索引
VLDB (超大型數據庫)的管理和性能挑戰
ASE15中的數據分區(Partition)
為何使用數據分區?
數據可用性
使用數據分區提高查詢功能
有效的並行查詢處理
如何恰當地使用數據分區
結論
VLDB(超大型數據庫)的管理和性能挑戰
數據庫的容量正在迅速擴充,我們可以想象得出這種增長速度。與此同時,業務需要更多的數據來進行決策支持和分析。這兩個因素促成了VLDB (超大型數據庫,very large databases)的發展。
什麼是VLDB?即使針對同一個數據庫,對於一個企業來說可能是VLDB,但對於另外一個企業來說可能只是一個普通的數據庫。所以定義VLDB最好不要僅看它的容量,還要看在它的運行環境中將要面臨哪些挑戰。
首先,VLDB的維護和管理任務很難在制定安排的時間內完成。這會影響應用的性能和數據可用性。
其次,VLDB處理查詢操作時,將會耗費大量的時間和資源來獲取所需的數據,這將影響查詢的性能。一個需要遍歷整張表或索引的查詢將使性能降低到無法容忍的地步。這對於決策支持系統(DSS),如數據倉庫系統是嚴峻的考驗。那些DSS和OLTP並存的ODSS環境就更困難了。
第三,VLDB將影響在ASE上的運行應用的成本和開銷。
為了解決這些VLDB面臨的挑戰,ASE15的數據分區(Partition)功能將有效地減少管理所需的時間並提高應用的性能。數據分區功能將有助於滿足任何容量的ASE數據庫在管理、維護和性能上的要求。
ASE15中的數據分區?
數據分區可以將大的表或者索引分割成小的數據片,並存放在不同的存儲單元中。數據庫管理員可以在底層處理數據的存儲、維護和管理工作。
“segment(段)”在ASE中被定義為設備的單元。它常常被用來存儲特定類型數據,例如:系統數據、日志數據和用戶數據。分區可以存貯在不同的段上或者不同的分區存儲在同一個段上。類似的,一個或多個段可以存放在任何的邏輯或物理設備上,這樣可以分離I/O來提高性能和數據的可用性。
在一個分區上的表或索引數據可以以不同於其他分區的方式來管理和操作。查詢只須訪問那些包含所需數據的分區。
數據庫管理員可以更快捷地管理和維護這些較小的分區,而不是像以前那樣不得不面對巨型的表和索引。一些日常的任務甚至可以在多個分區上並行地執行,這不但可以節省時間,還可以在分區上自動運行。當數據增長時,只需添加新的分區即可。
在ASE15中提供了四種數據分區的方式,我們會在後面一一介紹並詳細討論。第一種方式稱之為round-robin分區,是在ASE15之前版本中唯一提供的分區方式。這種方式是在分區上順序排列數據,沒有辦法決定數據在分區上的存儲位置,並且查詢操作會涉及所有的分區。
其他的三種分區方式稱之為“語義數據分區”方式,因為可以通過這些方式確定數據的分區存放位置。
在ASE15中將被廣泛使用的方式是范圍分區(Range Partitioning)方式。利用這種分區方式,數據庫管理員可以通過數據的范圍確定數據在分區上的存儲位置。
下一種方式是列表分區(List Partitioning)方式,可以將不同的數據分割存放在不同的分區上。
第三種語義分區方式是哈希分區(Hash Partitioning)方式。在這種方式下數據是根據特定的列和內部哈希運算法則來確定數據的存放方式。
為何使用數據分區?
通過ASE15中的數據分區技術,企業可以降低ASE的維護和使用成本,無論它是大是小。而且它還可以提高運行在ASE之上的應用的性能,以及數據的可用性。
利用數據分區技術降低管理和維護數據庫的開銷
對於數據庫管理員來說,最耗費時間和精力的事情莫過於管理和維護不同大小數據庫。數據庫有可能會膨脹到沒有充足的時間運行所有必要的維護工作,比如無法完成完整的備份。這將會置數據於不安全的狀態中,而且還會直接對應用產生影響。
ASE15的數據分區可以更加高效地使用各種功能,這意味著DBA用更少的時間和資源維護和管理大型數據庫。
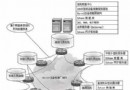
 圖1
圖1
上面的圖表顯示了在表上發生的一系列操作,包括一個正在運行的復雜的DSS類型查詢操作、一個OLTP進程、同時BCP進程正在加載數據、以及一個統計更新操作來更新統計值。在左面的未分區的表中,正在運行的操作將足以使正常的業務操作緩慢到無法接受的地步甚至是停頓下來。而在右邊的表,數據已經被分區,每個操作都運行在不同的分區上,它們之間互不影響。
通過將表和索引分割成較小的數據片,數據庫管理員可以在分區級別運行操作。這將加快操作運行的速度,使得運行在其它分區上的其它應用工作得更高效。這樣也可以保證應用能訪問到表中的所有數據。通過利用ASE15中的數據分區技術,在VLDB環境中應用運行的可擴展性得以大大地提高。
通過對表和索引執行分區操作,數據庫管理員可以事先規劃維護任務並且對分區進行循環操作,或者在多分區上並行執行任務。如果在某一時間,在給定的分區上無法進行維護操作,那麼可以跳過這個分區,稍後再回到這個分區繼續執行操作。維護任務表同時可以和ASE的Job Scheduler功能配合使用,這樣可以讓數據庫管理員有更多的時間處理其他重要的操作。
兩個最常用也是最耗資源和時間的操作是——update statistics 和 reorg 操作。這兩個操作都需要定期在表和索引上運行,這樣才能確保查詢操作的性能。
update statistics操作收集表、索引和列數據分布的信息。這些數據將被查詢處理引擎用來確定訪問所需數據的最優途徑。reorg rebuild 操作負責收集表和索引中的剩余空間。這個操作對於空間管理和提高查詢性能是非常重要的。有些表的膨脹速度非常快,以至於如果要想在計劃的時間內執行完這兩種重要的操作,就必須要停止正常的業務操作。
例如,許多數據庫中都有date/time 列用於記錄交易發生的時間。時刻保持這些列的分布統計的有效性將確保查詢操作的高效率。但是對於一張未分區的表和索引進行update statistics操作時,整列的數據將被讀取。如果是一張巨型表,對其性能和數據可用性的影響無疑是巨大的。
在分區的表和索引上執行同樣的操作將大幅度減少對整體性能和數據可用性的影響到最低限度。這是因為只需要從保存最近date/time值的分區上收集統計數據即可。reorg亦是如此。當其運行在分區的表和索引上時,操作只會涉及指定的分區,而表中的其它數據和索引都可以被其它操作所訪問。
還有一個重要的但也需要很大時間開銷的操作是運行在表和索引上的診斷操作,例如:檢驗數據一致性的DBCC操作。在分區技術基礎上運行這些關鍵的診斷操作將極大地提高運行效率。
其它的對時間和資源要求較高的操作還有在表上執行存檔或刪除大量無用數據。BCP(批量拷貝程序)可以運行在單一的分區上,寫入或導出表中的數據,但不影響那些對該表其它數據訪問的應用,只有那些通過BCP操作導入或導出數據的分區會受到影響。有了分區,就可以更方便地管理那些過時的數據。BCP操作同樣也可以在不同的分區上並行地執行。
truncate table.. partition 命令用於執行大量的數據刪除。通常可以利用BCP或其它備份方式處理數據。以往截斷操作會花費大量的時間刪除表上的所有數據。然而現在,數據可以在單個分區上進行刪除。
數據可用性
應用數據的可用性對於任何業務都是至關重要的。如果應用無法獲得所需的數據,工作將無法進行下去。
正如我們前面所示,對表和索引進行分區是為了將它們分割成較小的數據片,這樣在任何數據片上的操作和其它數據片上的操作都互不相干,應用可以在更多的時間裡,訪問更多的數據。下面的圖顯示了索引分區的過程:
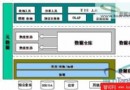
 圖2
圖2
