何懷疑,因為要第二個查詢的Second列在此之前已經創建額非聚集索引,而對於查詢1中的ID則沒有,所以會造成查詢1的全表掃描,而查詢2則是非聚集索引查找。
下面我們對表上的列ID創建聚集索引。
CREATE CLUSTERED INDEX [IX_MyTable_Clustered] ON [dbo].[Test] ( [ID] ASC )
此時我們再來運行如下查詢:
SELECT ID FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' SELECT Second FROM [dbo].[Test] WHERE [First] = 'First1' AND [Second] = 'Second1' GO
此時再來看看查詢執行計劃:
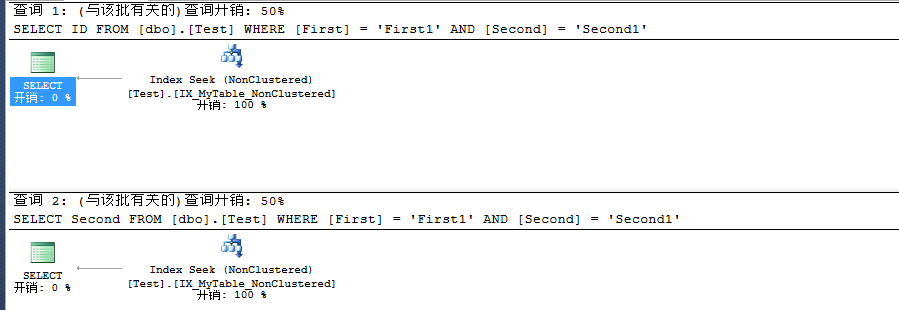
通過上述我們對列ID創建了聚集索引,我們肯定能立馬知道兩者都是利用索引查找,確實沒錯,但是,但是你發現沒有,睜大眼睛看看,我們明明在列ID上創建的是聚集索引,理論上應該是聚集索引查找才對啊,這就是我們本文所需要討論的問題。
問題探討
我們將問題進行如下概述,當我們在列上創建聚集索引時且查詢返回該列,同時查詢條件是創建了非聚集索引的列,此時對於創建了聚集索引的列的查詢執行計劃則是非聚集索引查找,這其中到底發生了什麼?
實際發生的情況是非聚集索引內部引用了聚集索引, 當聚集索引被創建後在表中的數據會按照物理邏輯進行排序,當聚集索引沒有被創建時此時非聚集索引指向的表中的數據並最終返回數據,但是一旦聚集索引創建了此時非聚集索引則會重建從而此時指向的是聚集索引,說到這裡對於園友CareySon對於非聚集索引的描述:非聚集索引也是一個B樹結構,與聚集索引不同的是,B樹的葉子節點存的是指向堆或聚集索引的指針。概括的非常精准,若創建了聚集索引此時非聚集索引的指針則指向的是聚集索引,否則此時指向的是堆也就是表中的數據。所以此時在這種情況下,當查詢創建了聚集索引的列時是進行了非聚集索引查找。
至此,我們可以得出結論:當在檢索的列上創建了聚集索引時(僅僅返回創建聚集索引的列),此時查詢不會使用聚集索引查找來檢索結果而是使用非聚集索引查找來檢索結果。
總結
個人覺得對於一個定義出來之前我們得首先拋出這樣一個問題,如上述非聚集索引的定義:非聚集索引也是一個B樹結構,與聚集索引不同的是,B樹的葉子節點存的是指向堆或聚集索引的指針。初次看到這句感覺沒什麼,泛泛而談,感覺似乎理解了,當遇到這樣的問題時卻不知所措,其實就是對定義理解的不夠深入或者說不夠透,當一個定義出來時你能舉出這個定義的例子或者場景,那可能才算是真正了解了。本節我們到此結束,對於SQL這一系列會秉著簡短的內容,深入的理解來講解,同時也會循序漸進講講查詢性能問題,由拋出問題到最終解決問題才算是收貨多多。
以上就是本文的全部內容,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如果有疑問大家可以留言交流,同時也希望多多支持!