用戶定義的函數 (UDF) 是准備好的代碼片段,它可以接受參數,處理邏輯,然後返回某些數據。根據 SQL Server Books Online,SQL Server™ 2000 中的 UDF 可以接受從 0 到 1024 的任意個數的參數,不過我必須承認,我還未嘗試將 1024 個參數傳遞到 UDF 中。UDF 的另一個關鍵特征是返回一個值。取決於 UDF 的類型,調用例程可以使用這個值來繼續處理它的數據。因此,如果 UDF 返回單一值(標量值),調用例程就可以在任何能夠使用標准變量或文字值的地方使用這個值。如果 UDF 返回一個行集,則調用例程可以循環訪問該行集,聯接到該行集,或簡單地從該行集中選擇列。
雖然現在大多數編程語言已經暫時支持函數,但只有 SQL Server 2000 引入了 UDF。存儲過程和視圖在 SQL Server 中可用的時間遠早於 UDF,但這些對象中的每一個在 SQL Server 開發中都有自己適當的位置。存儲過程可以很好地用於處理復雜的 SQL 邏輯、保證和控制對數據的訪問,以及將行集返回到調用例程,無論此例程是基於 Visual Basic® 的程序,還是另一個 Transact-SQL (T-SQL) 批處理文件。與視圖不同,存儲過程是已編譯的,這使得它們成為用來表示和處理頻繁運行的 SQL 語句的理想候選者。視圖可以很好地用於控制對數據的訪問,但它們的控制方式與存儲過程不同。視圖僅限於生成該視圖的基礎 SELECT 語句中的某些列和行。因而視圖常用於表示常用的 SELECT 語句,該語句可以聯接多個表、使用 WHERE 子句,以及公開特定的列。在聯接到其他表和視圖的 SQL 語句的 FROM 子句中經常會發現視圖。
在其核心部分,UDF 既類似於視圖,也類似於存儲過程。像視圖一樣,UDF 可以返回一個行集,該行集可用於 JOIN 中。因此,當 UDF 返回一個行集並接受參數時,它像一個您可以聯接到的存儲過程、或者一個參數化的視圖。但是,正如我將演示的,UDF 可以做到這一點,甚至更多。
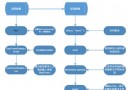
有兩種主要的 UDF 類型:返回標量值的 UDF 和返回表值的 UDF。在表值 UDF 中,您將找到返回內聯表和多語句表的 UDF(請參見ASPx?fig=true#fig1" target="_blank">圖 1)。在以下部分中,我將對每種類型都加以關注。
標量 UDF
返回標量值的 UDF 最類似於許多編程語言所引用的作為函數的內容。它們返回由標量數據類型(例如,integer、varchar(n)、char(n)、money、datetime、bit,等等)組成的單一值。如果用戶定義的數據類型 (UDDT) 基於標量數據類型,UDF 也可以返回這些數據類型。使用返回內聯或多語句表的 UDF,可以通過表數據類型返回行集。然而,並非所有的數據類型都可以從 UDF 中返回。例如,UDF 無法返回下列數據類型中任何一個的值:text、ntext、image、cursor、或 timestamp。
返回標量數據類型的 UDF 可以用於多種情況,以使代碼具有更好的可維護性、可重用性和更少的復雜性。當 T-SQL 代碼的相同段在幾個地方(可能由幾個存儲過程和批 SQL 語句)使用時,這會非常有用。例如,假定一個應用程序中的幾個部分都需要查找產品是否必須重新訂購。在每個需要此操作的地方,代碼可以檢查重新訂購等級,並將它與庫存量加訂購量的和相比較。然而,因為這個代碼在幾個地方用到,所以可以改為使用 UDF 以減少代碼塊,並使得萬一需要更改時維護函數更加容易。這樣的 UDF 可能看起來像ASPx?fig=true#fig2" target="_blank">圖 2 中的代碼,並可以使用以下 SQL 語句進行調用:
SELECT ProductID, ReorderLevel, UnitsInStock, UnitsOnOrder, dbo.fnNeedToReorder(ReorderLevel, UnitsInStock, UnitsOnOrder) AS sNeedToReorder FROM Products