Reorg操作在分區2上運行的時候,在分區3上正在更新統計數據。如果對於一個未分區的索引,任何一個這樣的操作都會獨占索引,而導致其它操作排隊等待。然而在分區後,兩個操作可以並行執行,同時在分區1上的數據還可以被其它應用訪問。
同樣的,如果操作更改了數據,索引僅僅會在一個分區上更新而不會影響其它的操作。
在ODSS環境中,數據庫管理員可以采用分區,使得OLTP操作在一個分區上運行,同時DSS操作在另外的分區上運行。由於分區使得數據的可用性得到提高,使用這些數據的應用的可靠性也得到了提高。
同時由於使用分區技術將數據存儲在不同的物理設備上,這也可以提高數據的可用性。如果一塊設備壞了,其他的分區還可以繼續被使用。
使用數據分區提高查詢功能
正如以上所述,數據分區不僅可以減少數據庫維護和管理任務的時間,更重要的是可以提高應用操作的性能。正像我們所見到的,將表或索引分割成較小的數據片可以大幅提高在這些數據片上的操作速度。
一個僅僅需要掃描部分表或索引的查詢會比遍歷整個數據庫對象的查詢快得多。尤其在針對大表Join查詢時更是如此。分區的表和索引會處理極少的關聯數據。
ASE 15的查詢處理引擎將不涉及未包含相關數據的分區。在下面的圖示中,一個查詢搜索cust_ptn字段中所有大於等於30000的行。因為該表已經基於范圍對cust_ptn列進行了分區,借助於前面提到過的“partition elimination”技術,只有分區2和3的數據將被讀取。這種處理顯著的提高ASE15性能。讀取更少的數據,查詢的速度就更快。
 圖3
圖3
如前所示,索引,就像表一樣,也可以被分區。對索引進行分區的好處不勝枚舉,您可以在下列情況下體會到這種好處:一,多個查詢要同時使用索引來訪問不同分區上的數據。二,當一個操作在一個分區上的索引上運行時,查詢還可以訪問那些在其它分區上該索引的其余部分。三,諸如更新、插入和刪除的操作可以改變索引值,這個寫操作將只會在由於數據改變而影響的那部分索引上執行。下面的圖示將幫您理解分區索引如何使您獲益。
 圖4
圖4
有兩種索引分區的方式——全局和本地索引。全局索引在一個分區中保存其整個結構。當在分區表上運行的查詢需要訪問全局索引的時候,可以讓指針從該表的索引上直接指向該表的數據分區。索引結構覆蓋了該表的所有數據分區。下面的圖表有助於了解全局索引是如何被規劃的。
 圖5
圖5
第二種索引是本地索引。該索引結構被分割成片並存儲在每一個分區中。因為分區的索引必須基於同一數據分區的列順序,本地索引有點類似於指向相關數據分區的較小的獨立索引。如果查詢僅僅訪問表中的一部分數據,那麼只需讀取本地索引。這將大大提高並發度因為這可以允許不同的查詢同時訪問同一索引的不同索引片。運行在一個數據分區上的查詢將不會影響訪問另一分區的查詢。其結果是減少了堵塞、I/O開銷,換來的是更高的性能和數據可用性。
 圖6
圖6
上面的圖示顯示了一個分區的表,包含一個分區的非聚簇索引。顯然在搜索所需數據時I/O操作將大為減少。當查詢中還包含有限制條件時,顯然會訪問更少的數據。在被分區的表(非“round-robin”分區)上的聚簇索引將是本地索引。
另一個益處是使用分區索引時,其大小取決於對應的表的分區上數據的行數。更小的索引會帶來更短的掃描時間。
有效的並行查詢處理
ASE15引進了新的並行查詢處理功能可以顯著提高查詢性能。結合了並行技術和分區技術的ASE15性能比以往有了大幅度的提高。
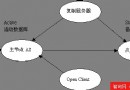
ASE15現在同時支持縱向和橫向並行機制。縱向並行技術可以同時利用多CPU處理查詢中的多個並行操作。橫向並行技術可以允許一個查詢的多個實例運行在位於不同分區或磁盤設備上的不同數據上。這就是分區如何幫助提高性能的體現。利用分區的表和索引,並行操作可以將同一查詢分割成查詢片(實例)並且可以同時運行在不同的分區上,為整個查詢操作收集所需的數據。下面這張圖顯示了查詢如何從垂直並行機制中受益。
 圖7
圖7
並行查詢操作和分區對於混合工作負載或ODSS環境是非常有效的,因為通常情況下都需要讀取大量的數據。當應用運行在這樣的環境中時,性能是關鍵,同時不能顧此失彼——操作之間相互堵塞。
如何恰當地使用數據分區
我們已經看到,ASE15的分區可以讓數據庫管理員更高效地執行必要的維護和管理任務,從而顯著降低VLDB在ASE上運行的成本。我們也同樣看到了分區技術如何極大地提高應用的性能,尤其是在ODSS環境中。
