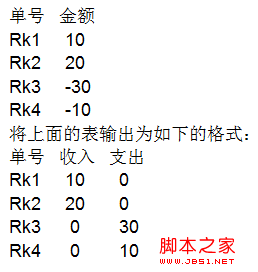
購物網站上經常能看到購物籃推薦,就是在購物過程中或購物過程後網站根據用戶的購物情況做相應推薦。典型的比如amazon.com。我認為推薦的相當的准確。這個購物籃推薦的場景是一個數據挖掘的典型場景。當然願意的話也可以不用現成的數據挖掘工具,自己設計算法、自己實現。
Microsoft SQL Server從2005開始就有一個一個專門用於購物籃推薦的數據挖掘算法:關聯規則算法。
要使用這個關聯算法來實現購物籃推薦,首先需要安裝microsoft analysis server。這是從sql server 2000開始就附帶在SQL Server中的一個服務。用於商業智能。
下面是microsoft analysis server 2008 r2的一個截圖。我用它來分析一些手工造出來的數據,得到酒店間的關聯關系。
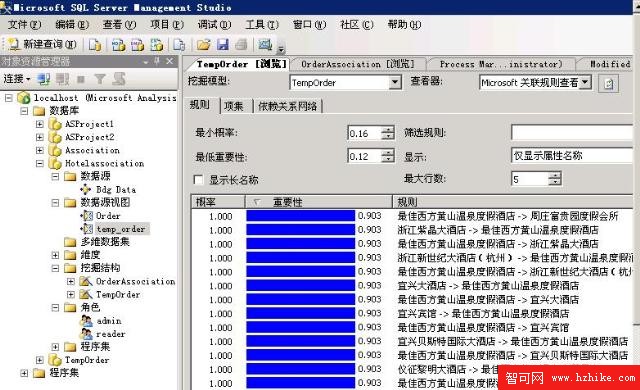
從圖中可以看出,analysis server有這麼幾個重要的概念:
1:數據庫,比如那個HotelAssociation。
2:數據源,每個數據庫實際連接的數據源,可以是關系型數據庫,也可以是數據倉庫
3:數據源視圖,類似於SQL Server中的視圖,一般是幾個表和/或視圖組成一個數據源視圖。如下圖的這個數據源視圖
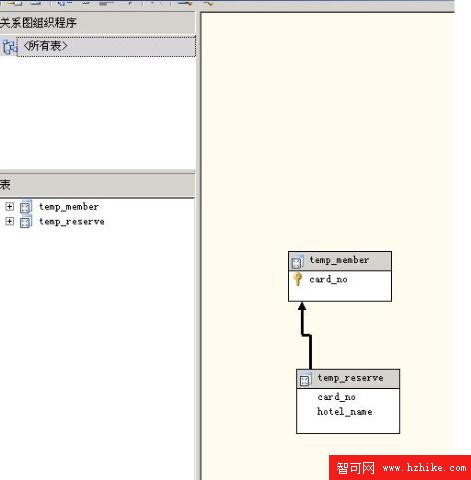
4:挖掘結構,一個具體的挖掘任務
5:挖掘模型,可以對一個挖掘結構的運算參數的配置,比如可以定義不同的挖掘算法。我在這裡例子裡選擇了“關聯規則”算法。
定義好以上這些對象之後就可以讓analysis server來“處理”數據,也就是計算數據。計算結束後可以“浏覽”。圖一的右下方就是浏覽tempOrder這個挖掘模型的結果。“規則”就是算出來的客戶的預訂行為規則。表示客戶預訂一個酒店後還會再訂另外一個酒店。其中有兩個重要的參數,一個是“概率”,一個是“重要性”。概率比較好理解,就是一個行為出現的概率。比如共有100位客戶預訂過A產品,其中有30位預訂A之後又預訂了B,那個規則A->B的概率就是30%。“重要性”我看微軟的文檔沒看明白,沒說具體的算法。以前有一個webcast說過這個概念,可以也沒細說,一帶而過。重要性可以為負,負數表示負關聯,就是兩個產品互相排斥。
這些算出來的規則可以在服務器上浏覽,當然還可以用類似於sql的DMX來查詢:
SELECT flattened
PREDICT([TempOrder].[temp reserve],INCLUDE_STATISTICS,3)
From
[TempOrder]
NATURAL PREDICTION JOIN
(SELECT (SELECT '宜興大酒店' AS [Model]
// UNION SELECT 'Mountain Tire Tube' AS [Model]
// UNION SELECT 'Mountain-200' AS [Model]
) AS [Products]) AS t
這個語句是要查一下如果用戶預訂了“宜興大酒店”的話,最有可能去預訂的其他三個酒店。
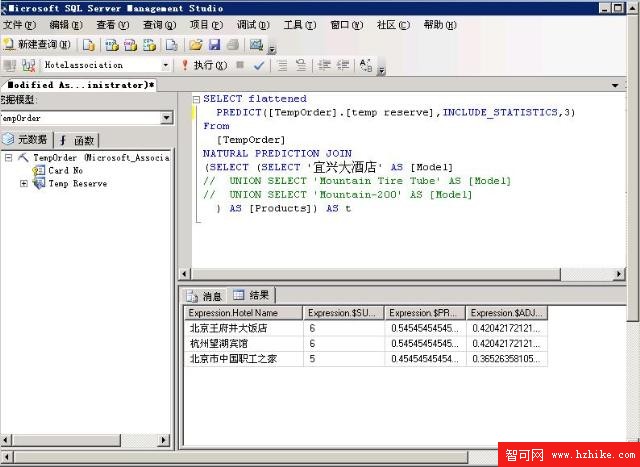
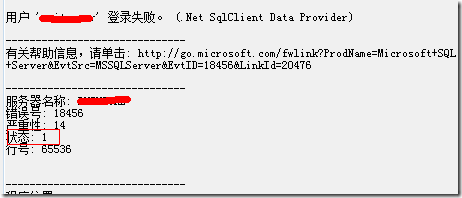
這麼查出來用處也不大。必須要能從客戶端用程序訪問才可以最終被作為web上的購物籃推薦。
用.net代碼訪問analysis server的數據,客戶端必須安裝adomd.Net的客戶端組件,需要下載。
msdn上能下載下來幾個例子,一個是adomd.Net的例子,一個是analysis server的samples。都不好使。這個問題目前我還沒解決。如果有朋友已經解決,還請多指教。
另外一個問題是如何讓analysis server定時自動計算?界面上沒看到。我能想到的方法是用DMX實現自動計算,把DMX設為job。
還有一個問題我在微軟文檔中看到微軟已經解決,就是在analysis server運算的時候,相應的數據庫就沒法查詢了。SQL Server 2008 r2的解決方案是“同步”。可以把算好的數據同步到另外一台服務器上。一般情況下目標數據庫只有幾秒鐘的不響應。