在ASPx?fig=true#fig2" target="_blank">圖 2中,fnNeedToReorder UDF 執行計算並返回適當的值。這本來可以通過 CASE 語句在 SELECT 子句內完成,但如果改為使用 UDF,代碼就會簡潔得多。而且更容易傳播到其他可能需要相同邏輯的地方。假定一個應用程序中有幾個部分需要確定是否要重新訂購產品,那麼ASPx?fig=true#fig2" target="_blank">圖 2 中的 UDF 確實變得有價值,
因為它使得當邏輯改變時應用程序更容易維護。例如,重新訂購已經終止的產品並不是很有意義。因此,通過更改 UDF 以說明這個業務規則,可以在一個地方更改此邏輯(請參見ASPx?fig=true#fig3" target="_blank">圖 3)並使用下列代碼運行:
SELECT ProductID, ReorderLevel, UnitsInStock, UnitsOnOrder, dbo.fnNeedToReorder(ReorderLevel, UnitsInStock, UnitsOnOrder, Discontinued) AS sNeedToReorder FROM Products
請注意,UDF 是使用由兩個部分(對象所有者和對象名)組成的名稱調用的。當使用返回標量數據類型值的 UDF 時需要該對象的所有者。可以授權所有調用 UDF 的地方也必須加以更改,方法是將第四個參數 (Discontinued) 添加到 UDF 中。為了更容易維護,我可以重新編寫 UDF,以便使用每一行的 ProductID 來檢索數據本身,如ASPx?fig=true#fig4" target="_blank">圖 4 所示。這種技術更容易維護,因為它不需要任何調用例程來更改邏輯改變時更改 UDF 的方式,只要可以從當前 Products 表行中提取數據即可。然而,要獲得這種可維護性,會有性能方面的損失。ASPx?fig=true#fig4" target="_blank">圖 4 中的 UDF 必須為每個從調用例程中返回的行從 Products 表中檢索行。因為調用例程已經從 Products 表中檢索每個行,所以如果該表有 77 行,則代碼將執行 77 次 SELECT 語句(從主 SELECT 語句中返回每行一次)。雖然每個 SELECT 都是基於主鍵字段 (ProductID) 進行選擇的,因而會很快,但是當行集非常大或者 SELECT 語句效率較低時,性能就會受到負面影響。ASPx?fig=true#fig4" target="_blank">圖 4 中的代碼可以通過以下 SQL 片段來調用:
SELECT ProductID, ReorderLevel, UnitsInStock, UnitsOnOrder, dbo.fnNeedToReorder(ProductId) AS sNeedToReorder FROM Products
在 SELECT 語句中使用這個函數的可選方法是,在名為 NeedToReorder 的 Products 表中創建一個計算所得的列。該列並不定義為一種數據類型,而是定義為如ASPx?fig=true#fig3" target="_blank">圖 3 所示的 fnNeedToReorder UDF 的返回值。要添加此列,我可以按以下方式更改 Products 表,以指示應計算這個列:
ALTER TABLE Products ADD NeedToReorder AS dbo.fnNeedToReorder(ReorderLevel, UnitsInStock, UnitsOnOrder, Discontinued)
通用 UDF 和嵌套