對表和索引進行分區非常簡單。表可以在創建時或者以後隨時進行更新。一旦分區後,寫入表中的數據將按照設定的分區規則寫盤,無論是插入、刪除還是BCP導入均不例外。索引同樣可以在創建時被分區,但一個已有的索引無法被分區。這需要刪除索引然後利用分區進行索引重建。
數據庫管理員可以在以下情況考慮使用前面提到過的三種語義分區方式:
范圍分區——數據庫管理員可以基於關鍵列中的數據范圍指定數據在各分區上的存儲位置。例如,數值1,2,3,4存儲在分區1中,而5,6,7,8存儲在分區2中,諸如此類。下面是利用范圍分區方式基於date/time 列創建表的語法示例:
create table customer (ord_date datetime not null,
name varchar(20) not null,
address varchar(40) not null, other columns …)
partition by range (ord_date)
(ord_date1 values <= (3/31/05) on segment1,
ord_date2 values <= (6/30/05) on segment2,
ord_date3 values <= (9/30/05) on segment3
ord_date4 values <= (12/31/05) on segment4)
范圍分區尤其對於那些持續更新、插入和刪除,且某些字段中包含連續數據,例如用戶號或訂單/交易日期的表尤為有效。這樣的表需要數據庫管理員額外的維護和管理。這類表常用於決策支持系統,最適合使用范圍分區。當交易僅僅發生在一個分區上的時候,數據庫管理操作和DSS查詢還可以訪問其它分區。與此同時,數據庫管理員必須保證交易活動的分區的分布統計值時刻更新,這樣查詢處理引擎就可以使用新的數據,這一點是非常重要的。正像我們所見的,當操作僅僅運行在一個單一分區上時,更新統計的時間是非常短的。
列表分區—— 列表分區類似於范圍分區,但這裡實際被寫入分區的數據是確定的。前文中的例子就是在包含有全球各地區數據的“地區”關鍵字段上建立列表分區。該列數據有沒有排序,以及數據在分區上存儲的順序,都不影響列表分區存儲數據。下面是利用列表分區方式創建表的語法示例:
create table nation (nationkey integer not null,name char(25) not null,
regionkey varchar(30) not null,comment varchar(152) not null)
on segment 1
partition by list (n_regionkey)
(region1 values ('Americas'),
region2 values ('Asia'),
region3 values ('Europe'),
region4 values ('Australia', 'Other') )
哈希分區——這種數據分區方式是根據在指定列上利用內部哈希算法計算的結果來決定數據存儲到哪一個分區。這裡不需要指定列表或數值的范圍。如果列鍵包含唯一數據,或者數據重復度極小,哈希分區將在其所有分區上平衡數據存儲。然而,如果有大量重復數值,分區將會“傾斜”,一些分區上的數據可能會比其它分區多。
哈希分區在要為大表建立很多分區,或者關鍵列中的數據沒有排序的情況下尤為有用。它同時還可以配合查詢處理引擎使得查詢工作更為有效。
create table lineitem ( l_orderkey integer not null, l_partkey integer not null,
l_suppkey integer not null, l_linenumber integer not null, l_quantity double not
null, l_extendedprice double not null, other columns …)
partition by hash (l_orderkey, l_linenumber)
(litem_hash1 on segment1,
litem_hash2 on segment2,
litem_hash3 on segment3,
litem_hash4 on segment4 )
結論
作為ASE15一系列新特性中最受人矚目的焦點,數據分區使得VLDB的管理和維護工作更加簡易,同時顯著提高了ASE的性能。更簡單而有效的維護和管理降低了在ASE上運行VLDB的成本,同時在混合工作負載環境中的應用性能也得到了極大提升。