網絡新聞觀點挖掘系統事實上本質是屬於文本數據挖掘范疇的,對於文本挖掘的方式,在早期主要是基於Web文本挖掘領域的。當然這個挖掘的尺度是可以控制的,粗粒度的挖掘相對於細粒度的挖掘要簡單不少,粗粒度挖掘可以快速的多數網民們對某新聞的觀點傾向,這也是我畢設作品所需要達到的目標。
平時做了許多挖掘算法的研究,一直懶得去做一些能智能分析化的工具,恰好這次可以利用畢業設計的機會,做一個觀點挖掘分析系統。系統設計的目標就是能對一則特定的新聞,通過利用千條評論數據,挖掘出其中的觀點傾向分類,提供給人們信息參考。
系統主要模塊分為4大模塊,下面是主要的模塊組成:
字典庫是利用已經收集好的一個多達2w余條記錄的txt文件,這個是比較簡單的,但是數據源的獲取就需要經過一些步驟,利用了之前我介紹過的QQ爬蟲工具,詳情點擊這裡,爬取的數據就是某條新聞頁的部分評論數據。QQ評論數據爬蟲的原理就是先去獲取一個新聞詳情頁的HTML代碼,做正則匹配,獲得其中的cmt_id評論id,然後再發送另外一個請求url取獲取真正的評論數據,在此次系統設計中,每次最多只能爬取50條數據,爬取總量為1000條,但是時間消耗會略久,30s左右。
在實現本次挖掘系統中同樣需要有文本預處理的操作,但是文本預處理不會做的那麼細,只是會粗糙的過濾一些數字詞,連接符,以及一些無效詞,比如像"的"這樣的詞語,這些詞的過濾可以減少後面暴力匹配的次數,預處理完畢之後,以標點符號作為分隔符,進行觀點子句分割存入一個新的list。
這個模塊是挖掘系統的核心模塊,分為2個子步驟,1個步驟是識別,識別是通過裡面的子句中的詞語與字典庫中的觀點詞去進行暴力匹配,性能上會比較糟糕,但是效果還行,匹配的原理類似於a字符串完全包含b字符串的比較原理,這裡面的運算級別已經達到千萬級別了。判別出每個觀點詞之後,會進行詞性的標記,每段觀點的極性等於其中的各個子句的觀點極性的和,而子句中的觀點等於內部中出現的所有觀點詞的極性和。
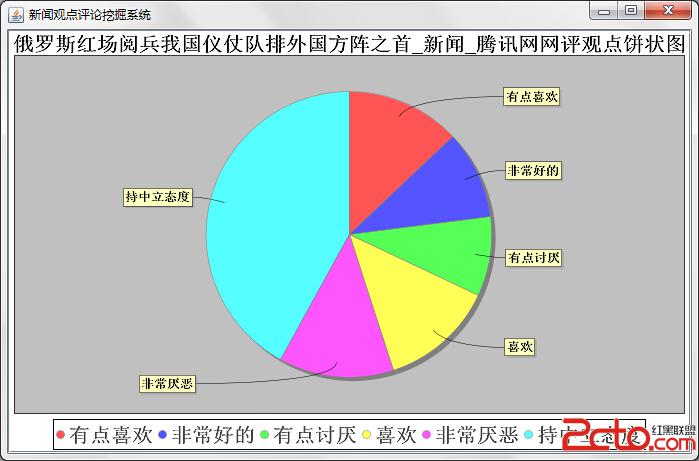
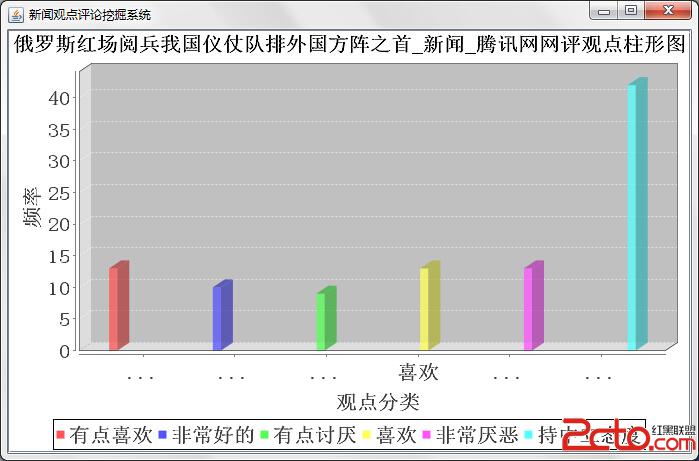
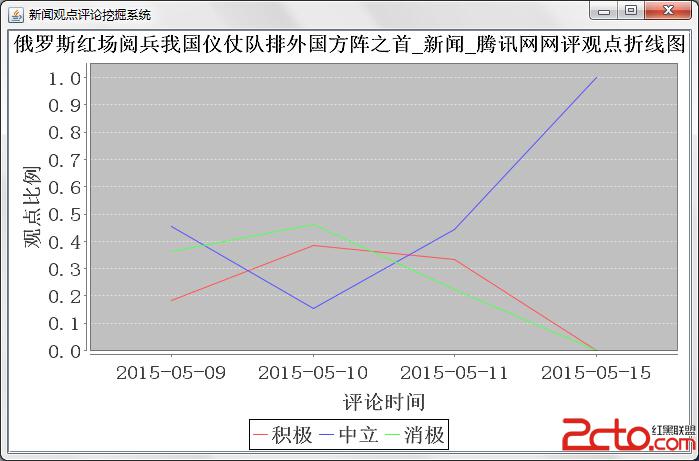
終端結果展示需要利用上個模塊中分析出的觀點極性列表,分析的結果用到了jfreeChart 圖表工具包,我利用了其中的柱形圖,餅圖圖和折線圖,前2個圖的功能類似,折線圖可以用來提取出其中的觀點傾向分類走勢。餅狀圖和柱形圖中的分類分為了7大類,消極觀點弱中強,中立,積極觀點弱中強。折線圖的分類就稍微簡單一點,為消極,中立,積極的觀點。
下面是效果圖的展現,具體代碼請點擊我的項目地址opition-mining-system.
系統主界面入口:
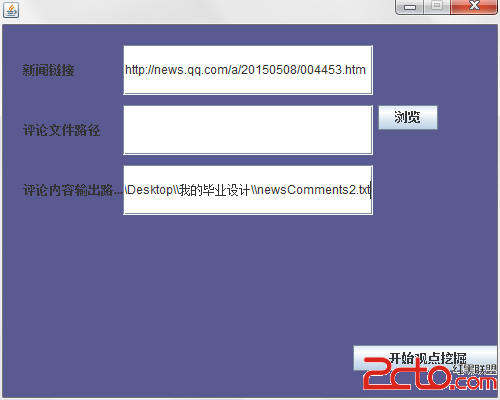
填入騰訊新聞鏈接地址,評論數據輸出地址可以不填,默認輸出到D盤中,點擊開始挖掘,會停頓一段時間,因為這裡我犯了一個錯誤,在ui主線程中調用了網絡請求,造成假死狀態。

然後是功能頁,具體的作用就是上面的按鈕文字所描述的意思。點擊進去各個具體頁面如下: