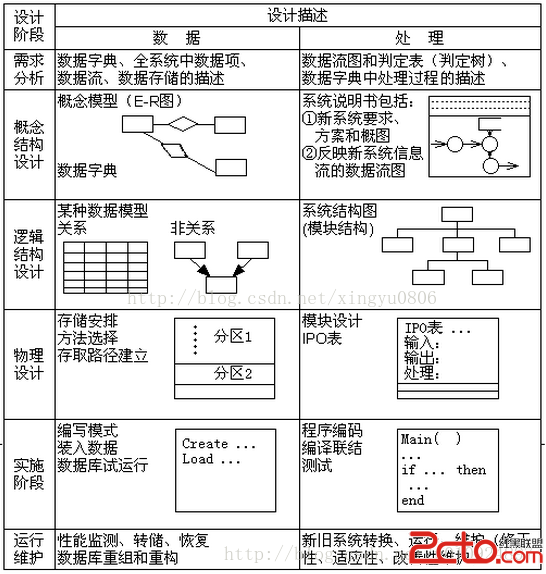
主要討論順序表、有序表、索引表和哈希表查找的各種實現方法,以及相應查找方法在等概率情況下的平均查找長度。
查找表(Search Table):相同類型的數據元素(對象)組成的集合,每個元素通常由若干數據項構成。 關鍵字(Key,碼):數據元素中某個(或幾個)數據項的值,它可以標識一個數據元素。若關鍵字能唯一標識一個數據元素,則關鍵字稱為主關鍵字(Primary Key) ;將能標識若干個數據元素的關鍵字稱為次關鍵字(Secondary Key) 。 查找/檢索(Searching):根據給定的K值,在查找表中確定一個關鍵字等於給定值的記錄或數據元素。
◆ 查找表中存在滿足條件的記錄:查找成功;結果:所查到的記錄信息或記錄在查找表中的位置。
◆ 查找表中不存在滿足條件的記錄:查找失敗。
根據查找表的操作方式,分為靜態查找表和動態查找表。
靜態查找表(Static Search): 只對查找表進行如下操作:
(1)查看某個特定的數據元素是否在查找表中,
(2)檢索某個特定元素和各種屬性。
動態查找表(Dynamic Search):在查找過程中,可進行如下操作:
(1)可以將查找表中不存在的數據元素插入,
(2)從查找表中刪除已存在的某個記錄。
為了提高查找的效率,除了應用好的查找算法外,也會為查找設立專門的數據結構來存儲數據,比如表、樹等等。
查找表的存儲結構:
查找表是一種非常靈活的數據結構,可以用多種方式來存儲。
根據存儲結構的不同,查找方法可分為三大類:
① 順序表和鏈表的查找:將給定的K值與查找表中記錄的關鍵字進行比較, 找到要查找的記錄;
② 散列表的查找:根據給定的K值直接訪問查找表, 從而找到要查找的記錄;
③ 索引查找表的查找:首先根據索引確定待查找記錄所在的塊 ,然後再從塊中找到要查找的記錄。
一般地,認為記錄的關鍵字是一些可以進行比較運算的類型,如整型、字符型、實型等,本章以後各節中討論所涉及的關鍵字、數據元素等的類型描述如下:
典型的關鍵字類型說明是:
typedef float KeyType ; /* 實型 */
typedef int KeyType ; /* 整型 */
typedef char KeyType ; /* 字符型 */
數據元素類型的定義是:
typedef struct RecType
{ KeyType key ; /* 關鍵字碼 */
┇ /* 其他域 */
}RecType ;
靜態查找表的抽象數據類型定義如下:
ADT Static_SearchTable{
數據對象D:D是具有相同特性的數據元素的集合,
各個數據元素有唯一標識的關鍵字。
數據關系R:數據元素同屬於一個集合。
基本操作P:
Create
Destroy
Search
Traverse
} ADT Static_SearchTable
線性表是查找表最簡單的一種組織方式,本節介紹幾種主要的關於線性表的查找方法。
適用場合:針對查找表中的元素沒有按關鍵字進行排序(即無序線性表)
1 查找思想
從表的一端(第一個或 最後一個)開始逐個將記錄的關鍵字和給定K值進行比較,若某個記錄的關鍵字和給定K值相等,查找成功;否則,若掃描完整個表,仍然沒有找到相應的記錄,則查找失敗。順序表的類型定義如下:
#define MAX_SIZE 100
typedef struct SSTable
{ RecType elem[MAX_SIZE] ; /* 順序表 */
int length ; /* 實際元素個數 */
}SSTable ;int Seq_Search ( SSTable ST , KeyType key)
{ int i ;
ST. elem[0].key=key ; /* 設置監視哨兵,失敗返回0 */
for (i=ST.length; i>=1;i--)
if (ST. elem[i].key==key)
return i;
return 0;
}
前提條件:查找表中的所有記錄是按關鍵字有序(升序或降序) 。
查找過程中,先確定待查找記錄在表中的范圍,然後逐步縮小范圍(每次將待查記錄所在區間縮小一半),直到找到或找不到記錄為止。
1 查找思想
用Low、High和Mid表示待查找區間的下界、上界和中間位置指針,初值為Low=1,High=n。
⑴ 取中間位置Mid:Mid=?(Low+High)/2? ;
⑵ 比較中間位置記錄的關鍵字與給定的K值:
① 相等: 查找成功;
② 大於:待查記錄在區間的前半段,修改上界指針: High=Mid-1,轉⑴ ;
③ 小於:待查記錄在區間的後半段,修改下界指針:Low=Mid+1,轉⑴ ;
直到越界(Low>High),查找失敗。
2 算法實現
int Bin_Search(SSTable ST , KeyType key)
{ int Low=1,High=ST.length, Mid ;
while (Low<High)
{ Mid=(Low+High)/2 ;
if (ST. elem[Mid].key== key))
return(Mid) ;
else if (ST. elem[Mid].key<key))
Low=Mid+1 ;
else High=Mid-1 ;
}
return(0) ; /* 查找失敗 */
}
Fibonacci查找方法是根據Fibonacci數列的特點對查找表進行分割。Fibonacci數列的定義是:
F(0)=0,F(1)=1,F(j)=F(j-1)+F(j-2) 。
若共有20(F(8)-1)個數, j=8,則mid= low+F(7)-1 =13
若key <a[13], 則low=1,high=12
下一步:j=7, mid= low+F(6)-1 =8
若key >a[13], 則low=14,high=20( F(8) -1)
下一步:j=6, mid=low+F(5)-1=18
1 查找思想
設查找表中的記錄數比某個Fibonacci數小1,即設n=F(j)-1。用Low、High和Mid表示待查找區間的下界、上界和分割位置,初值為Low=1,High=n。
⑴ 取分割位置Mid:Mid=low+F(j-1)-1;
⑵ 比較分割位置記錄的關鍵字與給定的K值:
① 相等: 查找成功;
② 大於:待查記錄在區間的前半段(區間長度為F(j-1)-1),修改上界指針: High=Mid-1,轉⑴ ;
③ 小於:待查記錄在區間的後半段(區間長度為F(j-2)-1),修改下界指針:Low=Mid+1,轉⑴ ;
直到越界(Low>High),查找失敗。
算法實現
在算法實現時,為了避免頻繁計算Fibonacci數,可用兩個變量f1和f2保存當前相鄰的兩個Fibonacci數,這樣在以後的計算中可以依次遞推計算出。
int fib(int n)
{ int i, f , f0=0 , f1=1 ;
if (n==0) return(0) ;
if (n==1) return(1) ;
for (i=2 ; i<=n ; i++ )
{ f=f0+f1 ; f0=f1 ; f1=f ; }
return(f) ;
}
int Fib_search(RecType ST[] , KeyType key , int n)
/* 在有序表ST中用Fibonacci方法查找關鍵字為key的記錄 */
{ int Low=1, High, Mid, f1, f2 ;
High=fib(n)-1 ; f1=fib(n-1) ; f2=fib(n-2) ;
while (Low<=High)
{ Mid=Low+f1-1;
if ( ST.[Mid].key==key ) return(Mid) ;
else if ( key<ST.[Mid].key) )
{ High=Mid-1 ; f2=f1-f2 ; f1=f1-f2 ; }
else
{ Low=Mid+1 ;f1=f1-f2 ; f2=f2-f1 ; }
}
return(0) ;
}
Fibonacci查找的時間復雜度也為O(logn)
平均性能,優於折半查找;但在最壞情況下性能比折半查找差。
折半查找需進行加法和除法運算;但Fibonacci查找只需進行加、減運算。
分塊查找(Blocking Search)又稱索引順序查找,是前面兩種查找方法的綜合。
1 查找表的組織
① 將查找表分成幾塊。塊間有序,即第i+1塊的所有記錄關鍵字均大於(或小於)第i塊記錄關鍵字;塊內無序。
② 在查找表的基礎上附加一個索引表,索引表是按關鍵字有序的,索引表中記錄的構成是
應用
分塊索引兼顧了對細分塊不需要有序的情況下,大大增加了整體查找速度,普遍應用於數據庫表查找技術中。
算法實現
typedef struct IndexType
{ keyType maxkey ; /* 塊中最大的關鍵字 */
int startpos ; /* 塊的起始位置 */
}Index;
int Block_search(RecType ST[] , Index ind[] , KeyType key , int n , int b)
/* 在分塊索引表中查找關鍵字為key的記錄 */
/*表長為n ,塊數為b */
{ int i=0 , j , k ;
while ((i<b)&<(ind[i].maxkey, key) ) i++ ;
if (i>b) { printf("\nNot found"); return(0); }
j=ind[i].startpos ;
while ((j<n)&&LQ(ST[j].key, ind[i].maxkey) )
{ if ( EQ(ST[j].key, key) ) break ;
j++ ;
} /* 在塊內查找 */
if (j>n||!EQ(ST[j].key, key) )
{ j=0; printf("\nNot found"); }
return(j);
}