做開發三年來(B/S),發現基於web 架構的項目技術主要分兩大方面:
第一:C#,它是程序的基礎,也可是其它開發語言,沒有開發語言也就不存在應用程序.
第二:數據庫,現在是信息化世界,大多數信息都可以通過數據庫存儲來交換信息.常與應用程序互相交流信息.
但在SQL開發應用時,我們往往只觀注些常用的方法(insert delete select update),對些小細節方面(系統存儲過程,函數的應用,優化分析)研究的並不多或者是知其一不知其二,所以本人想把在學習工作當中遇到的問題總結些,希望還沒有重視這些方面的朋友會有幫助,少走些彎路.
SQL中的null的用法及要注意的方面
【英文辭典】 null:無效的, 無價值的, 等於零的.
【SQL定義】SQL中, NULL 與空格, 零, 都不相同. 是指為未定義或是不可用的.
構成因素:造成某一列成為NULL 的因素可能是:
(1),值不存在;
(2), 值未知;
(3), 列對表不可用.
它與普通的值最大的異同是:
相同點:
1:統統屬於值范疇.數字1是一個值,字符串'aaa'同樣是一個值,同理 null也是一個值.
2:都是合法的值,普通的數字,字符可以存在於表中字段,null也可以,而且是有意義的.
不同點:
先創建測試表:
USE [myTestDB]
GO
/****** 對象: Table [dbo].[testNull] 腳本日期: 10/11/2008 13:45:14 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[testNull](
[ID] [int] IDENTITY(1,1) NOT NULL,
[a] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[b] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
CONSTRAINT [PK_testNull] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
插入相關測試值:
insert into testNull
values('1','')
insert into testNull
values('2',null)
1:普通的值一般都可能進行運算符操作,例如:ID列為int,所以可以這樣:ID=ID+1等,但如果一列的值為null,null+1=null,就是說null與任何運算符運算後都為null,這就是大家說的黑洞,會吃掉所有的東西.
update testNull
set b=b+1
where b is null
結論:查詢後發現b的值沒有變化,仍然為null.
2:普通的值可以進行"="操作,例如條件中一般都會這樣出現:sUserName='張三',如果sUserName的值為null,要想找出所有名字為null的記錄時,不能這樣用:sUserName=null,因為null不是一個具體的值,任何值與它比較時都會返回false.此時可借用is null 或者是is not null.
示例查詢:
1:select * from testNull where a=null --返回空結果集
2:select * from testNull where b is null --返回結果集 2 2 NULL
結論:說明null是不能用"="來比較,可用is null來替換
3:在用統計函數count時會不同,例如count(ID):統計記錄數.當統計的記錄中的包含有null值時,它會忽略null值.
示例查詢:
1:select count(*),count(b) from testNull 它的返回值為2 1
2: select count(*),count(isnull(b,'')) from testNull 它的返回值為2 2
結論:對於列包含null 時,統計行數是可用count(*),或者是先把null值轉換成對應的值再統計,例如count(isnull(b,''));
4:對於in 的影響不同.
示例查詢: 查詢testNull表中b的值包含在null中的記錄.
select * from testNull
where b in(null) --沒有任何記錄
結論:in在查詢時會忽略null的記錄,查詢的時候可用is not null來查詢.
5:排序時順序有不同:當使用ORDER BY時,首先呈現NULL值。如果你用DESC以降序排序,NULL值最後顯示。
1:select * from testNull
1 1 ''
2 2 NULL
2:select * from testNull order by b
2 2 NULL
1 1 ''
3:select * from testNull order by b desc
1 1 ''
2 2 NULL
6:當使用GROUP BY時,所有的NULL值被認為是相等的。這時先多插入幾條數據,方便查看結果.
insert into testNull
values('3',null)
values('4','4')
select * from testNull
select count(b) from testNull
group by b
返回結果:
0 1 1
結論:可見在group by 的時候,null視為等同.
7:永遠不會有什麼數據等於NULL。1不等於NULL,2也一樣。但NULL也不等於NULL。所以我們只能比較它“是”或“不是”。
總結:SQL中提供了如此眾多的存儲過程,函數供我們調用,而我們又真正的理解幾個呢?只有真正了解它們,才會對開發中出現的種種問題迅速找出問題所在並解決它.
表聯接查詢
為了說明問題,我創建了兩個表,分別是學生信息表(student),班級表(classInfo).相關字段說明本人以SQL創建腳本說明:
測試環境:SQL2005
CREATE TABLE [dbo].[student](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sUserName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,--姓名
[sAddress] [varchar](200) COLLATE Chinese_PRC_CI_AS NULL,--地址
[classID] [int] NULL,--班級
[create_date] [datetime] NULL CONSTRAINT [DF_student_create_date] DEFAULT (getdate())--入班時間
) ON [PRIMARY]
學生表記錄:插入數據999999行.可以說的上是一個不大不小的表.
CREATE TABLE [dbo].[classInfo](
[classID] [int] IDENTITY(1,1) NOT NULL,--所屬班級ID
[sClassName] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL,--班級名稱
[sInformation] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL,--班級相關信息
[sDescription] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL,--班級描述
[iSchooling] [int] NULL,--學費
CONSTRAINT [PK_classInfo] PRIMARY KEY CLUSTERED
(
[classID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
班級表:共插入100行,實際可能不存在這麼多的班級.
示例需求:查詢學生的基本信息以及所屬班級名稱,我們都會第一時間想到用表關聯,這裡我列出相關實現方法.
第一:將數據量較大的學生表放在前面.
--大表在前
select top 1000 a.sUserName,b.sClassName from student a
inner join classInfo b on
a.classID=b.classID
第二:將數據量較小的班級表放在前面.
--小表在前
select top 1000 a.sUserName,b.sClassName from classInfo b
inner join student a on
a.classID=b.classID
第三:用where 實現.
--join與where
select top 1000 a.sUserName,b.sClassName from classInfo b, student a
where a.classID=b.classID
歸納:以上三種方式查詢的結果都完全相同,但它們在實現效率上會有不同嗎?這裡首先提出兩個網絡上的觀點:
網絡觀點一:一般要使得數據庫查詢語句性能好點遵循一下原則:在做表與表的連接查詢時,大表在前,小表在後.
執行計劃效果如圖一:

網絡觀點一結論:從圖上可以非常清楚的看出,三者在執行計劃上完成一樣.為此本人並不同意網絡觀點一.表在前與後並不影響最終的執行效率.大家有什麼不同的意見望指教.
說明:
1:WHERE子句中使用的連接語句,在數據庫語言中,被稱為隱性連接。INNER JOIN稱為顯性連接。WHERE 和INNER JOIN產生的連接關系,沒有本質區別,結果也一樣。但是!隱性連接隨著數據庫語言的規范和發展,已經逐漸被淘汰,比較新的數據庫語言基本上已經拋棄了隱性連接,全部采用顯性連接了。
2:join的分類:
1> inner join:理解為“有效連接”,
2>left join:理解為“有左顯示”,
3> right join:理解為“有右顯示”
4> full join:理解為“全連接”
3 .join可以分主次表 左聯是以左邊的表為主,右邊的為輔,右聯則相反
網絡觀點二:inner join 與 where 在效率上是否一樣?原文地址: http://topic.csdn.Net/t/20050520/13/4022440.Html 原文中有下面一段話:
---------------------------引用----------------------------------------------
4 指明多表關系會大大提高速度 ,如
SELECT A.X,B.Y FROM A B WHERE A.X=B.X
SELECT A.X,B.Y FROM A INNER JOIN B ON A.X=B.X
2句結果一樣,但是速度相差很多,時間復雜度分別是 O(2n)和O(n*n)
------------------------------------------------------------------------------
我的觀點:聯接查詢的時間復雜度並不是固定的,更不能說是由兩種表現方式不同而決定的.join在查詢的算法根據聯接表的不同分三種情況:
第一種算法:NESTED LOOP:
定義: 對於被連接的數據子集較小的情況,嵌套循環連接是個較好的選擇。在嵌套循環中,內表被外表驅動,外表返回的每一行都要在內表中檢索找到與它匹配的行,因此整個查詢返回的結果集不能太大(大於1 萬不適合),要把返回子集較小表的作為外表。
示例:上面有了一個班級表,下面我再創建一個班級課程表,
CREATE TABLE [dbo].[course](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,--課程名稱
[classID] [int] NULL,--所屬班級ID
CONSTRAINT [PK_CKH] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
業務需求:查詢所有班級對應的課程情況.
select sCourseName,sClassName from classInfo a
inner join course b
on a.classID=b.classID
執行計劃效果圖:
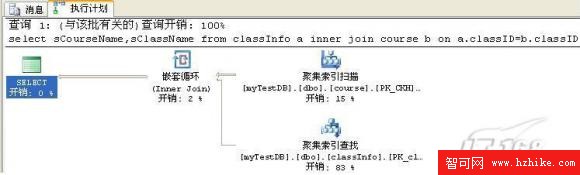
結論:通過查詢執行計劃可以非常清楚的看出,采用了嵌套查詢,因為兩表的數據量都不大,而且數據大小相當.此時的查詢開銷為n*n
第二種算法:HASH JOIN :
定義: 散列連接是做大數據集連接時的常用方式,優化器使用兩個表中較小的表(或數據源)利用連接鍵在內存中建立散列表,然後掃描較大的表並探測散列表,找出與散列表匹配的行。這種方式適用於較小的表完全可以放於內存中的情況,這樣總成本就是訪問兩個表的成本之和。但是在表很大的情況下並不能完全放入內存,這時優化器會將它分割成若干不同的分區,不能放入內存的部分就把該分區寫入磁盤的臨時段,此時要有較大的臨時段從而盡量提高I/O 的性能。
結論:從圖一中可能看出SQL在聯接班級表和學生表是采用了hash join方式,因為班級表數據量大,班級表數據量小.這種方式的查詢時間復雜度為2n.
注意點:hash join可能非常容易的變成nested loop,下面的查詢為hash join
select top 10000 a.ID,a.sUserName,b.sClassName from classInfo b
inner join student a on
a.classID=b.classID
轉換(hash join變nesteed loop):如果在後面組加上排序呢?此是會變成嵌套查詢
select top 10000 a.ID,a.sUserName,b.sClassName from classInfo b
inner join student a on
a.classID=b.classID
order by a.ID
轉換(nesteed loop變hash join):上面的嵌套查詢又可以改選成hash join
select * from(
select top 10000 a.ID,a.sUserName,b.sClassName from classInfo b
inner join student a on
a.classID=b.classID) as tbl
order by ID
第三種算法:排序合並連接
定義:通常情況下散列連接的效果都比排序合並連接要好,然而如果行源已經被排過序,在執行排序合並連接時不需要再排序了,這時排序合並連接的性能會優於散列連接。
網絡觀點二結論:inner join和where 在查詢效率上沒有區別,只是體現形式不同而已.
總結:我們可以通過查看SQL的執行計劃來分析SQL的性能,一句話正確與否不在於說話的人,而在於實踐驗證結果.本人就表聯接談了自己的理解,如果有不對的地方還望各們指教.