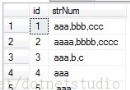
本篇文章的議題如下:
很多時候,當我們在使用sql server的時候,做的事情非常簡單:輸入sql語句,然後執行,最後獲取結果。下面,為了使得大家更加清楚的了解SQL Server的內部機制,我們就重新來審視一個sql語句的執行。
把sql語句提到給了之後,數據庫會執行一系列的內部處理,我們大致的可將內部的處理按照執行的順序,劃分為兩個階段:
在數據庫的關系引擎中,sql 的查詢語句會解析並且將解析的結果傳遞給後面的查詢優化器,查詢優化器負責生成執行計劃。之後,執行計劃(以二級制的格式)就會被傳遞到存儲引擎裡面,最後返回或更新底層的數據。
數據庫的存儲引擎會進行很多的操作,例如鎖定,索引的維護,事務的處理等。
因為本系列文章主要的剖析執行計劃,所以我們的關注點會放在關系引擎上面。
下面,我們就來稍微詳細的討論一個sql查詢語句的執行過程。
正如我們剛剛提到過:當把一個sql語句提交到了數據庫以後,sql語句最先會被傳入到關系引擎中。
當sql語句達到了關系引擎之後,首先要進行的操作就是檢查sql語句的格式是否正確。這個處理過程就是我們常說的“解析”過程。解析過程的結果就是生成一個解析樹,或者稱為查詢樹。查詢樹反映了一個查詢要執行的邏輯步驟,查詢樹的結構類似下面圖中所示:
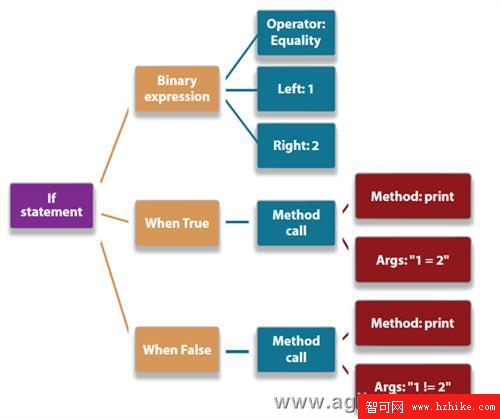
其實從編譯原理的角度來看,這個解析過程就是文法和詞法的解析,最後生成語法樹。
有一點需要注意的就是:如果提交的sql語句不是一個數據操作語句(數據操作語句指Select,Insert,Update語句),那麼這個語句是不會被優化的。例如,如果提交的sql語句是創建一個數據表,那麼這個語句是不會被優化的,而是直接執行。
如果提交的數據操作語句,那麼之前由關系引擎創建的解析樹就會傳遞給algebrizer組件執行綁定過程。在這個綁定過程過程中,這個algebrizer組件就會去檢查解析樹中的表名,列名是否都關聯到了數據庫中相應的表或對象的引用。
同時,algebrizer組件還負責確定解析樹中的每個節點的類型是否和數據庫中對應的是否一致。algebrizer組件以從下到上的方式開始遍歷樹,即,先從頁級節點開始,也就是列和常量。
綁定解析是一個非常重要的過程,在這個過程中還會識別出我們自己定義的一些別名。這個過程執行完成之後,就會產生一個二進制的“查詢處理樹”,這個樹會被傳遞給查詢優化器。
查詢優化器使用查詢處理樹和相關的統計信息來生成一個執行計劃。
換句話說,查詢優化器指出了如何最好的去執行提交的sql語句。查詢優化器會決定是否可以采用索引來訪問數據,采用那種類型的join操作會更好(例如,盡管我們有時候在sql中寫的是Left Join,可能查詢優化器在分析之後,在保證結果一樣的前提下,采用Inner Join)。
查詢優化器是一個基本成本分析的優化器。這意味著它會嘗試為每個sql語句生成成本最低的執行計劃。
另外,我們來歸對於優化器所用到的統計數據進行簡要的解析。所謂的統計數據,就是在數據庫中描述列、索引相關信息的數據,即數據的數據,或稱之為“元數據”。優化器就是結合統計數據和查詢處理樹來進行成本的估計的。
在默認的情況下,統計信息是由數據庫內部自動的進行更新的(在調優的時候,可以手動的更新)。
需要提及的就是:表變量是沒有任何的統計數據的,也就是說,如果對表變量中的數據進行查詢,優化器是不做任何的優化的。但是臨時表是有相應的統計數據的。
有一點需要注意的就是:上面的成本只是“估算”而已。一些復雜的語句可能會有很多個候選的執行計劃,在這種情況下,查詢優化器不會分析所有的組合,而是找出一個接近理論最小值的一個執行計劃。計劃的成本表現為估計完成查詢所需的時間。最低估計成本不一定是最低的資源成本。
一旦執行計劃生成之後,操作就轉入存儲引擎中,這也是查詢真正被執行的地方,也是根據估計執行計劃 產生實際執行計劃的產所。
從之前的一些步驟可以看到:SQL Server產生一個實際的執行計劃需要很多的步驟和很多的成本(執行計劃的過度編譯往往成為一個很大的性能問題),必須盡可能的重用執行計劃(如果後文不做特殊說明,執行計劃就指代“實際執行計劃”),所以,在數據庫中,一旦執行計劃產生之後,就被緩存在了內存中(稱之為計劃緩沖)。
正如之前所提到的,當優化器產生了估計的執行計劃之後,計劃就會被傳遞給存儲引擎。其實在將估計的執行計劃傳給存儲引擎之前,查詢優化器就去“計劃緩沖” 中查找與現在估計的執行計劃對應的實際執行計劃。如果找到了,那麼,查詢優化器將會使用執行計劃傳進行後續操作。這樣就避免了重新生成實際的執行計劃。
一般而言,每個查詢的執行計劃都只保存一個,除非查詢優化器知道采用並行執行可以產生更好的性能,此時,並行查詢的執行計劃就被緩存起來,也就是說:同一個查詢,在計劃緩沖中有兩個執行計劃。
執行計劃並不是永遠被保存在內存中的。它們也是會過期的。SQL Server會基於最近最少使用的算法來移除那些不常用的執行計劃。下面列出了執行計劃被移除的幾個條件:
注:熟悉.NET的朋友,可以將之與.Net的垃圾回收機制類比理解。
今天就到這裡,下一篇,我們將對執行計劃進行更多的分析!