很多數據恢復工程師包括一些數據恢復技術愛好者經常會問同樣一個問題:“數據一旦被覆蓋了,還能不能恢復呀?我聽說國外能恢復被覆蓋以後的數據,據說只要是覆蓋操作在7次以內,都能恢復出來,國內有沒有這種技術呀?”這種問題困惑很多人,也困惑很多年,到現在也只是停留在傳說階段,沒有人能夠證實!市面上有一些數據擦除工具,在進行數據毀滅擦除的時候往往有一個選項:擦除1遍?擦除3遍?擦除7遍?我在懷疑是不是一種心理作用。在我目前認知的數據恢復技術領域,我堅決的認為:只要覆蓋一遍,數據就不可恢復!如果說能恢復,那已經超出目前世界商業數據恢復技術領域,可能是個傳說吧。
本文的重點是要揭開數據覆蓋假象問題,並不討論數據被覆蓋以後的恢復技術。所謂的“數據覆蓋假象”,就是數據丟失或者被破壞以後,數據恢復工程師沒能恢復出用戶需要的文件,就主觀的認為數據“被”覆蓋了,其實丟失的數據“屍體”可能完整的躺在硬盤中,或者以支離破碎的“屍體”碎片散落在硬盤的多個位置上。真正的數據恢復高級技術,就是把數據“屍體”從硬盤中撈出來,運氣好的話,一個丟失的文件數據“屍體”連續存放在硬盤中,恢復就較為簡單。如果數據分成多段存放在硬盤中,數據恢復工程師就得把所有的數據段(數據碎片)撈出來,然後進行拼接,最終化腐朽為神奇,還原出丟失的數據完整的“屍體”,再進行文件內容確認,數據恢復就基本結束。
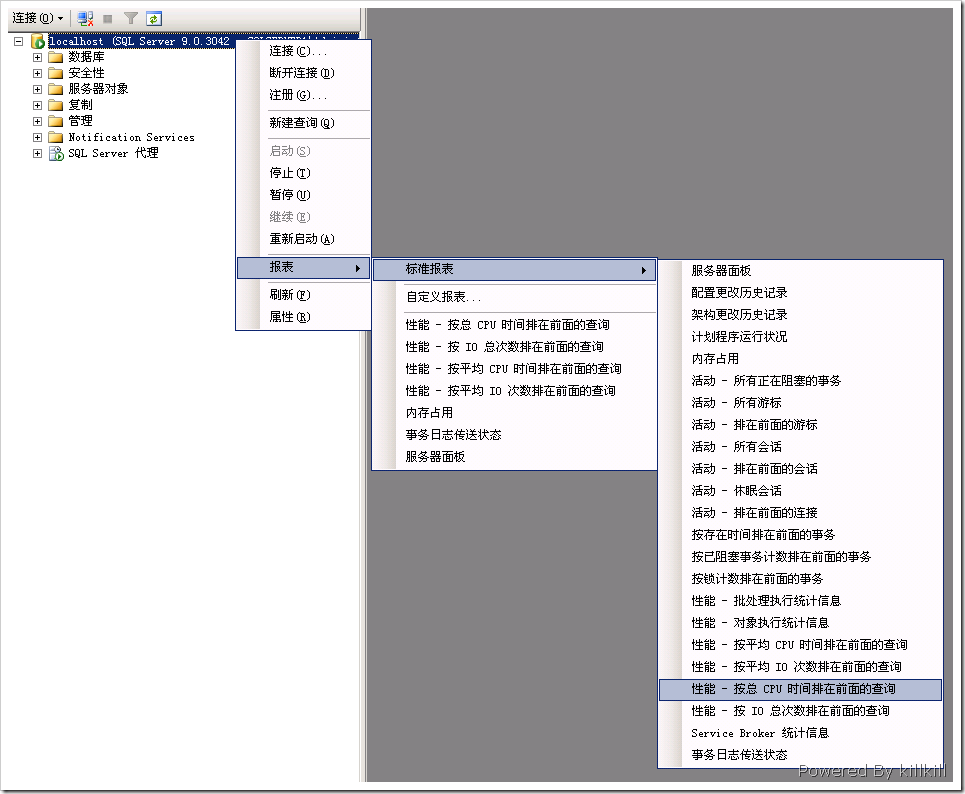
我們以一個實際的數據恢復案例來講解。
實際環境:
在Windows 2003 Server操作系統下,采用NTFS分區類型,裝了一個MS SQL Server 2005數據庫,一共有10個數據庫在用,其中有一個數據名稱是xiangmu01,對應兩個物理文件xiangmu01.mdf和 xiangmu01.ldf,這個數據庫使用有兩年多時間,xiangmu01.mdf大小有18GB,xiangmu01.ldf大小有30GB,存放路徑為d:\database\。
數據丟失過程:
某個粗心的工程師在使用服務器時,從MS SQL Server企業管理器中創建了一個新的數據庫,名稱為xiangmu001,創建時使用默認存儲路徑,默認路徑把數據庫xiangmu001的物理文件創建在了C盤的MS SQL Server安裝路徑上,他及時發現,想把數據xiangmu001刪除了,重新創建,把物理文件存放到d:\database\下,災難就在這一步降臨,錯誤的把xiangmu01數據庫刪除了,然後再創建xiangmu001數據庫,把物理文件路徑更改成d:\database\,企業管理器出現提示“該數據庫名稱已經存在”,停下來檢查,腦袋嗡的一聲“刪錯了數據庫!”。
這個時候工程師想的第一件事就是找備份來還原!!!!於是在E盤中找到xiangmu01.bak文件,還記得核准時間,又一陣心慌意亂,這個備份是半年前的,檢查一下這個庫的備份腳本,早在半年前不起用了,不知道什麼原因。於是又做了一個大膽的操作--“還原這個備份文件”。
他還原的步驟是,先創建xiangmu01數據庫,物理文件名稱和路徑跟原來數據庫一樣,於是在d:\database\下由於刪除xiangmu01數據庫丟失掉的兩個物理文件xiangmu01.mdf和 xiangmu01.ldf,又出現在d:\database\目錄下,按照數據恢復行業詞匯就是“同名覆蓋”。創建好了新的xiangmu01數據庫,就用xiangmu01.bak來還原,禍不單行,這個xiangmu01.bak文件是壞的,還原不了。到了這裡,瞞也瞞不住,上報領導,挽救數據!!
