我們來簡單地看看SQL Server索引是如何工作的,關於索引的一些概念就不說了。
聚簇索引:
(圖A)
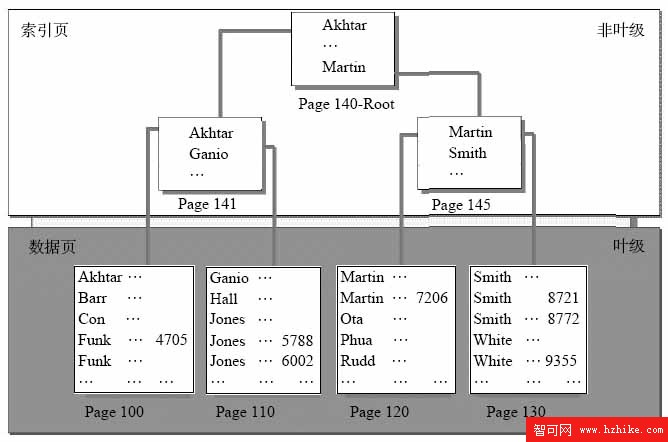
我們來看圖A,聚簇索引的結構圖。
數據頁就是數據庫裡實際存儲數據的地方,可以看到是按頁1頁1頁存的。
假設那個列是”LastName”。
因為是聚集索引,所以它是按照順序排下來的。可以看到,索引是一棵樹,首先先看一下這棵樹是怎麼形成的。
先看Page100和Page110的最上面,由它們形成了Page141,Page141的第一條數據是Page100的第一條數據,Page141的最後一條數據是Page110的第一條數據。同理由Page120和Page130形成Page145,Page141和Page145形成根Page140.
好了,然後來看看它是如何查找數據的。
我們來找”Rudd”這個姓。
首先它會從根即Page140開始找,因為”Rudd”的值比”Martin”大(只要比較一下他們首字母就知道了,按26個字母順序R排在M的後面),所以會往”Martin”的後面找,即找到Page145,然後在比較一下”Rudd”和”Smith”,”Rudd”比”Smith”小,所以會往左邊找即Page120,然後在Page120逐行掃描下來直到找到”Rudd”。
如果不建索引的話,SQL Server會從第一頁開始按順序每頁逐行掃描過去,直到找到”Rudd”。顯然如果對於一個百萬行的表來說,效率是極其低下的,如果建了索引,非常快就能找到。
非聚簇索引:
(圖B)
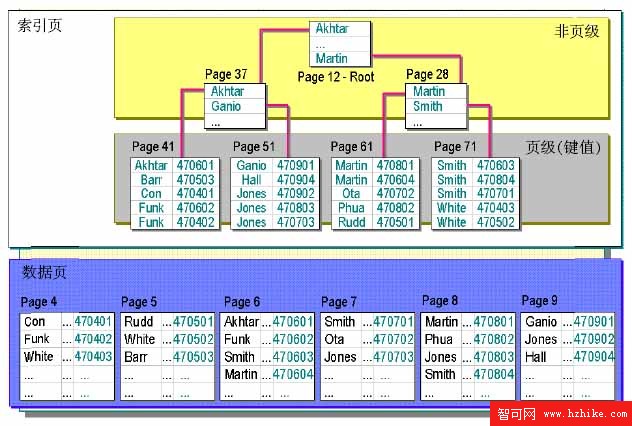
看圖B,非聚簇索引的結構圖。
聚簇索引和非聚簇索引的區別就是:聚簇索引的數據物理存儲順序和索引順序一致的,也就是它的數據就是按順序排下來的。非聚簇索引的數據存儲是無序的,不按索引順序排列。
從圖B可以看到數據頁裡是無序的。那麼它的索引是如何建立的呢?
再看圖B,它是把這個索引列的數據復制了一份然後按順序排下來,再建立索引。每行數據都有一個指針。
我們再來找”Rudd”.首先從索引頁的根開始找,查找原理跟聚集索引是一樣的。在索引頁的Page61找到”Rudd”,它的指針是470501,然後在數據頁的Page5找到470501,這個位置就是”Rudd”在數據庫中的實際位置,這樣就找到了”Rudd”。
好了,索引的基本工作原理就是這樣,可能實際上要復雜些。