至此,我已經展示了使用返回標量值的 UDF 解決同一問題的幾種方式。還有其他有用的 UDF 應用程序,其中包括 T-SQL 中還未准備好可用的函數。一個例子是專用格式化函數。例如,電話號碼通常存儲(不帶格式化字符)在 char(10) 列中,這些列表示區號和電話號碼(假定這是一個美國的號碼)。UDF 可以用於在格式化結構中檢索電話號碼(請參見ASPx?fig=true#fig5" target="_blank">
SELECT dbo.fnCOM_FormatTelephoneNumber ('3335558888')
可以使用這種技術創建任何常用函數,以增加 SQL Server 中可用函數的數量。另一個示例是將日期格式化為帶有前導零的 MM/DD/YYYY 格式的函數:
CREATE FUNCTION fnCOM_StandardDate (@dtDate DATETIME) RETURNSVARCHAR(10) AS BEGIN RETURN dbo.fnCOM_2Digits (CAST(MONTH(@dtDate) AS VARCHAR(2))) + '/' + dbo.fnCOM_2Digits (CAST(DAY(@dtDate) AS VARCHAR(2))) + '/' + CAST(YEAR(@dtDate) AS VARCHAR(4)) END
fnCOM_StandardDate UDF 接受日期時間值,並返回 MM/DD/YYYY 格式的 varchar(10) 值。當然,這很簡單,如果您的應用程序常常需要特定格式,那麼這種技術就可以使它更容易維護。在前面的代碼中需要注意的一個關鍵部分是嵌套 UDF 的使用。fnCOM_StandardDate UDF 兩次調用 fnCOM_2Digits UDF(在下一個示例中顯示),每次都在小於 10 的日或月前放置一個前導零。
CREATE FUNCTION fnCOM_2Digits (@sValue VARCHAR(2)) RETURNS VARCHAR(2) AS BEGIN IF (LEN(@sValue) < 2) SET @sValue = '0' + @sValue RETURN @sValue END
UDF 可以互相嵌套,只要其中的 UDF 是先創建的即可。使用嵌套函數的一個 catch 是非確定性內置函數(例如 getdate 函數),不能在另一個 UDF 內嵌套(否則會引發 SQL Server 錯誤)。非確定性函數是用完全相同的參數調用多次時可能返回不同結果的函數。getdate 函數屬於這一類,因為每次調用時,它會返回新的當前日期和時間。另一個常用的非確定性內置函數是 NewID 函數。它也是非確定性的,因為它總是返回唯一的 GUID,所以 NewID 函數同樣不允許在 UDF 內嵌套。
表值 UDF
表值 UDF 的類別中
有兩種子類型:返回內聯表值的 UDF 和返回多語句表值的 UDF。返回內聯表的 UDF 通過 SQL Server 表數據類型返回一個行集。它們使用構成函數體的單一 SELECT 語句進行定義。返回內聯表值的 UDF 不能在定義它將返回的表的 SQL SELECT 語句之外包含其他 T-SQL 邏輯。然而,它們比返回多語句表的 UDF 要容易創建,因為它們不必定義要返回的確切表結構。返回內聯表的 UDF 從 SELECT 語句本身推斷行集的結構。因此,UDF 將返回的列由 SELECT 列表中的列確定。下列代碼顯示了 fnGetEmployeesByCity UDF,它接受一個城市,並返回包含所有員工名字、姓和地址的表:CREATE FUNCTION fnGetEmployeesByCity (@sCity VARCHAR(30)) RETURNS TABLE AS RETURN ( SELECT FirstName, LastName, Address FROM Employees WHERE City = @sCity ) GO
可以從這個返回內聯表值的 UDF 中選擇或者甚至聯接到它,因為它通過表數據類型返回一個行集,如下所示:
