特別說明
在微軟的SQL Server系統中通過有效的使用索引可以提高數據庫的查詢性能,但是性能的提高取決於數據庫的實現。在本文中將會告訴你如何實現索引並有效的提高數據庫的性能。
在關系型數據庫中使用索引能夠提高數據庫性能,這一點是非常明顯的。用的索引越多,從數據庫系統中得到數據的速度就越快。然而,需要注意的是,用的索引越多,向數據庫系統中插入新數據所花費的時間就越多。在本文中,你將了解到微軟的SQL Server數據庫所支持的各種不同類型的索引,在這裡你將了解到如何使用不同的方法來實現索引,通過這些不同的實現方法,你在數據庫的讀性能方面得到的遠比在數據庫的整體性能方面的損失要多得多。
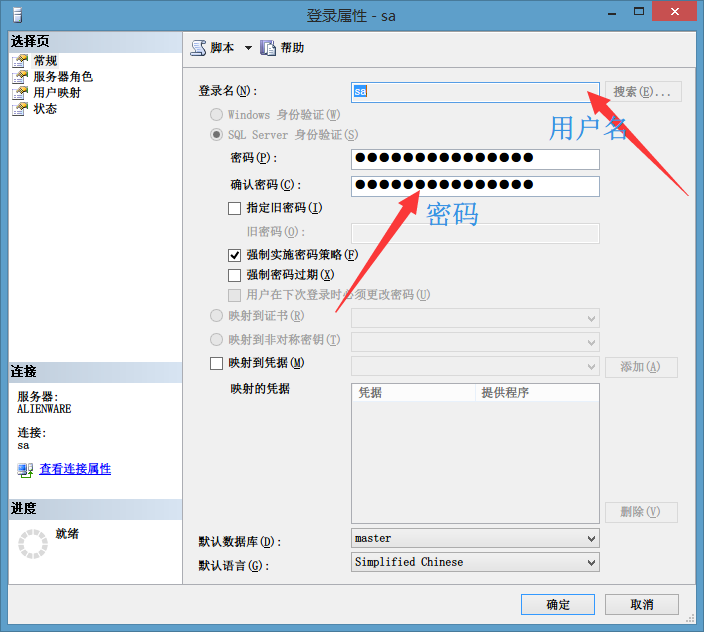
索引的定義 索引是數據庫的工具,通過使用索引,在數據庫中獲取數據的時候,就可以不用掃描數據庫中的所有數據記錄,這樣能夠提高系統獲取數據的性能。使用索引可以改變數據的組織方式,使得所有的數據都是按照相似的結構來組織的,這樣就可以很容易地實現數據的檢索訪問。索引是按照列來創建的,這樣就可以根據索引列中的值來幫助數據庫找到相應的數據。
索引的類型 微軟的SQL Server 支持兩種類型的索引:clustered 索引和nonclustered索引。Clustered 索引在數據表中按照物理順序存儲數據。因為在表中只有一個物理順序,所以在每個表中只能有一個clustered索引。在查找某個范圍內的數據時,Clustered索引是一種非常有效的索引,因為這些數據在存儲的時候已經按照物理順序排好序了。
Nonclustered索引不會影響到下面的物理存儲,但是它是由數據行指針構成的。如果已經存在一個clustered索引,在nonclustered中的索引指針將包含clustered索引的位置參考。這些索引比數據更緊促,而且對這些索引的掃描速度比對實際的數據表掃描要快得多。
如何實現索引 數據庫可以自動創建某些索引。例如,微軟的SQL Server系統通過自動創建唯一索引來強制實現UNIQUE約束,這樣可以確保在數據庫中不會插入重復數據。也可以使用CREATE INDEX語句或者通過SQL Server Enterprise Manager來創建其他索引,SQL Server Enterprise Manager還有一個索引創建模板來指導你如何創建索引。
得到更好的性能 雖然索引可以帶來性能上的優勢,但是同時也將帶來一定的代價。雖然SQL Server系統允許你在每個數據表中創建多達256個nonclustered索引,但是建議不要使用這麼多的索引。因為索引需要在內存和物理磁盤驅動器上使用更多的存儲空間。在執行插入聲明的過程中可能會在一定程度上導致系統性能的下降,因為在插入數據的時候是需要根據索引的順序插入,而不是在第一個可用的位置直接插入數據,這樣一來,存在的索引越多將導致插入或者更新聲明所需要的時間就越多。
在使用SQL Server系統創建索引的時候,建議參照下面的創建准則來實現:
正確的選擇數據類型
在索引中使用某些數據類型可以提高數據庫系統的效率,例如,Int,bigint, smallint,和tinyint等這些數據類型都非常適合於用在索引中,因為他們都占用相同大小的空間並且可以很容易地實現比較操作。其他的數據類型如char和varchar的效率都非常低,因為這些數據類型都不適合於執行數學操作,並且執行比較操作的時間都比上面提到數據類型要長。
確保在使用的過程中正確的利用索引值
在執行查詢操作時,可能所使用的列只是clustered的一部分,這時尤其要注意的是如何使用這些數據。當用這些數據列作為參數調用函數時,這些函數可能會使現有的排序優勢失效。例如,使用日期值作為索引,而為了實現比較操作,可能需要將這個日期值轉換為字符串,這樣將導致在查詢過程中無法用到這個日期索引值。
在創建多列索引時,需要注意列的順序
數據庫將根據第一列索引的值來排列記錄,然後進一步根據第二列的值來排序,依次排序直到最後一個索引排序完畢。哪一列唯一數據值較少,哪一列就應該為第一個索引,這樣可以確保數據可以通過索引進一步交叉排序。
在clustered索引中限制列的數量
在clustered索引中用到的列越多,在nonclustered索引中包含的clustered索引參考位置就越多,需要存儲的數據也就越多。這樣將增加包含索引的數據表的大小,並且將增加基於索引的搜索時間。
避免頻繁更新clustered索引數據列
由於nonclustered 索引依賴於clustered 索引,所以如果構成clustered 索引的數據列頻繁更新,將導致在nonclustered中存儲的行定位器也將隨之頻繁更新。