數據恢復是否有可能?
我們先不評價數據丟失過程怎樣的XXX,就這個案例而言,數據恢復成功的可能性到底有沒有??根據不同的數據恢復公司,接到這樣的數據恢復案例,會有如下3種處理情況:
數據庫碎片頁面的概念
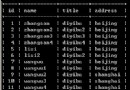
數據庫文件在設計的時候都是按照一定的有規律的形式來存放的,數據庫文件內部結構相當於一個小型的文件系統,我們了解NTFS文件系統,它有“簇”的概念,就是文件存放分配的最小單元。在數據庫文件裡頭,有Page即“數據頁”的概念,就是數據庫文件結構按照一頁一頁存放,每一個頁面占用16sec或者 32sec或者別的更大點的數,對於MS SQL Server來說,每一頁的大小有16sec,每個數據頁有自己的頁面編號等信息,每個頁面有自己的校驗方式等等,我們在提取數據庫頁面的時候,就根據這些規律來的。當把所有數據庫頁面碎片提取出來以後,怎樣把這些頁面拼接成一個文件,又是一門數據恢復藝術!
數據恢復結果
本案例使用達思D-Recovery For MS SQL Server數據庫恢復軟件得以恢復,目前是國內少有的基於MS SQL Server數據庫恢復軟件。首先,它有數據庫碎片提取功能,有一定的碎片智能組合功能,如果某條組合線路出現分叉,可以人工查看,確定正確的組合線路,最終能把mdf文件相對完整的拼接出來。
其次,它可以直接讀取mdf文件內容,如果有某些數據頁面被覆蓋或者被破壞,它可以繞過這些壞頁面,把mdf文件中正常的數據記錄提取出來,然後進行數據還原。在mdf文件局部損壞的情況下,MS SQL Server環境沒有辦法修復mdf文件,沒辦法讀取mdf文件中的數據,這時候D-Recovery For MS SQL Server就發揮它強大的數據庫內容提取功能!
揭開數據覆蓋假象
對本案例而言,出現了同名文件覆蓋的現象,大多數人都認為是數據被覆蓋了!在NTFS文件系統中,同名覆蓋,往往意味著原先文件MFT表項和後面覆蓋過來的文件的 MFT表項是同一個,MFT表項ID號(如果有ID號)不會更改,更改的只是MFT表項內部的數據指針!這樣通過任何數據恢復工具掃描,不會找出原始文件 MFT內部數據指針,找到的都是新覆蓋的文件的MFT表項信息。
數據區會不會也被新文件覆蓋呢?答案是不一定!Windows操作系統在分配新覆蓋過來的文件空間的時候,有可能會按照舊文件的指針分配,有可能分配新的數據空間,這就看Windows NTFS 文件系統文件空間分配機制了!如果說,新文件分配新空間,跟原始文件空間不發生重疊,那原始文件內容將不會受影響!
為什麼按照mdf文件類型來恢復,沒能找出正確的文件?數據庫文件xiangmu01.mdf已經使用了兩年多,數據庫在創建的時候,數據庫文件根據需要分配空間,而不是一開始就分配很大的空間,所以在以後使用過程中,空間分配分散很嚴重,在硬盤上不可能連續存放!按照類型掃描恢復文件大都基於數據文件連續存放,否則恢復出來的文件只正確包含文件地一段數據信息!
數據覆蓋不是想當然,要經過最底層的分析,才能得出正確的恢復方法。