中文分句,乍一看是一個挺簡單的工作,一般我們只要找到一個【。!?】這類的典型斷句符斷開就可以了嗎。
對於簡單的文本這個做法是已經可行了(比如我看到這篇文章裡有個簡潔的實現方法
自然語言處理學習3:中文分句re.split(),jieba分詞和詞頻統計FreqDist_zhuzuwei的博客-CSDN博客_jieba 分句
NLTK使用筆記,NLTK是常用的Python自然語言處理庫
然而當我處理小說文本時,發現了這種思路的漏洞:
今天上午,我去“秘密基地”了。
所以,這裡我提供一個更加精細的解決方法,可以解決上面的問題:
# 版本為python3,如果為python2需要在字符串前面加上u
import re
def cut_sent(para):
para = re.sub('([。!?\?])([^”’])', r"\1\n\2", para) # 單字符斷句符
para = re.sub('(\.{6})([^”’])', r"\1\n\2", para) # 英文省略號
para = re.sub('(\…{2})([^”’])', r"\1\n\2", para) # 中文省略號
para = re.sub('([。!?\?][”’])([^,。!?\?])', r'\1\n\2', para)
# 如果雙引號前有終止符,那麼雙引號才是句子的終點,把分句符\n放到雙引號後,注意前面的幾句都小心保留了雙引號
para = para.rstrip() # 段尾如果有多余的\n就去掉它
# 很多規則中會考慮分號;,但是這裡我把它忽略不計,破折號、英文雙引號等同樣忽略,需要的再做些簡單調整即可。
return para.split("\n")
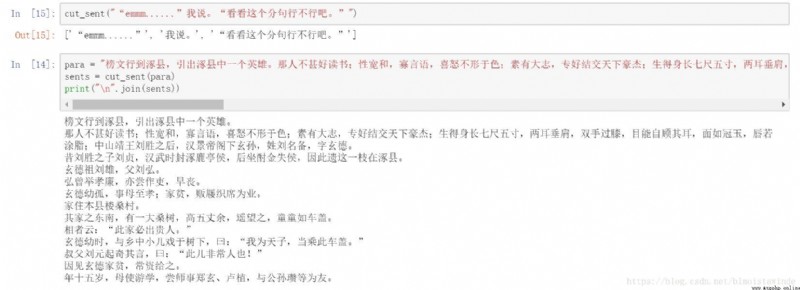
檢驗效果
HarvestText是一個專注無(弱)監督方法,能夠整合領域知識(如類型,別名)對特定領域文本進行簡單高效地處理和分析的庫。適用於許多文本預處理和初步探索性分析任務,在小說分析,網絡文本,專業文獻等領域都有潛在應用價值。
處理數據時,除了分句可能還要先清洗特殊的數據格式,
如微博,HTML代碼,URL,Email等,
某大佬!將一批常用的數據預處理和清洗操作都整合進了開發的HarvestText庫
github(https://github.com/blmoistawinde/HarvestText)
碼雲:https://gitee.com/dingding962285595/HarvestText
使用文檔:Welcome to HarvestText’s documentation! — HarvestText 0.8.1.7 documentation
print("各種清洗文本")
ht0 = HarvestText()
# 默認的設置可用於清洗微博文本
text1 = "回復@錢旭明QXM:[嘻嘻][嘻嘻] //@錢旭明QXM:楊大哥[good][good]"
print("清洗微博【@和表情符等】")
print("原:", text1)
print("清洗後:", ht0.clean_text(text1))
# URL的清理
text1 = "【#趙薇#:正籌備下一部電影 但不是青春片....http://t.cn/8FLopdQ"
print("清洗網址URL")
print("原:", text1)
print("清洗後:", ht0.clean_text(text1, remove_url=True))
# 清洗郵箱
text1 = "我的郵箱是[email protected],歡迎聯系"
print("清洗郵箱")
print("原:", text1)
print("清洗後:", ht0.clean_text(text1, email=True))
# 處理URL轉義字符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print("URL轉正常字符")
print("原:", text1)
print("清洗後:", ht0.clean_text(text1, norm_url=True, remove_url=False))
text1 = "www.中文 and space.com"
print("正常字符轉URL[含有中文和空格的request需要注意]")
print("原:", text1)
print("清洗後:", ht0.clean_text(text1, to_url=True, remove_url=False))
# 處理HTML轉義字符
text1 = "<a c> ''"
print("HTML轉正常字符")
print("原:", text1)
print("清洗後:", ht0.clean_text(text1, norm_html=True))
# 繁體字轉簡體
text1 = "心碎誰買單"
print("繁體字轉簡體")
print("原:", text1)
print("清洗後:", ht0.clean_text(text1, t2s=True))結果
各種清洗文本
清洗微博【@和表情符等】
原: 回復@錢旭明QXM:[嘻嘻][嘻嘻] //@錢旭明QXM:楊大哥[good][good]
清洗後: 楊大哥
清洗網址URL
原: 【#趙薇#:正籌備下一部電影 但不是青春片....http://t.cn/8FLopdQ
清洗後: 【#趙薇#:正籌備下一部電影 但不是青春片....
清洗郵箱
原: 我的郵箱是[email protected],歡迎聯系
清洗後: 我的郵箱是,歡迎聯系
URL轉正常字符
原: www.%E4%B8%AD%E6%96%87%20and%20space.com
清洗後: www.中文 and space.com
正常字符轉URL[含有中文和空格的request需要注意]
原: www.中文 and space.com
清洗後: www.%E4%B8%AD%E6%96%87%20and%20space.com
HTML轉正常字符
原: <a c> ''
清洗後: <a c> ''
繁體字轉簡體
原: 心碎誰買單
清洗後: 心碎誰買單