SELECT * FROM dbo.fnGetEmployeesByCity('seattle')
請注意,UDF 是使用由對象所有者和對象名這兩個部分組成的名稱調用的。然而,當使用返回表數據類型值的 UDF 時,對象所有者不是必需的(但卻是可接受的)。表值 UDF 非常靈活,因為它們可以像准備好的和參數化的視圖(如果存在)一樣使用。在表值 UDF 中,您可以使用參數,獲得准備好的查詢的性能,並從得到的行集(或本例中的表)中聯接或選擇。
盡管這種 UDF 類型是簡潔的,但重要的是要記住,如果您要向這種 UDF 中添加其他邏輯,就必須將其轉換成返回多語句表值的 UDF。另外,返回內聯表值的 UDF 在 SELECT 語句中也不能有 ORDER BY 子句(除非它與 TOP 子句一起使用)。
返回多語句表的 UDF 顯式定義要返回的表的結構。它通過在 RETURNS 子句中正確定義列名稱和數據類型來做到這一點。因此,它會使用比返回內聯表值的 UDF 稍多的代碼來建立表結構。然而,與返回內聯表值的 UDF 相比,它有幾個優點,其中包括容納更復雜的、更大量的 T-SQL 邏輯塊的功能。顧名思義,返回多語句表值的 UDF 允許多個語句定義 UDF。
因此,諸如流控制、分配、游標、SELECTS、INSERTS、UPDATES 和 DELETES 等語句都是允許的,並且都可以存在於單個 UDF 中。所以,與返回內聯表的 UDF 相反,返回多語句表的 UDF 並不限定於單個 SELECT 語句,也不禁止對返回行集進行排序。
ASPx?fig=true#fig6" target="_blank">圖 6 顯示了如何將返回內聯表值的 UDF(我剛才展示的代碼片段中的)重新編寫為返回多語句表值的 UDF。因此,內聯類型能做到的,多語句類型都能做到。返回多語句表的 UDF 的更復雜的用途包括按城市檢索所有員工,但如果沒有客戶與特定的城市相匹配,就返回一個虛行,其中的 Address 字段填寫“在指定的城市中未找到匹配的員工”,如ASPx?fig=true#fig7" target="_blank">圖 7 中所示。
包裝
還有其他一些關鍵因素可以幫助創建任何類型的功能強大的 UDF,其中的一種便是遞歸。UDF 支持遞歸,以便一個 UDF 可以從自身中調用自身。基本上,遞歸只是嵌套 UDF,唯一不同的地方在於您所嵌套的 UDF 正是您所在的 UDF。這在某些情況中可能非常有用,包括在創建一個必須計算某個因子或評估一個字符串中每個字符的 UDF 時。在 SQL Server 2000 中,遞歸的限制深度為 32 層,超出限制會引發錯誤。
還需要指出的是,一個 UDF 可以綁定到它所引用的基礎對象架構。為此,UDF 必須使用 WITH SCHEMABINDING 子句來進行創建。如果 UDF 是以這種方式創建的,則當有人試圖更改一個基礎對象架構而沒有先刪除架構綁定時,就會生成並引發錯誤。采用這種選擇將有助於確保不會因為基礎對象架構中的更改而引起意外的 UDF 中斷。
當評估 UDF 時,考慮性能和可維護性之間的平衡是至關重要的。雖然 UDF 可以減少常用代碼的數量(用作常用函數庫的一部分),可以提升更短的代碼塊,並且通常比相同 SQL 邏輯的其他類型更容易維護,但是,如果不先考慮任何缺點就使用 UDF,這將是不計後果的。
如果性能嚴重降低,那麼使用 UDF 就不是一個好主意。例如,假定有一個執行 SQL SELECT 語句的 UDF,執行該語句需要一秒鐘。如果此 UDF 在 SELECT 或 WHERE 子句中使用,它將為每一行執行。因此,執行主查詢所花費的時間會急劇增加,這取決於評估和返回的行數以及適當的索引類型這樣的因素。如果是這種情況,則在使用 UDF 之前,要仔細地權衡所作的選擇並進行一些性能測試。然而,使用執行計算的 UDF(例如ASPx?fig=true#fig3" target="_blank">圖 3 中所顯示的)幾乎不影響查詢性能。正如任何工具一樣,如果在實際投入之前正確地使用並進行相應地評估,那麼UDF 會提供極大的便利和可維護性。